ljn
Comparisons
When Kafka fits and when alternatives make sense.
Written by
Armend Avdijaj
-

Top Alternatives to Kafka
Apache Kafka is the standard for handling real-time data feeds. It powers the event-driven architectures of companies like Uber, Netflix, and LinkedIn. But for many engineering teams, Kafka is overkill. It can be complex to manage, resource-heavy, and difficult to scale without a dedicated team.
If you are a data engineer or software developer looking for the right tool for your streaming needs, you have options. This article covers why Kafka is relevant, where it struggles, and the best alternatives available today.
What is Kafka good at
To understand the trajectory of the data streaming market, you must first deeply understand the incumbent. Apache Kafka is not merely a tool; it is an institution. Created at LinkedIn in the early 2010s to handle massive volumes of activity tracking data, it was open-sourced to the Apache Software Foundation and quickly became the de facto standard for high-throughput data movement.
Kafka’s primary innovation was the re-imagining of the log. Traditional messaging queues (like ActiveMQ or RabbitMQ) treated messages as transient: once consumed, they were gone. Kafka treated data as a continuous, persisted commit log. This allowed multiple consumers to read the same stream at different speeds and replay history if necessary, fundamentally enabling the "event sourcing" and "stream processing" paradigms that power modern microservices.
As of 2025, Kafka underpins the critical infrastructure of over 80% of Fortune 100 companies. Its ecosystem is unrivaled. The "Kafka API" has effectively become the TCP/IP of the data world—a standardized protocol that every vendor must speak to be relevant. This ubiquity means that a vast array of connectors, monitoring tools, and client libraries are available off-the-shelf, creating a powerful network effect that reinforces its leadership position.
Recent years have seen Kafka evolve to address its own legacy debt. The most significant shift has been the transition to KRaft (Kafka Raft) mode, which reached maturity with Kafka 4.0. Historically, Kafka required a separate cluster of ZooKeeper nodes to manage metadata, leader election, and configuration. This "two-system" requirement was a major source of operational complexity and a common point of failure. KRaft eliminates ZooKeeper, embedding the metadata management directly into the Kafka brokers via an internal Raft quorum. This simplification allows for easier deployments, faster controller failovers, and the theoretical ability to support millions of partitions within a single cluster—a feat previously unattainable due to ZooKeeper’s metadata bottlenecks.
What are the challenges of Kafka
Despite these evolutionary steps, Kafka faces significant headwinds driven by the realities of modern cloud infrastructure and the changing profile of the data developer.
The Coupling of Compute and Storage
Kafka’s architecture was born in the data center era, where maximizing the utilization of physical servers was paramount. Consequently, a Kafka broker is responsible for both processing requests (compute) and storing data on local disks (storage). In a cloud-native environment, this coupling is inefficient. If a cluster runs out of disk space but has ample CPU, the operator must still add more brokers (paying for both compute and storage) to expand capacity. Conversely, if the system is CPU-bound due to heavy SSL termination or compression but has empty disks, one must still scale out the storage-heavy nodes. This lack of independent scaling leads to inevitable over-provisioning and resource waste.
The Economics of Cloud Networking
Perhaps the most acute pain point is the cost of durability in the cloud. Kafka ensures data safety through replication: a message written to a leader partition is copied to follower partitions on different brokers. In a properly architected cloud deployment, these brokers reside in different Availability Zones (AZs) to survive a zone failure.
However, cloud providers charge significantly for data transfer between AZs. In a standard Kafka setup with a replication factor of 3, every gigabyte of data ingested incurs cross-zone networking charges three to four times (leader to followers, and potentially consumers reading from followers or just the sheer volume of rebalancing traffic). This phenomenon, often termed the "Kafka Tax," can inflate the infrastructure bill to 3x or 4x the cost of the underlying storage and compute. Alternatives like WarpStream specifically attack this economic inefficiency.
The JVM and Operational Complexity
Kafka runs on the Java Virtual Machine (JVM). While the JVM is mature and performant, it introduces non-deterministic latency spikes due to Garbage Collection (GC) "stop-the-world" events. For standard analytics, a 100ms pause is negligible. For high-frequency trading, real-time ad bidding, or industrial automation, it is unacceptable.
