ljn
Migrations
Migrating from Redshift to ClickHouse: Step-by-Step Guide
Written by
Armend Avdijaj
-

1. Introduction
Amazon Redshift is a common choice for enterprise data warehousing, serving traditional business intelligence and reporting needs well. However, modern data applications require more: real-time analytics, sub-second queries on high-volume streams, and predictable costs that don't blow up with growth. In these areas, Redshift can become limited.
Scaling a Redshift cluster can introduce operational headaches and cost uncertainty; RA3 nodes create complexity with their opaque hot-cold data tiering, which can cause sudden performance drops. The Serverless model aims for simplicity but its RPU-based pricing makes forecasting costs for spiky workloads difficult. Other features like Concurrency Scaling often act as expensive band-aids, masking underlying capacity problems while adding their own latency spikes. For teams building interactive dashboards, real-time APIs, or observability platforms, these issues are major roadblocks.
If you're a data engineer, you probably already know ClickHouse; an open-source columnar database built to solve these exact problems. Its architecture is particularly focused on query speed, operational transparency, and cost-efficiency.
This article presents a practical migration playbook for engineers moving from Redshift to ClickHouse. We'll provide example executable code, Redshift-specific architectural advice, and a clear direction for data modeling, extraction, loading, and optimization.
Before we start, check the table below; it will give you common pain-points and how ClickHouse addresses these. If some or all of this sounds familiar, then a migration to ClickHouse might be worth considering:
Redshift Symptom | Why It Happens | ClickHouse Fit | Migration Note |
|---|---|---|---|
High query latency for aggregations (>5s) | MPP architecture is for broad scans, not point lookups. AQUA helps but has limits. | Primary key index provides a sparse index for rapid data pruning and sub-second response. | Rethink |
Unpredictable, rising costs | Coupled storage/compute (RA3) or opaque RPU billing (Serverless). Concurrency Scaling adds cost. | Decoupled storage (optional S3) and compute. Granular control over compression and hardware. | Plan storage strategy (local NVMe vs. object storage) based on cost/performance needs. |
Struggles with CDC / real-time updates |
|
| Use a streaming layer like Kafka with a tool like GlassFlow for efficient, deduplicated inserts. |
Limited operational control | Redshift is a "black box". Tuning is restricted to WLM, sort/dist keys, and node types. | Full control over partitioning, indexing, compression codecs, storage layout, and query execution. | This control requires expertise. Start with sensible defaults and tune based on monitoring. |
Table 01: “Is Migration Warranted?” Quick Checklist
2. When (and Why) to Consider Migrating (Redshift-Specific)
Deciding to migrate goes far beyond simple performance benchmarks. The choice must align your database technology with your workload, cost model, and operational philosophy.
Cost & Elasticity
Redshift's scaling model can create unpredictable costs and performance. For example, RA3 nodes tier data between fast SSDs and slower S3, but this process is opaque and can cause sudden query slowdowns when data is unexpectedly "cold." The Serverless option tries to simplify this but links costs to Redshift Processing Units (RPUs), which makes budgeting for irregular analytical traffic difficult. Even features designed to help, like Concurrency Scaling, can mask capacity issues by adding expensive, temporary clusters that introduce their own "cold start" latency. These factors eventually combine to create an environment where performance and cost are hard to control, a significant problem for teams building responsive applications.
Latency & Workload Fit
Redshift's MPP architecture is designed for large, parallel table scans, making it effective for BI reporting. It is not built for the low-latency aggregations required by user-facing analytics. Joins on high-cardinality columns are also a common source of poor performance.
This architectural mismatch is especially painful for real-time workloads. Change Data Capture (CDC) pipelines that require frequent updates or deletions can be used, but in reality are a poor fit. The MERGE command is a heavy, multi-step operation, and tables with many deletes require frequent, blocking VACUUM operations to reclaim space and maintain performance. This is simply too slow and disruptive for a system that needs to reflect changes in seconds.
