Simplify Cloudflare’s ClickHouse log analytics with GlassFlow: faster, cleaner.
Written by
Armend Avdijaj
Aug 20, 2025

If you are new to ClickHouse, you would probably have read this amazing article by CloudFlare explaining how they use it for handling their logging at 6 million requests per second. However, the article was written in 2018 and a lot has changed since then.
In this article, I will be presenting GlassFlow as a very compelling alternative to the approach CloudFlare used back then to optimize the ingestion aspect of moving data from Kafka to ClickHouse tables. The major advantage of using GlassFlow is that it is fully open-source, offers immediate data deduplication and reduces the overall load on your ClickHouse cluster.
Before, we start, let’s see what CloudFlare did to solve their massive log storing problem.
CloudFlare Article Overview
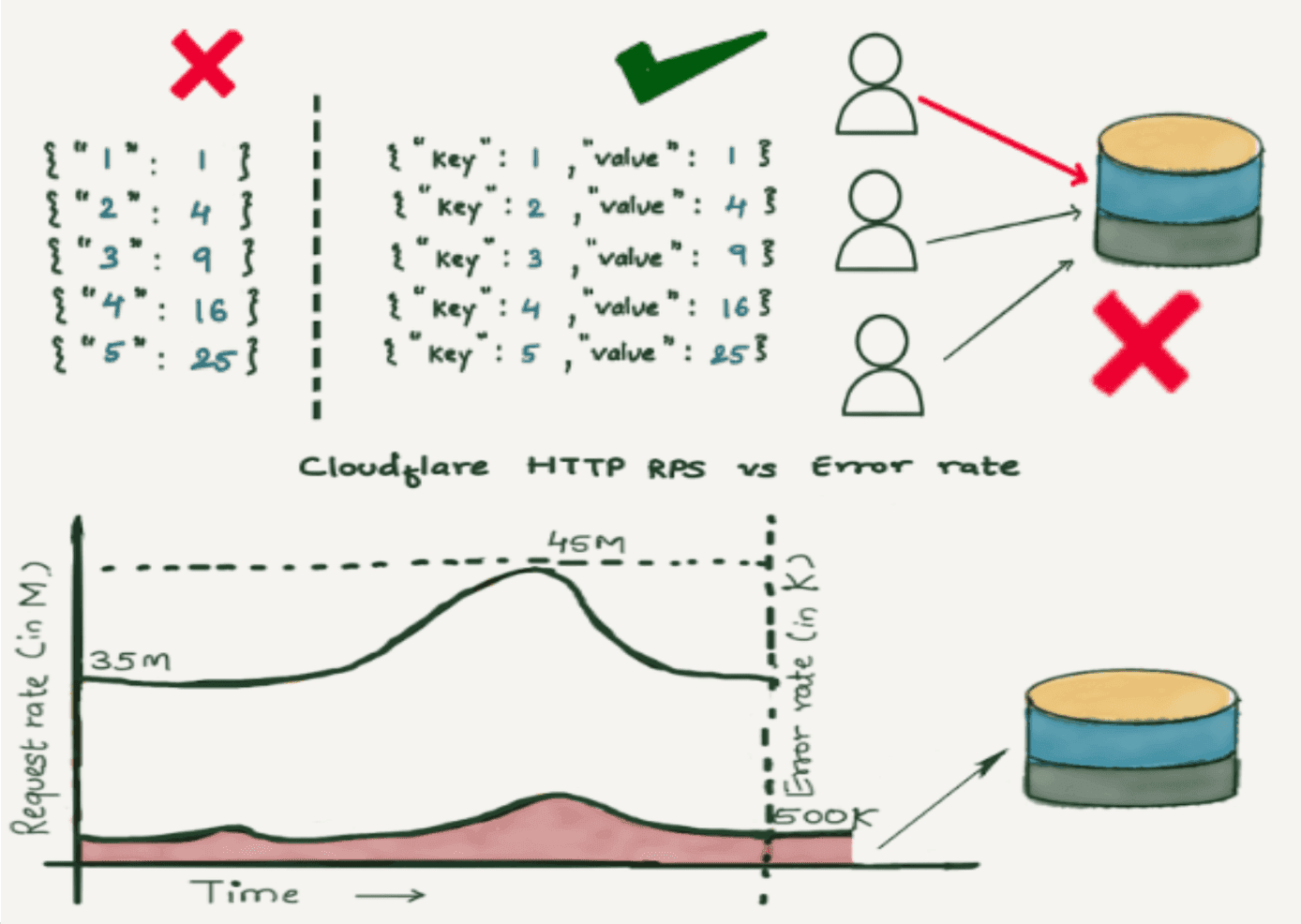
Figure 1. Where CloudFlare’s ElasticSearch Logging System Failed? (Reference)
CloudFlare faced a serious problem back in 2018: their Elasticsearch-based logging system simply couldn’t keep up with the chaos of millions of requests per second. With field-mapping explosions, JVM-induced slowdowns, shoddy tenant isolation, and sluggish dashboards, the old stack just wasn’t cutting it. So they went all-in on ClickHouse—and it was a game-changer.
