ljn
Migrations
Migrating from Snowflake to ClickHouse: Step-by-Step Guide
Written by
Armend Avdijaj
-

Migrating from Snowflake to ClickHouse
The trade-off between cost and latency in cloud data warehousing is becoming a serious issue for many engineering teams. It's only natural for workloads to grow, and for user expectations for real-time feedback to increase; this, along with the lack of predictable pricing models of the past, are giving way to surprise bills and performance bottlenecks. This is precisely why, for teams building high-throughput, low-latency analytical applications, ClickHouse has presented itself as a very compelling alternative. It's open-source, built for speed, and a joy to use, so what's not to like?
This article presents a playbook introducing migration pipelines from Snowflake to ClickHouse. It provides clear, step-by-step examples covering common use cases, including everything from initial assessment and data extraction to performance optimization and the final cut-over.
So without further ado, let us start.
When (and Why) to Consider Migrating
The decision to migrate a data warehouse is never taken lightly, but it’s often forced by growing pains in cost, performance, and architecture and maintenance, among others. We can thus break down this into the following points:
Cost & Performance
Architectural & Control Factors
Strategic Alignment
Cost & Performance Pressures
Snowflake's pay-for-compute model works well until it doesn't. The moment your workload becomes spiky or your queries are user-facing, you're suddenly caught in a dilema:
To handle sudden query bursts, you can rely on auto-scaling, which burns through credits at an alarming rate.
To deliver low-latency dashboards, you're forced to keep a virtual warehouse running 24/7, paying for idle time just to avoid the multi-second "resume" delay.
ClickHouse sidesteps this entirely. Its shared-nothing architecture on local storage means there is no "wake-up" time. Queries are executed immediately against data on disk, making it structurally better suited for applications where every millisecond of latency impacts the user experience.
Architectural & Control Factors
The shift to an open-source tool like ClickHouse is often a deliberate move to reclaim engineering autonomy. On a managed platform, the underlying infrastructure and its optimizations are a black box. With ClickHouse, you get direct control over the machine. You can provision nodes with specific CPU-to-RAM ratios, choose high-throughput NVMe storage, and tune kernel settings. You have direct access to table engine parameters, letting you configure MergeTree settings for your exact workload, adjust merge behavior in the system tables, and pick your own compression codecs (LZ4 for speed, ZSTD for size). This level of control allows you to solve performance problems at the root, rather than just throwing more credits at them.
Strategic Alignment
Choosing ClickHouse is also a strategic decision to align your data infrastructure with your operational strengths. If your team is already skilled in managing Linux-based systems and deploying applications on Kubernetes, ClickHouse fits directly into your existing tooling and knowledge base. It’s not an isolated, proprietary system but a component that integrates cleanly with the open-source streaming ecosystem, connecting to sources like Apache Kafka and processors like GlassFlow without friction.
Key Differences Between Snowflake and ClickHouse
Before any data is moved, you have to internalize that Snowflake and ClickHouse are built on opposing design principles. This isn't just a syntax change; it's a paradigm shift. Every choice, from data layout on disk to query execution, is different, and understanding these differences is non-negotiable for a successful migration.
Storage & Compute Model: Decoupled cloud object storage vs. local disks & replicas
Data Layout: Micro-partitions vs. MergeTree parts & primary-key ordering
Indexing & Pruning: Metadata pruning vs. skip indexes, projections
Concurrency & Elasticity: Virtual warehouses vs. shard-based horizontal scaling
Security & Governance: Built-in RBAC & masking vs. self-managed policies
Below is a more comprehensive feature comparison matrix for both services:
Feature | Snowflake | ClickHouse |
|---|---|---|
Model | Decoupled Storage & Compute | Coupled Storage & Compute (Shared-Nothing) |
Primary Use Case | Enterprise Cloud Data Warehousing | Real-Time, High-Throughput Analytics |
Data Storage | Cloud Object Storage (S3, GCS, Azure Blob) | Local Disks (NVMe/SSD) or Object Storage |
Primary Index | Metadata on Micro-Partitions | Sparse Primary Index based on |
Concurrency | Elastic Virtual Warehouses | Horizontal Scaling via Sharding and Replication |
Data Types | Rich SQL types, first-class | Rich SQL types, requires explicit parsing of JSON |
Transactions | Multi-statement ACID transactions | Atomic |
Source Model | Closed-Source, Managed Service | Open-Source, Self-Hosted or Cloud-Managed |
Query Latency | Seconds to Minutes (includes warehouse spin-up) | Milliseconds to Seconds |
Cost Model | Credit-based (Compute + Storage) | Hardware/Instance-based (Compute + Storage) |
Figure 01: Feature-by-Feature Comparison Matrix
Migrating the Data
We can think of the migration itself as a five-step engineering project. Approaching it with this structure ensures that data is not only moved correctly but is also reshaped to take full advantage of ClickHouse's architecture from day one:
1. Inventory & Assessment
The first job is a thorough reconnaissance of your Snowflake environment. This means programmatically listing every database, schema, table, and especially any views or pipes that contain hidden logic. The two critical items to flag are reliance on Time Travel, which has no direct equivalent in ClickHouse and will require a new data modeling approach (like an event log table), and the use of VARIANT columns. Every VARIANT field must be analyzed to define an explicit, flattened schema in ClickHouse, as it does not have a native "schemaless" type.
