ljn
Comparisons
We compared GlassFlow and ClickPipes for ClickHouse deduplication
Written by
Armend Avdijaj
-

Introduction
In the previous articles, we saw how ReplacingMergeTree engine can be used in ClickHouse through ClickPipes to achieve gradual deduplication with minimal efforts. However, we also presented various drawbacks of using this approach like having to use the resource intensive FINAL keyword to force trigger the merge operation to obtain immediate deduplicated records. Finally, we presented Glassflow as an alternative for this use case.
Now, the question is, would it also result in better performance? Well, we will be checking that very thing in this article. So, let’s get started!
Understanding ReplacingMergeTree and FINAL
First, let’s start with an introduction to ReplacingMergeTree and the FINAL modifier/operation in ClickHouse.
How ReplacingMergeTree Works
ReplacingMergeTree is a specialized table engine that was created by ClickHouse for performing deduplication with background merge operations. The following image gives you an idea on how this table engine actually works.
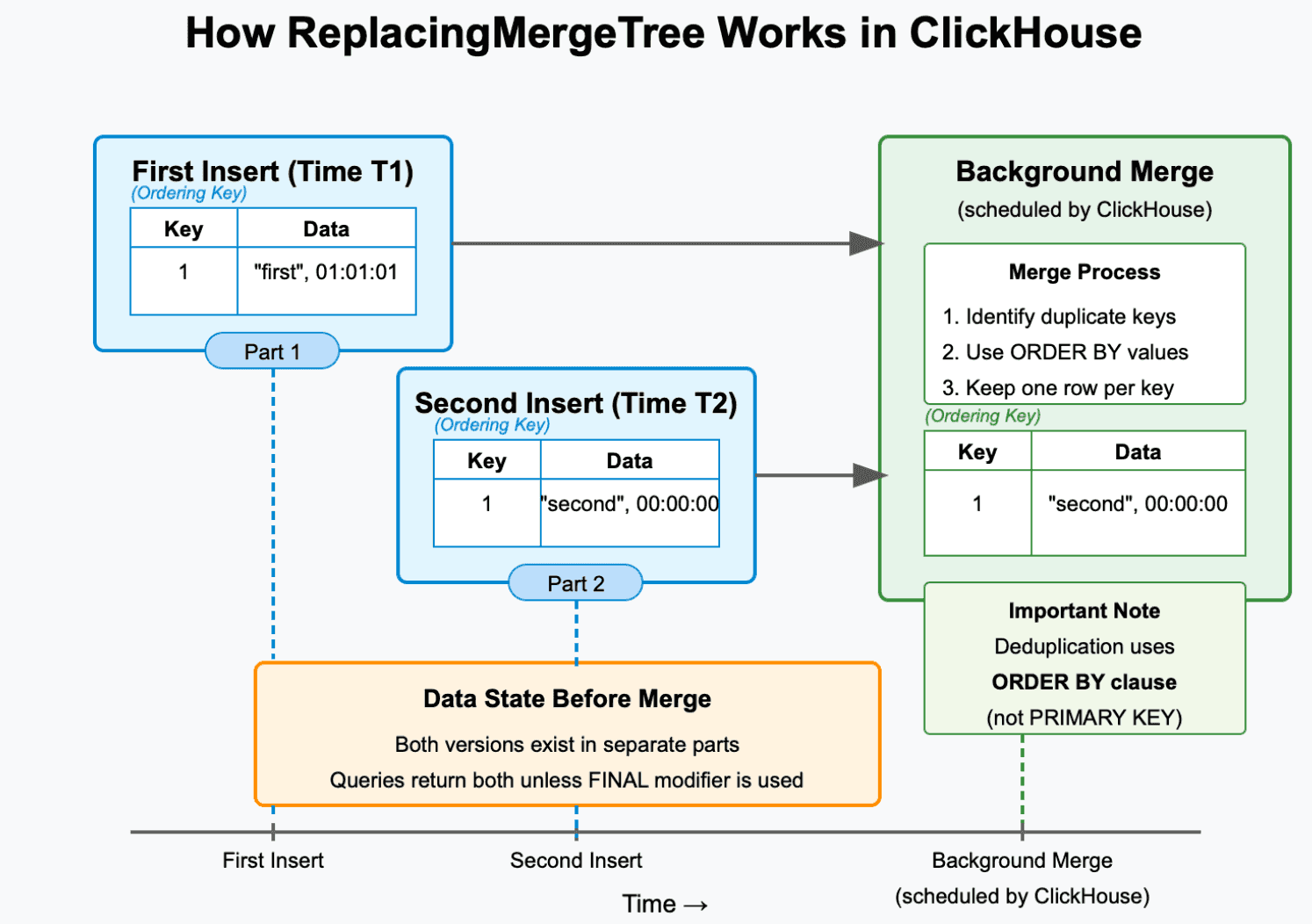
Figure 1. How ReplacingMergeTree Works
We’ve explored this in depth in a previous article—feel free to check it out if you’d like a deeper dive into the mechanics behind this engine.
