ljn
Ingest your data
into ClickHouse from day one
Backfill historical data, keep CDC in sync, handle schema changes, normalize messy data, and keep ClickHouse queries correct.

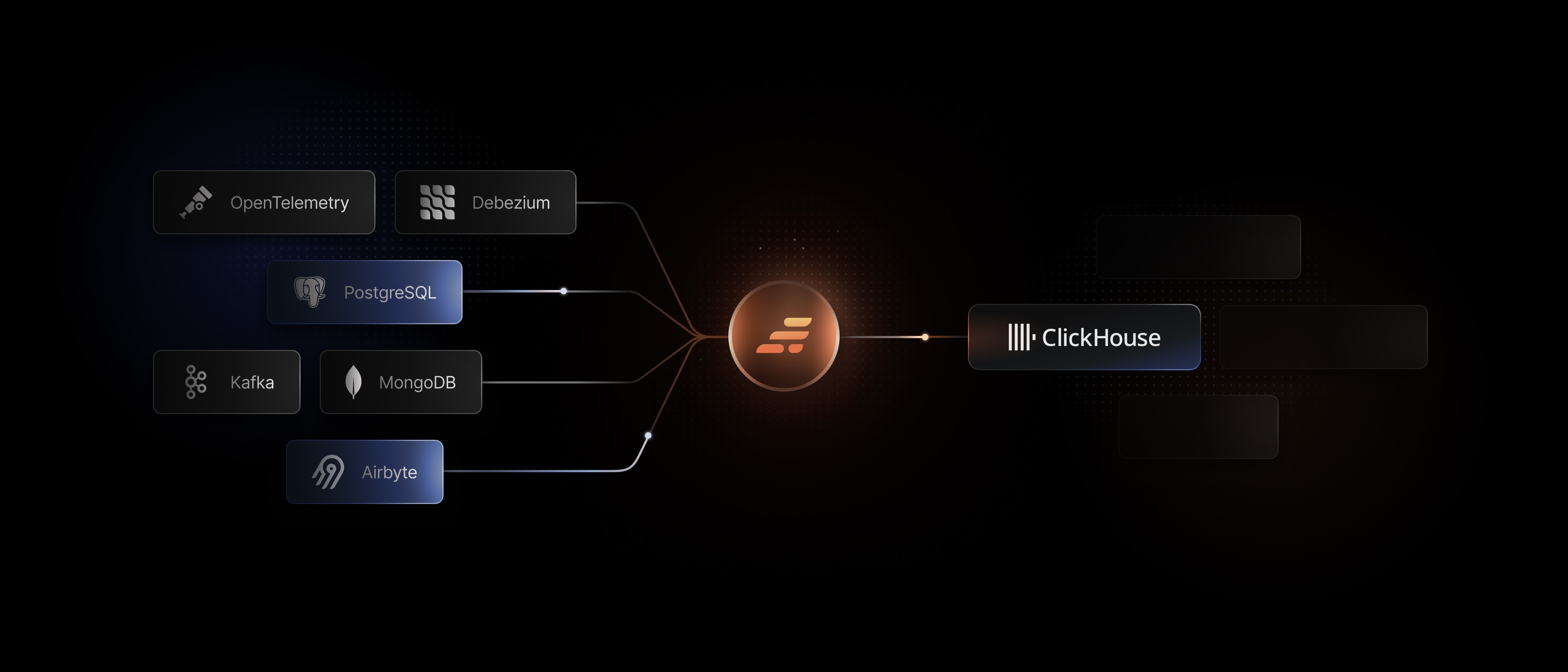
ClickHouse Ingestion Problems
Most ClickHouse projects break
in the first 30 days
ClickHouse queries are fast but getting correct data into ClickHouse is the hard part. Most teams face one or more of these issues when ingesting data to ClickHouse:

Historical backfills are painful
You need old PostgreSQL, MySQL, or MongoDB data in ClickHouse before your analytics are useful. But historical imports usually break when live updates start.
Keeping ClickHouse continuously synced from Postgres WAL, MySQL binlog, MongoDB, or Debezium quickly becomes messy. Teams end up maintaining custom glue code.

CDC becomes fragile
Historical imports and CDC running together create race conditions.
Older rows overwrite newer state. Your analytics become inconsistent.