2. Extract from Snowflake
The standard and most effective way to get bulk data out of Snowflake is via the COPY INTO @stage command, writing to an external cloud stage like S3 as Parquet files. Parquet is a good intermediary format because it's columnar, compressed, and universally understood. The extraction strategy typically involves a one-time, full-table unload for the historical data, followed by a separate, ongoing process to capture incremental updates that occur during the transition period. For the incremental updates, you can use an orchestrator like Airflow, dbt Cloud, or Prefect to schedule regular extracts, or implement a simple cron job that runs COPY INTO commands with appropriate date filters (such as WHERE updated_at > '2024-01-01') to capture only the newly added or modified records since the last extraction. The frequency of these incremental runs depends on your data freshness requirements and can range from hourly to daily intervals:
3. Transform for ClickHouse
This is the most critical stage for future performance. Data that is perfectly structured for Snowflake's micro-partitioning is not optimized for ClickHouse's MergeTree engine. The objective here is twofold: flatten any nested JSON data into a clean, columnar structure, and—most importantly—physically sort the Parquet files according to the columns that will form your ClickHouse table's ORDER BY key. If your table will be ORDER BY (event_date, user_id), your Parquet files must be sorted by event_date then user_id. This pre-sorting allows ClickHouse to perform a zero-copy-like ingestion, as the data is already in the order it needs to be on disk.
A Python script using libraries like pandas and pyarrow is a great tool for this job:
4. Load into ClickHouse
With properly prepared Parquet files, ingestion is refreshingly direct. You first define your target table in ClickHouse, ensuring the column types and ORDER BY clause exactly match the structure of your transformed data. Then, you use the s3 table function to execute a streaming INSERT...SELECT query that reads directly from your cloud storage bucket. This method is highly efficient and avoids moving data through an intermediate server.
5. Validate & Reconcile
Never assume a migration was perfect. Validation is a vital final step. You must programmatically verify data integrity between the source and the destination. You should run checksums or aggregate hashes (groupBitXor in ClickHouse) on numeric columns, compare min/max values on timestamps, and execute a suite of identical, business-critical aggregation queries on both systems to prove that the results are bit-for-bit identical.
Row Counts: Simple
COUNT(*)on both ends.Checksums: Run checksums or hashes on key columns to check for data integrity.
Sampled Queries: Run a few representative analytical queries on both systems and compare the results.

Diagram 01: End-to-End Batch Migration Flow
Optimizing for Performance
With the data migrated and validated, the focus now goes onto to getting the performance you came for. This requires moving beyond the defaults and making deliberate design choices tailored to your specific query patterns.
Table Design & Partitioning
The MergeTree engine variant and the ORDER BY clause are your most powerful tuning levers. For example, use ReplacingMergeTree if you need to handle late-arriving duplicates based on a unique key, or SummingMergeTree to have ClickHouse automatically roll up metrics during its background merge processes. The ORDER BY key is your primary index; it should be composed of the low-cardinality columns used most frequently in your queries' WHERE clauses (e.g., (event_type, region, toStartOfDay(timestamp))). The PARTITION BY clause is for coarse-grained data management, typically by month (toYYYYMM(timestamp)), which allows for extremely fast partition-level operations like DROP or DETACH for archiving.