FINAL: Explained
In ClickHouse, the FINAL keyword is used in SELECT queries to enforce on-the-fly deduplication for tables using engines like ReplacingMergeTree. While ReplacingMergeTree automatically merges and deduplicates data in the background, this process is asynchronous and may not complete before a query is executed, potentially leading to duplicate rows in query results. By appending FINAL to a query, ClickHouse performs a full merge of relevant data parts during query execution, ensuring that only the latest version of each row is returned.
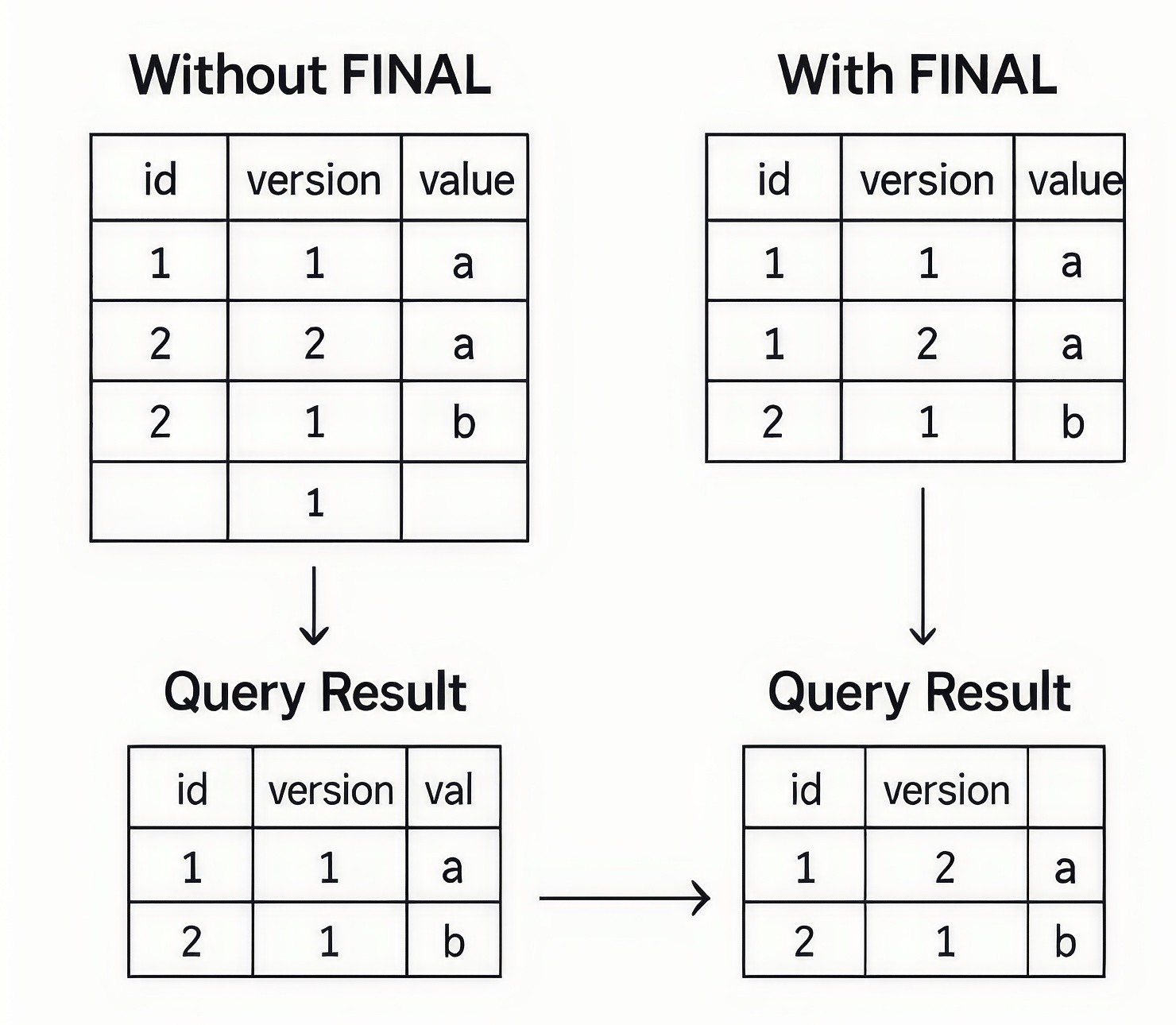
Figure 2. How FINAL Keyword works
Performance Considerations with FINAL
Using the FINAL keyword in ClickHouse can be surprisingly heavy on system resources—especially when you're working with large datasets. Since it forces a merge of all relevant data parts at query time, it demands significant memory and compute power. To keep things efficient in production environments, it's generally recommended to pair FINAL with filters on primary key columns or partitions, helping reduce the amount of data that needs to be processed. You can check out the following articles to know more about the limitations that using FINAL might pose:
https://altinity.com/blog/clickhouse-replacingmergetree-explained-the-good-the-bad-and-the-ugly
https://clickhouse.com/docs/best-practices/avoid-optimize-final
Now here’s the interesting part: there have been notable performance improvements recently. What used to be a single-threaded bottleneck is now powered by multi-threading and a host of internal optimizations. That said, FINAL is still noticeably slower than regular queries, specially when the dataset size is huge.
Now that we have a better idea on what will be the first method that we would be using for deduplication, let’s cover briefly what Glassflow is and how it is a suitable and better alternative to this.