Furthermore, despite KRaft, Kafka remains operationally heavy. Tuning a cluster for optimal performance requires adjusting hundreds of parameters—from OS page cache settings to JVM heap sizes and internal broker threads. Managing "Day 2" operations, such as rebalancing partitions when a broker is added or removed, involves massive data movement across the network, which can saturate bandwidth and degrade cluster performance during the operation.
In Short
Kafka has a high operational complexity. It is hard to set up and maintain. Traditionally, it required managing a separate ZooKeeper cluster, though newer versions (KRaft) are removing this dependency.
Kafka has a steep Learning Curve. Understanding partitions, offsets, consumer groups, and replication factors takes time.
Kafka has a high maintenance overhead. It requires constant tuning. You need to manage disk usage, rebalance partitions, and monitor broker health carefully.
You have to pay attention to cost. Running a highly available Kafka cluster requires significant infrastructure, even for low-volume use cases.
Why is Kafka so relevant
Kafka is relevant because it solves the "spaghetti integration" problem. Before Kafka, systems connected directly to each other. If System A changed, System B, C, and D broke. Kafka sits in the middle as a universal buffer. It standardizes how data flows through an organization.
Use case: Building Streaming pipeline for observability with Kafka, GlassFlow and ClickHouse
One architectural pattern has emerged for real-time analytics: utilizing Kafka for ingestion, GlassFlow for transformation, and ClickHouse for analysis. This stack addresses specific, critical limitations in ClickHouse's design regarding real-time data.
The ClickHouse Ingestion Challenge
ClickHouse is an OLAP database designed for lightning-fast queries on massive, immutable datasets. It achieves this via the MergeTree family of table engines. However, it struggles with "messy" real-time streams:
Deduplication is Expensive: Real-time streams often contain duplicates (at-least-once delivery). ClickHouse handles duplicates asynchronously via background merges (
ReplacingMergeTree). To query the "correct" data in real-time, one must use theFINALkeyword (e.g.,SELECT count() FROM table FINAL), which forces a merge at query time. This operation is incredibly CPU-intensive and kills query latency.Joins are Costly: ClickHouse is not optimized for complex joins at read time. It performs best on wide, denormalized tables. Joining a high-velocity stream with a dimension table during a query can lead to memory exhaustion.
GlassFlow as the "Stream Cleaning" Layer
GlassFlow inserts itself upstream of ClickHouse to solve these problems before the data persists.
Use Case 1: Real-Time Deduplication
Instead of relying on ClickHouse to merge duplicates, GlassFlow filters them in the stream.
Mechanism: The user defines a deduplication window (e.g., 24 hours) and a key (e.g.,
transaction_id). GlassFlow maintains an ephemeral state store of all keys seen in that window.Process: As a new event arrives from Kafka, GlassFlow checks the state store. If the key exists, the event is dropped. If not, it is passed downstream and the key is added to the store.
Outcome: ClickHouse receives a guaranteed unique stream. The database no longer needs
ReplacingMergeTreeorFINAL, significantly reducing CPU load and storage footprint.
Use Case 2: Temporal Joins
GlassFlow enables "streaming joins" to denormalize data.
Scenario: A stream of
page_viewscontains auser_idbut no user details. A separate stream ofuser_updatescontains demographic info.Mechanism: GlassFlow buffers the
user_updatesstream in its state store. When apage_viewarrives, it looks up theuser_idin the store, enriches the event with the user's demographic data, and emits a fully formed JSON object.Outcome: The data landing in ClickHouse is a single, wide table containing all necessary information. Analysts can query
WHERE user_country = 'US'without performing a join, leveraging ClickHouse's columnar speed.