Compression & Storage
Storage and compression choices directly impact I/O performance. The default LZ4 compression is fast, but ZSTD often yields significantly better compression ratios, which means less data to read from disk. You can apply column-level codecs to compress low-cardinality strings with one algorithm and high-cardinality numeric data with another. For hardware, nothing beats local NVMe SSDs for raw I/O throughput. For very large datasets, ClickHouse's tiered storage allows you to keep the most recent, "hot" partitions on NVMe while automatically moving older, "cold" partitions to cheaper object storage like S3.
Query Tuning
ClickHouse provides several powerful features to accelerate queries without changing the raw data. Projections are a key tool; they are essentially indexed and aggregated subsets of your data, managed by the table itself. If you frequently query SELECT page, count() GROUP BY page, creating a projection for that query will make it orders of magnitude faster. For columns with a small, fixed set of values (e.g., country codes, status enums), the LowCardinality data type creates a dictionary encoding that dramatically reduces the memory footprint and speeds up any GROUP BY or WHERE operations involving that column.
GlassFlow for Preprocessing: Sort, Deduplicate, Stream
The batch-oriented workflow is ideal for the initial historical data load, but it's not a solution for continuous, real-time ingestion. For live data from sources like Kafka, a dedicated stream processing layer is required. A tool like GlassFlow is built precisely for this purpose, acting as an intermediary that can consume a raw stream, apply stateful transformations like time-windowed deduplication, sort records for optimal ingestion, and then write clean, ordered batches into a ClickHouse sink. This automates the entire "transform and load" pipeline for live data.

Diagram 02: Real-Time Pipeline with GlassFlow
Monitoring & Maintenance
Once operational, you need visibility into the cluster's health, which is provided by the extensive system tables. You should actively monitor system.merges to understand the write amplification and compaction load on your cluster. The system.parts and system.columns tables give you a precise view of your data's physical storage, including the size and row count of each data part and the on-disk size of each column. This data is essential for diagnosing performance issues and tuning background task thresholds to match your workload.
Cut-Over Strategy
The final phase is the production cut-over. This must be a carefully planned operation to avoid any disruption to downstream applications. A gradual, controlled transition is always the best approach. This way you can isolate issues quickly and roll back if required.
A robust cut-over strategy involves implementing dual-writes, where your application logic sends new data to both Snowflake and ClickHouse simultaneously. This creates a parallel system for validation. You can then run "shadow queries" against ClickHouse, mirroring your production read traffic to compare results and benchmark performance under real-world load. Once you have full confidence, you can use a DNS or load balancer to begin routing a small percentage of live user traffic to the ClickHouse backend, gradually increasing the percentage until it handles 100% of the load. A well-documented rollback plan, detailing the exact steps to revert traffic to Snowflake, is a non-negotiable safety measure.
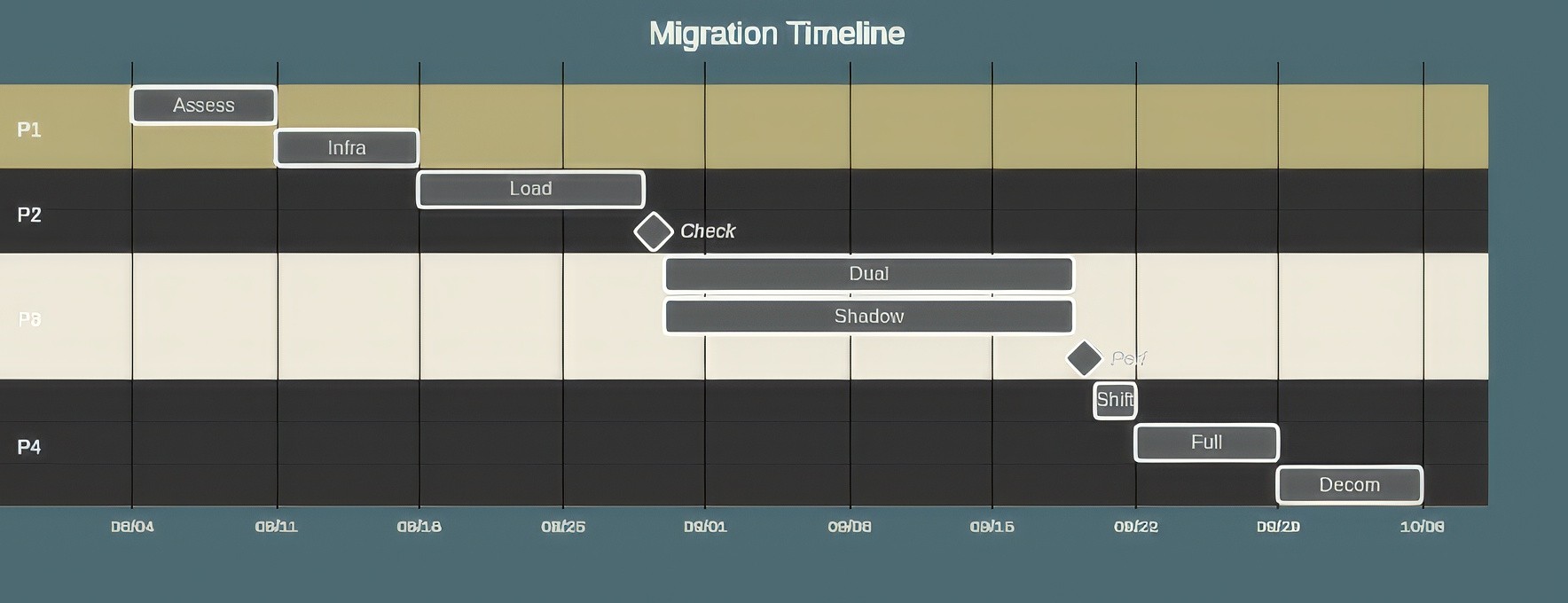
Diagram 03: Example Migration Timeline & Checkpoints
Adoption Stories