GlassFlow: The Go To Streaming Solution
GlassFlow for ClickHouse Streaming ETL is a real-time stream processor designed to simplify data pipeline creation and management between Kafka and ClickHouse. It provides a powerful, user-friendly interface for building and managing real-time data pipelines with built-in support for deduplication and temporal joins.
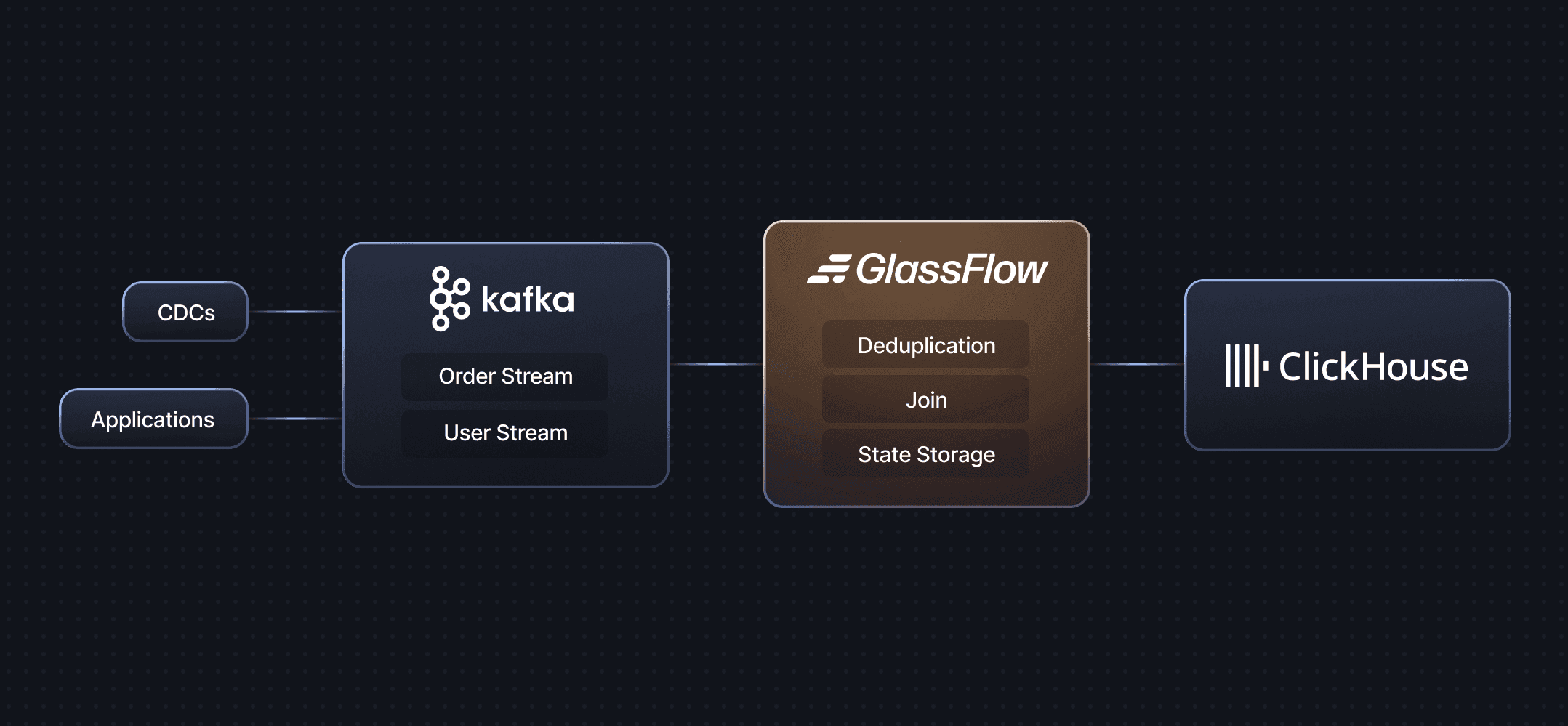
Figure 3. Where does GlassFlow fit in? (Source: GlassFlow Docs)
For this article, we will be focusing on the Streaming Deduplication feature that GlassFlow provides and compare it with using ClickPipes on ClickHouse Cloud with ReplacingMergeTree.
Experimental Setup
Test Environment
The experiment was conducted on a Macbook Pro with the following specifications:
Specification | Details |
|---|---|
Model Name | MacBook Pro |
Model Identifier | Mac14,5 |
Model Number | MPHG3D/A |
Chip | Apple M2 Max |
Total Number of Cores | 12 (8 performance and 4 efficiency) |
Memory | 32 GB |
In terms of infrastructure setup, we will be using the following architecture.

The setup includes:
Glassgen: This is a state-of-the-art synthetic data generator created by Glassflow specifically for streaming data.
Kafka: Running on Confluent Cloud.
ClickHouse Cloud: For this article, I am running a cloud instance of ClickHouse to ensure a realistic, production-grade setup. The service is configured to auto-scale based on workload demand, with the following parameters:
Minimum vertical scaling per node: 16 GiB memory, 4 vCPUs
Maximum vertical scaling per node: 120 GiB memory, 30 vCPUs
Number of replicas: 3
This means the total cluster can elastically scale anywhere between 48 GiB / 12 vCPUs to a maximum of 360 GiB / 90 vCPUs, depending on the query load and resource usage. Additionally, the idle timeout is set to the default of 15 minutes, which helps reduce cost during inactivity while introducing a minimal cold-start delay (typically 20–30 seconds).