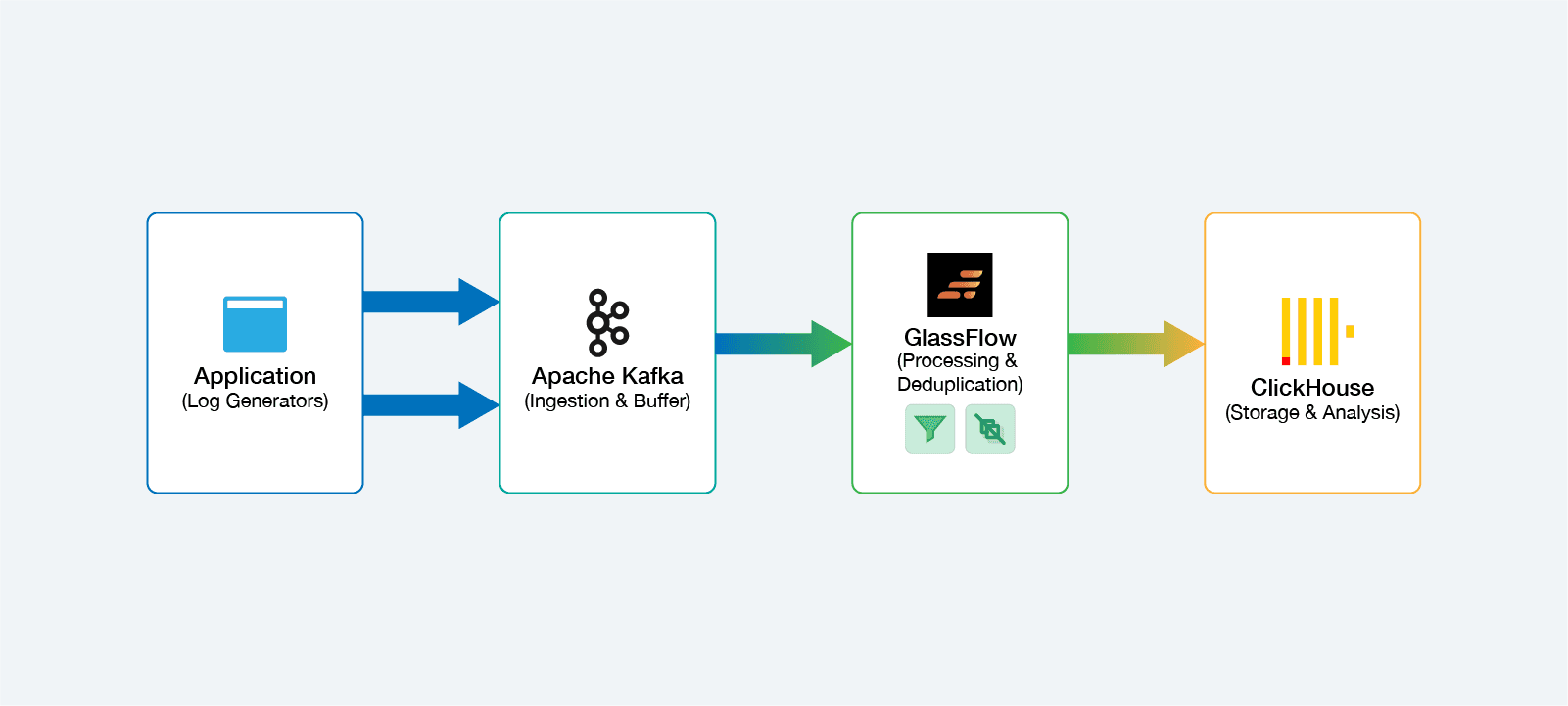
Kafka-GlassFlow-ClickHouse use case
Top Alternatives to Kafka
If Kafka feels like too much for your needs, consider these alternatives.