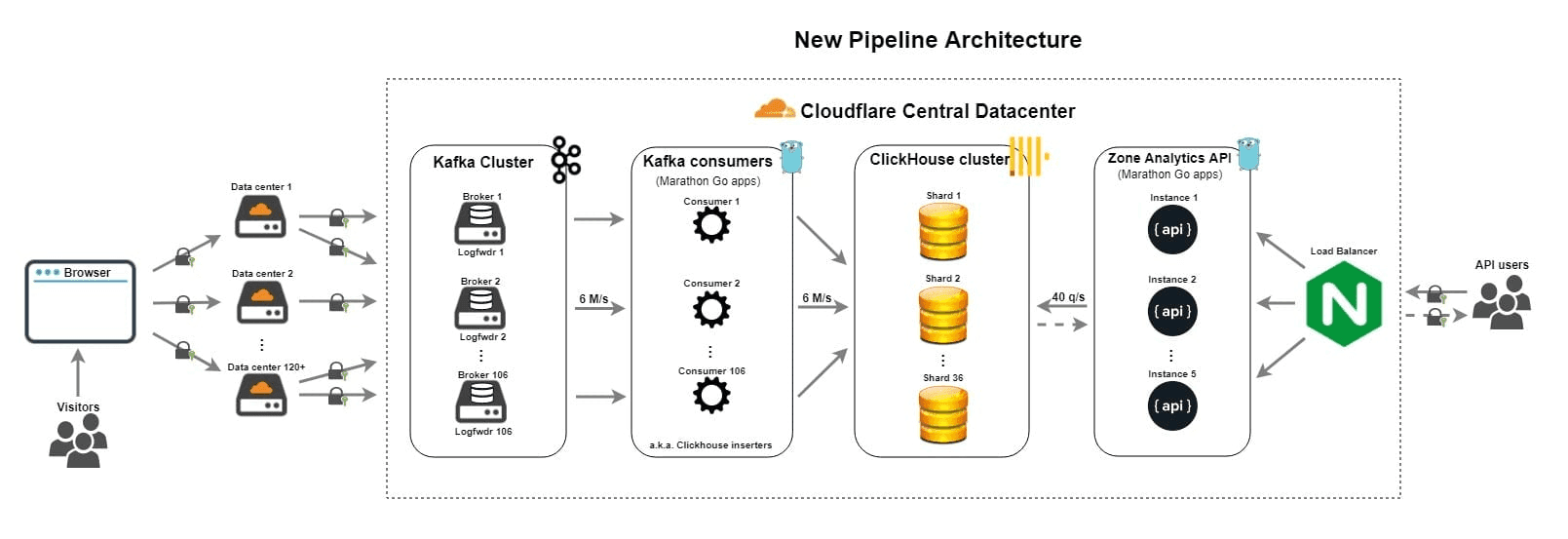
Figure 2. How CloudFlare’s solved their Logging Problem?
At the heart of CloudFlare’s reimagined pipeline lies a brilliantly engineered Kafka-based ingestion stack. Logs are produced in a compact, Cap’n Proto format, shipped into Kafka, and then batched smartly into ClickHouse via a high-throughput inserter. The trick? Balance is everything: too-small batches overwhelm ClickHouse with tiny parts and sprawl during merges; too-large ones threaten memory limits. They got it just right, and unleashed real performance.
ClickHouse itself plays several roles in this makeover. Its columnar storage with per-column compression and sparse secondary indexes cuts storage costs and accelerates scans. CloudFlare studies three modeling patterns—strict schema (safe and fast), dynamic JSON (flexible but risky), and a resilient key-value array approach for unpredictable schemas—and lands heavily on the array model, promoting frequent fields to materialized columns as needed. They combine this with thoughtful partitioning (hourly), carefully tuned primary key choices (since sorting is immutable), and data skipping indexes to keep queries zipping along.
Finally, there’s their brilliant ABR trick (Adaptive Bit Rate): store logs at multiple sampling rates across separate tables—100%, 10%, 1%, and even 0.1%. Dashboards simply pick the lightest sample that still gives them accurate answers, massively slashing query cost while keeping full-granularity data around for deep dives.
The result? A leaner, faster, and much more cost-effective system—handling write-heavy log floods with ease and offering reliable, swift insights when it matters. However, this was state-of-the-art in 2018, not anymore. There is a lot of setup that would be required for this kind of architecture. What if I told you that your task would become a 100x easier and that all you need to do is slot in a single game-changing piece: GlassFlow. But how? Well, that is what this article answers.
GlassFlow from Kafka → ClickHouse Ingestions
Glassflow is a real-time streaming ETL engine designed to process Kafka streams before data hits ClickHouse. So, it can essentially replace the “ClickHouse Inserters” in CloudFlare’s architecture.
Now, let’s understand how this will actually help us.
Updated Architecture
If you remember, our use case involves processing terabyte scale logging data and putting it into ClickHouse for Dashboards and Analytics. Now, the question is, where will GlassFlow fit in? Well, we can replace the Kafka Consumers (i.e. the inserters) with GlassFlow Pipelines! So, we can utilize Kafka to it’s fullest and configure 106 different pipelines to get the maximum throughput and records per second.