Figure 4. ClickHouse Cloud Environment Configuration
Additionally, for testing ReplacingMergeTree engine that ClickHouse provides, we will be using ClickPipes to establish connectivity with Confluent Kafka.
GlassFlow ClickHouse ETL: Deployed in Docker, responsible for processing messages from Kafka and writing them to ClickHouse.
Data Design
This dataset chosen mimics a common real-world use case—user transactions status in an e-commerce or app-based environment. It allows for deduplication testing.
Column | Type | Description |
|---|---|---|
| String | Unique ID |
| String | Version of the transaction (0,1,2) |
| String | User’s Name |
| String | Transaction status (e.g., 'pass', 'fail') |
| Int64 | When the transaction occurred |
The table will be created using the ReplacingMergeTree engine with the id column as the sorting key. The create table command is as follows (you will need the table created when you are using Glassflow):
For this experiment, we will be using the following parameters:
Number of records: 250,000
Duplication Ratio: 20%
Glassgen Records per second: 50000
Duplication Key: id
To learn more about using Glassflow and Glassgen, check out their repos! You'll find clear, step-by-step guides to quickly set up data generators and build streaming data pipelines in just minutes. For your reference, here is the configurations I used for Glassgen to create my dataset:
Experiment and Results
Now that we’ve laid the groundwork and executed the experiment using both methods, let’s dive into the results. We’ll explore each method's behavior in terms of ingestion time, deduplication consistency, and query reliability, keeping a close eye on performance and operational simplicity.