Backfills overwrite live updates
A new column appears. JSON changes. Nullable types drift. Suddenly, ingestion fails.

Schema changes break ingestion
Strings instead of Int32. Broken timestamps. Mixed date formats. Nested JSON. ClickHouse rejects rows or silently stores incorrect data.

Data arrives in the wrong format
OTEL, CDC, events, and billing systems. You want one correct table in ClickHouse. Instead, pipelines become messy.

Data comes from multiple systems
Duplicates arrive. ReplacingMergeTree gets confusing. FINAL becomes expensive. You no longer trust the data.

Queries are not immediately correct
Duplicates arrive. ReplacingMergeTree gets confusing. FINAL becomes expensive. You no longer trust the data.
ClickHouse Ingestion, Solved
Built specifically to solve ClickHouse
ingestion pains
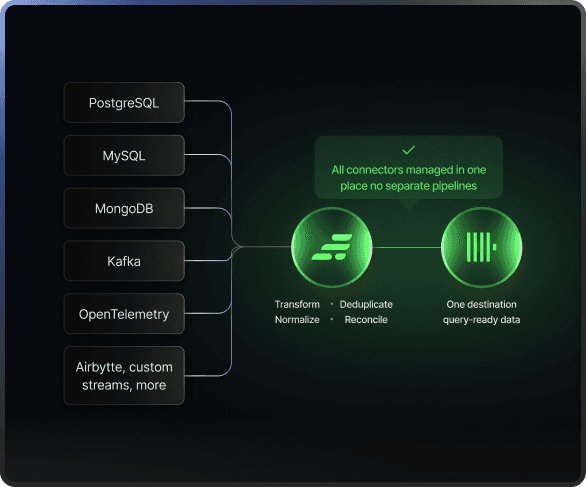
GlassFlow sits between your sources and ClickHouse. Deduplication, filtering and data transformations are resolved upstream, not patched downstream.
01
Safe Historical Backfills
02
Built-in CDC for PostgreSQL, MySQL, and MongoDB
GlassFlow reads database changes directly from:
PostgreSQL: WAL
MySQL: binlog
MongoDB CDC > Debezium
Kafka topics
custom CDC streams
For teams already using Debezium: GlassFlow consumes CDC events and prepares them for ClickHouse.
For simpler teams: GlassFlow can set up CDC internally without requiring Kafka. Instead of building custom consumers, GlassFlow turns change events into query-ready ClickHouse data.
03
Safe historical & live sync for ClickHouse
GlassFlow tracks entering and state updates before ingestion.
Using timestamps, primary keys, and configurable conflict rules, GlassFlow ensures only the newest version of a record reaches ClickHouse. Configurable for long-time windows.
Instead of relying on expensive FINALs queries later, correctness is enforced before ingestion.
04
Schema evolution built in
GlassFlow continuously observes incoming schemas and adapts pipelines automatically.Instead of failing ingestion, GlassFlow keeps multiple schema versions flowing safely while adapting ClickHouse in the background.
05
Data Normalization
GlassFlow transforms messy operational data before it reaches ClickHouse. Teams can:
correct data types
normalize timestamps
extract values from strings
flatten JSON
standardize formats
06
Multiple Connectors
GlassFlow manages operational data before it reaches ClickHouse. No matter if you use OTEL, PostgreSQL, Kafka, etc. Manage all your ClickHouse connectors in one place. See all integrations
07
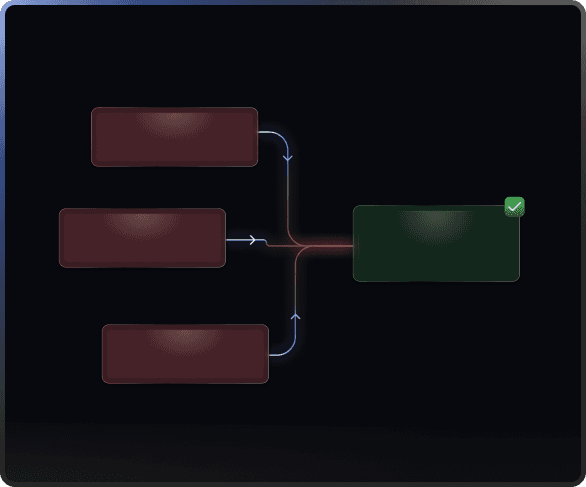
Deduplication before ClickHouse
GlassFlow deduplicates records before ingestion using configurable windows and primary keys.
Instead of sending every duplicate event into ClickHouse:
GlassFlow only forwards the correct latest version.
This keeps dashboards and queries correct immediately.
Without waiting for background merges.
Without expensive FINAL queries.
08
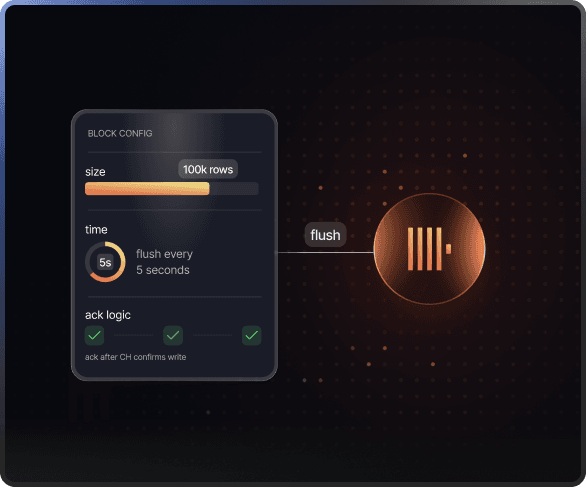
Optimized ingestion for ClickHouse
Fast ingestion is not only about throughput. It is about writing data in the way ClickHouse expects.
GlassFlow automatically optimizes its ingestion logic for ClickHouse. Instead of sending tiny inefficient writes or overwhelming clusters with bad ingestion patterns, GlassFlow continuously batches and flushes data using ClickHouse-friendly block sizes.
This improves:
ingestion performance
query performance
storage efficiency
cluster stability
Without manual tuning.