Here is what the updated architecture will look like with a simple flow diagram:
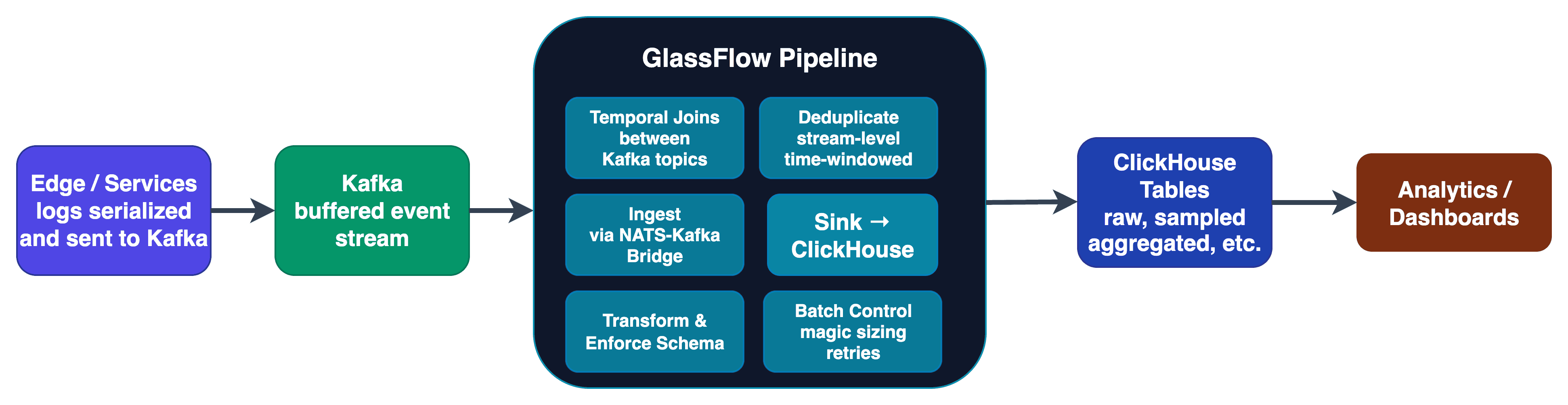
Figure 3. How GlassFlow fits in?
With GlassFlow taking over the ingestion stage, the entire pipeline becomes leaner and more intelligent. Instead of having static Kafka consumers shoveling data into ClickHouse, GlassFlow dynamically batches, deduplicates, transforms, and enforces schema — all before data ever hits your database. This not only reduces write amplification on ClickHouse, but also ensures your data lands in a query-ready format instantly.
What’s more? Because GlassFlow is designed for high-throughput streaming workloads, we can spin up dozens or even hundreds of independent pipelines — each tuned for specific datasets, joins, or transformations — without the operational headache of maintaining custom inserters. And with an easy retry mechanism through the Python SDK and temporal joins, it makes sure that no matter how spiky your incoming logs are, ClickHouse stays smooth and ready for those lightning-fast dashboard queries.
In short, the architecture shifts from “push logs and hope” to “process, perfect, and deliver” — at scale.
Why Should you Choose GlassFlow?
Now, let’s see how would GlassFlow actually impact the current solution:
Feature / Stage | Cloudflare Approach (Original) | GlassFlow-Enhanced Approach |
|---|---|---|
Data Ingestion | Static Kafka consumers feeding ClickHouse | GlassFlow handles ingestion with dynamic scaling & auto-balancing |
Transformations | Done downstream or manually in ClickHouse | Real-time Deduplication and Temporal Joins Support |
Schema Handling | Must manage schema evolution manually | schema enforcement & evolution through the Pipeline |
Deduplication | Requires custom logic in ClickHouse | Built-in deduplication before data lands |
Join Handling | Implemented manually in queries | Native temporal & stream joins during ingestion |
Throughput Management | Risk of spikes overwhelming ClickHouse | Backpressure handling & auto-throttling |
Pipeline Management | Single-purpose, rigid consumers | Multiple independent pipelines per dataset/use case |
Operational Overhead | High — need to maintain Kafka consumers & inserters | Low — managed ingestion, transformation & delivery |
Query Readiness | Logs often need preprocessing before querying | Logs arrive pre-processed, query-ready instantly |
Resilience | Manual retry logic if ingestion fails | Can setup checks and retries through the Python SDK |
Conclusion
Cloudflare’s log analytics journey demonstrates the power of the right architecture — but this article highlights how much simpler and faster things could be with GlassFlow. By combining streaming and batch pipelines in one, and removing the pain of custom connectors, ETL jobs, and brittle transformations, GlassFlow lets you focus on insights instead of infrastructure.
Whether you’re just starting out with ClickHouse or already operating at scale, GlassFlow gives you a modern, event-driven pipeline that works out-of-the-box with your existing stack. The time saved on setup and maintenance can go directly into building better dashboards, enriching your data, and delivering value to your users.
Get started here:
With GlassFlow, you’re just a few clicks away from a fully operational, high-throughput, real-time analytics pipeline — without the headaches.