Looking for more practical examples? ClickHouse has a comprehensive documentation section where you can see which companies are adopting ClickHouse, which services they're migrating from, how they're performing these migrations, and why are they even adopting ClickHouse to begin with. We selected a subset of these success stories that are also well documented so you can check out how a successfull migration would be executed on real-world, productive environments:
Cloudflare: This is the canonical story. When you need to analyze millions of events per second and give users instant feedback, you don't use a general-purpose warehouse. Cloudflare's detailed account of building their analytics on ClickHouse is required reading and effectively wrote the playbook for high-throughput observability.
Sentry: When their search infrastructure started to buckle, Sentry re-architected their core search product, Snuba, on top of ClickHouse to solve their latency and scale issues at the root, bulletproofing the real-time error discovery feature their users depend on.
Vantage: Their migration story directly mirrors the pain points of cloud data warehouses. Bogged down by the cost and sluggishness of alternatives like Redshift and Postgres, Vantage moved to ClickHouse for the exact reasons outlined in this article: to regain control and deliver a faster, more cost-effective product.
Attentive: They titled their migration story "Confoundingly Fast" for a reason. For a marketing platform that relies on real-time segmentation and analytics, speed is an actual requirement. Their move to ClickHouse was a strategic decision that directly powered their product's capabilities.
Didi: To handle its firehose of petabyte-scale log data, Elasticsearch wasn't cutting it. The ride-sharing company migrated its entire log storage system to ClickHouse, documenting massive improvements in performance and a sharp reduction in operational costs.
Plausible Analytics: Plausible didn't migrate to ClickHouse; they built their entire business on it from day one. Their open-source, privacy-first analytics platform is living proof that you can build a lean, fast, and user-facing service without the exorbitant price tag of a traditional cloud data warehouse.
PostHog: Another adoption story, PostHog migrated from Postgres to ClickHouse to handle their growing analytics workload. They deployed ClickHouse in parallel and used feature flags to switch over queries one by one.
LangChain/LangSmith: Chose ClickHouse to power the observability features of LangSmith. LangSmith now stores run results in ClickHouse instead of Postgres to improve performance and scalability.
Tekion: Adopted ClickHouse Cloud for application performance and metrics monitoring after their previous search provider became expensive and difficult to maintain. The team noted that "ClickHouse has proved to be a game-changer, propelling us towards greater efficiency and effectiveness in managing our data infrastructure."
Final Thoughts
Migrating from Snowflake to ClickHouse can be a move toward a more performant, cost-effective, and controllable analytics stack, depending on your use case. A successful outcome is based off a deep understanding of the architectural differences and a methodical approach to the migration, with a particular focus on pre-sorting data to match your ClickHouse table design. Our recommendation is to start small. Pilot the migration on a single, well-understood workload. Use it as an opportunity to iterate on your schema design, tune your queries, and build operational confidence. And for new real-time pipelines, always consider tools like GlassFlow to manage the complexities of stream processing from the start. It will simplify your process and save you and your team a lot of headaches.
References
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