Why GlassFlow
Purposely-built for
ClickHouse Ingestion
General-purpose ETL tools are great at moving data.
ClickHouse ingestion is different.
Generic ETLs
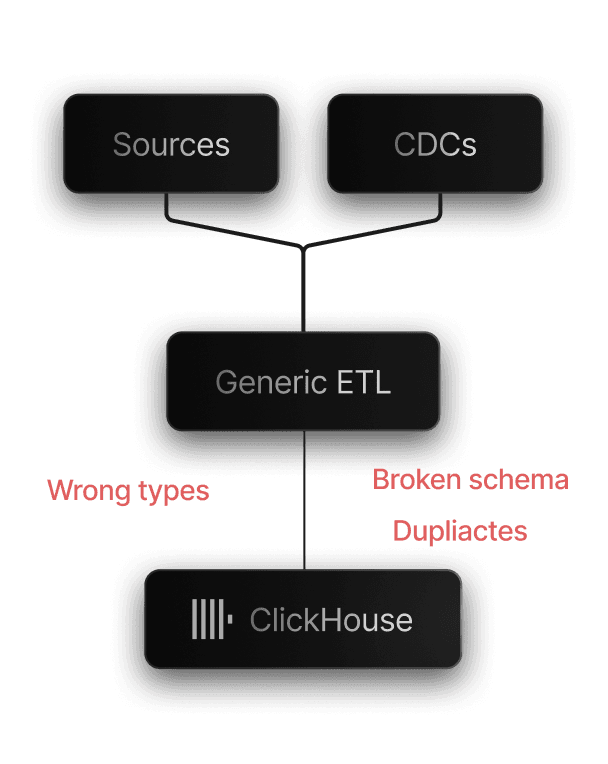
Fix after data arrived

Data arrives in the right shape
Generic ETL tools are built for broad data movement
But ClickHouse introduces challenges that general-purpose pipelines often struggle with, like schema evolution, wrong data types, duplicatesCDC, dumb ingestion logic, and more.
ClickHouse Ingestion at Scale
Start simple.
Scale when you need it.
10x growth of your data? Nothing to worry about. Start with GBs and end up with TBs of data ingested into ClickHouse per day. GlassFlow is built to support you through your entire ClickHouse growth journey.
Horizontal scaling
High throughput ingestion
Low latency