ReplacingMergeTree via ClickPipes
Before we get into the results, you can refer to this article to learn how to create a Kafka ClickPipe on ClickHouse Cloud. Once you do that, you should see the following on your Data Sources page:
Figure 5. ClickHouse Data Sources section with a configured ClickPipe
Using ClickHouse’s native ReplacingMergeTree engine with ClickPipe to consume data from Kafka, we ingested 250,000 records—with an intentional duplication ratio of 20% (~41,667 duplicate entries).
Here’s where things got interesting:
Initial ingestion of data using Glassgen and ClickPipe was relatively fast—clocking in at around 70 seconds.
However, because
ReplacingMergeTreerelies on background merge operations to deduplicate, the actual time for the final, deduplicated state to materialize took up to an hour. That’s an hour of uncertainty before you can reliably query deduplicated data.Using the
FINALkeyword on a SELECT query forced a merge at query time, resulting in an output of ~208,998 rows (slightly more than expected due to merge granularity). But this comes with a performance cost, asFINALoperations are resource-intensive—especially without sufficient filtering or partitioning.
Method | Total Records | Duplicates | Ingestion Time | Rows After FINAL | Expected Rows |
|---|---|---|---|---|---|
ClickPipe + RMT | 250,000 | 41,667 | 70s + ~1hr merge | 208,998 | 208,333 |
While ClickHouse eventually reaches the correct result, the reliance on asynchronous background merges or compute-heavy FINAL queries introduces unpredictability and performance overhead. Not ideal for real-time or low-latency pipelines.
Glassflow with Streaming Deduplication Pipeline
On the other side, Glassflow’s streaming deduplication pipeline offered a cleaner and more predictable experience.
First, to create a Glassflow Deduplication Pipeline, you can simply follow the demo. All you have to do is configure Kafka and ClickHouse setup, select the deduplication keys and a few pipeline parameters and you are good to go! Note that we chose 10,000 as our batch size per second for streaming our data into ClickHouse. You can easily choose a higher number for systems/servers with more advanced configurations. You should see the following screen once you have setup your pipeline:
Data was generated using Glassgen and streamed via the Glassflow ETL pipeline. The generation step was the same for both the scenarios for consistency.
Total ingestion time: 72.8 seconds for data generation + 52 seconds for the Glassflow job to process a few thousand remaining records and load into ClickHouse. No need to wait for background merges.
Immediately after ingestion, querying the ClickHouse table returned exactly 208,333 deduplicated records, right on the mark—no need for FINAL.
The immediate consistency here is key: you get correct data immediately after the stream completes, making it far more suitable for real-time dashboards and analytics.
Method | Total Records | Duplicates | Ingestion Time | Rows in Table | Expected Rows |
|---|---|---|---|---|---|
Glassflow | 250,000 | 41,667 | 72.8s + 52s = ~125s | 208,333 | 208,333 |
Beyond raw performance, Glassflow brings operational simplicity—you don’t need to think about merge strategies, tuning min_age_to_force_merge_seconds, or guarding every query with FINAL.
🏁 Conclusion: When to Use What?
While both methods eventually arrive at the correct deduplicated result, Glassflow wins on all fronts for streaming deduplication:
✅ Faster Time to Consistent Data: No need to wait for background merges or rely on
FINAL.✅ Predictable Query Behavior: What you ingest is what you get—every time.
✅ Simplified Ops: No merging logic, no tuning, no surprise CPU spikes due to
FINAL.
In contrast, ClickHouse’s native ReplacingMergeTree engine, while powerful, struggles with timeliness and operational clarity when used for real-time deduplication in high-throughput streaming environments.
That being said, there are scenarios where ClickPipes be useful. If your priorities include:
Single-click ingestion pipelines from an alternative source like Postgres.
Managed, low‑maintenance cloud-native simplicity with built‑in schema tracking
Use cases where a bit of merge latency is acceptable
If any of the above three define your use case, then ClickPipes becomes a compelling, low‑ops option. Moreover, it is ideal for organizations already embedded in the ClickHouse Cloud ecosystem who want to skip custom stream processing and rely on a fully managed ingestion layer.
However, if your use case involves streaming ingestion and you care about data freshness, consistency, and performance - Glassflow is the way to go.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