Apache Pulsar | NATS | Amazon Kinesis | Redpanda | Google Pub/Sub | RabbitMQ | |
|---|---|---|---|---|---|---|
Best For | Complex queuing & streaming | Lightweight speed & Microservices | AWS Ecosystem users | High performance, low ops | GCP Ecosystem users | Traditional messaging & routing |
Key Difference from Kafka | Separates compute from storage | Extremely simple and fast | Fully managed, serverless AWS service | Drop-in replacement (No JVM/ZooKeeper) | Global scale, serverless, no partitions | Focus on complex routing, not throughput |
Programming Language Support | Java, Go, Python, C++, C# | 40+ Client Libraries (Go, Java, etc.) | Java, Python, Go, .NET (AWS SDK) | Any Kafka Client (Java, Python, Go, etc.) | Java, Python, Go, Node.js, C++ | Broad support (Java, Python, .NET, Ruby) |
Management Complexity | High (Requires ZooKeeper & BookKeeper) | Low (Single binary, simple clustering) | Low (Fully managed service) | Low (Single binary, no ZooKeeper) | Low (Serverless, fully managed) | Medium (Erlang runtime, cluster tuning) |
Real-Time Data Transformation | Native (Pulsar Functions) | Client-side only | Native (Kinesis Data Analytics/SQL) | Native (Data Transforms with Wasm) | Integration via Dataflow templates | Client-side only |
Deployment Speed | Slow (Complex architecture setup) | Very Fast | Instant (Cloud provisioned) | Fast | Instant (Cloud provisioned) | Medium |
Scalability | High (Separates compute and storage) | High | High (Shard-based scaling) | High | Very High (Global auto-scaling) | Limited (Vertical scaling preferred) |
Cost Model | Free OSS / Enterprise Support | Free OSS / Enterprise Support | Pay-per-shard / throughput | Source Available / Enterprise | Pay-per-use (Throughput/Storage) | Free OSS / Enterprise Support |
Integration with Other Services | Rich Connector Hub | Growing Ecosystem | Deep AWS Ecosystem Integration | Full Kafka Ecosystem Compatibility | Deep GCP Ecosystem Integration | Mature / Extensive plugin library |
Fault Tolerance and Durability | High (Apache BookKeeper) | Good (JetStream persistence) | High (Multi-AZ replication) | High (Raft consensus) | High (Global replication) | Good (Quorum queues) |
Top stream processing built for Kafka
Once you have data in Kafka (or an alternative), you need to process it. You rarely just move data; you transform it.
GlassFlow
GlassFlow is an open-source, modern stream processing engine designed for data engineers who value simplicity.
Python-First: You write transformation logic in Python, the language data engineers already know.
Kubernetes-Native & Managed: It is k8s-native, handling state and auto-scaling for you so you don't have to manage complex clusters manually.
Focus: It is excellent for tasks like deduplication, splitting streams, and simple transformations before data hits a database like ClickHouse or Snowflake.
Flink
Apache Flink is the heavyweight champion of stream processing.
Power: It supports incredibly complex stateful computations.
Latency: It offers true low-latency streaming.
Complexity: It is difficult to learn and operate. It is usually Java/Scala-based, though PyFlink exists. It is overkill for simple transformation jobs.
KStreams (Kafka Streams)
Kafka Streams is a Java library, not a separate cluster.
Integration: It is part of the Kafka project. If you are already building Java microservices, it is a natural choice.
Deployment: You deploy it as a standard application.
Limitation: It is strictly bound to the Kafka ecosystem and requires writing Java code.
Conclusions
Kafka remains the default for massive scale, but it is no longer the only option. If you want Kafka's API without the headache, look at Redpanda. If you need complex routing, look at RabbitMQ.
For processing that data, match the tool to your team's skills. Use Flink if you have complex, large-scale state requirements. Use KStreams if you are a Java shop.
Tools like GlassFlow are dismantling the barriers to entry erected by Java-centric frameworks like Flink. By offering a serverless, Python-native experience, they are empowering a new generation of data engineers to build sophisticated ETL pipelines that feed high-performance OLAP engines like ClickHouse.
For technical leaders, the path forward involves a careful audit of requirements. If the goal is absolute lowest latency, look to Redpanda. If the goal is to empower a data science team to ship real-time features without Ops support, the Kafka-GlassFlow-ClickHouse stack offers the path of least resistance and highest velocity. The post-Kafka era is not about the death of Kafka, but about the birth of choice.
References
Apache Kafka Documentation: kafka.apache.org
Redpanda vs Kafka Benchmark: redpanda.com/blog
GlassFlow Documentation: docs.glassflow.dev
Apache Pulsar Overview: pulsar.apache.org
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