Operational Control
Redshift is a managed service that hides many of its internal operations. As an engineer, your tuning options are limited to workload management (WLM) queues, sort keys, distribution styles, and instance types. You cannot control how data is compressed, how indexes work at a low level, how storage is physically laid out, etc. ClickHouse gives you direct control over all these aspects, allowing for deep optimization tailored to your specific queries.
3. Key Differences: Redshift vs. ClickHouse
Migrating from Redshift requires a mental shift. The two systems approach data storage, layout, and querying with fundamentally different philosophies. Understanding these distinctions is a must to designing an effective ClickHouse schema:
Storage/Compute: In Redshift, the architecture is a tightly coupled MPP cluster where compute and storage are logically linked. Scaling one often requires scaling the other. ClickHouse separates these concerns. Data can live on local NVMe for maximum performance or in an object store like S3 for cost savings. Shards and replicas provide computational scaling independent of where the data is stored.
Data Layout: Redshift defines data layout with a
DISTKEY(how data is distributed across nodes) and aSORTKEY(how data is physically ordered on disk). These choices are rigid and impact the entire cluster. In ClickHouse, theORDER BYkey (also called the primary key) physically sorts data within each partition. This is the main tool for query optimization, as it allows ClickHouse to prune massive amounts of data based on theWHEREclause.Indexing/Pruning: Redshift uses zone maps, which store the min/max value for each 1MB block of data. They help prune blocks but are not very granular. ClickHouse uses a sparse primary key index. It stores marks for every Nth row (defined by
index_granularity), allowing it to quickly find the start of a relevant data range without reading the full dataset. It also supports secondary data skipping indexes and projections for further optimization.Semi-Structured Data: Redshift uses the
SUPERdata type and the PartiQL language to handle JSON. This is flexible but can be slow. ClickHouse prefers an explicit, schema-first approach. You ingest JSON using theJSONEachRowformat, which parses fields into typed columns on write. This makes subsequent queries on that data much faster.
Area | Redshift Behavior | ClickHouse Behavior | Migration Implication |
|---|---|---|---|
Primary Goal | BI & Enterprise Warehousing | Real-time Analytics & OLAP | Shift from broad scans to low-latency, filtered aggregations. |
Data Distribution |
| Sharding data across independent nodes. |
|
Data Sorting |
|
|
|
Updates/Deletes | Heavy |
| Use |
Semi-structured |
|
| Flatten |
Scaling | Add nodes (RA3) or RPUs (Serverless). Concurrency Scaling for reads. | Add replicas (reads) or shards (writes/distributed processing). | ClickHouse offers more granular, independent scaling for reads and writes. |
Table 02: Feature Comparison Matrix
4. Data Model & Type Mapping (From Redshift to ClickHouse)
Translating a Redshift schema to ClickHouse requires rethinking how data is physically organized to match your query patterns.
Most standard data types like INTEGER, BIGINT, VARCHAR, and TIMESTAMP have direct equivalents. However, pay attention to DECIMAL precision and TIMESTAMP time zones; ClickHouse's DateTime64 with an explicit timezone is recommended. Redshift-specific column encodings like AZ64 become irrelevant. Instead, you will use ClickHouse's column-level compression codecs like ZSTD and LZ4.
The biggest structural changes come from handling Redshift's proprietary features; the SUPER type must be flattened into structured columns before loading into ClickHouse. This can be done in Redshift using PartiQL before the UNLOAD step or during an ETL transformation. The goal is to convert schemaless JSON into a well-defined set of typed columns for better query performance.
Most importantly, the DISTKEY and SORTKEY concepts must be completely re-evaluated:
The columns in your Redshift
SORTKEYare the strongest candidates for theORDER BYclause in your ClickHouse table. This is the most critical decision for ClickHouse performance.Your
DISTKEYis often a high-cardinality ID used for joins. In a clustered ClickHouse setup, this would become your sharding key.
To illustrate, below is a common Redshift table using these features:
Code Block 01: Redshift Sample Schema (DIST/SORT/SUPER)
Now, let's translate that into an idiomatic ClickHouse schema. Notice how the SUPER field is flattened, and the SORTKEY directly informs the ORDER BY clause.
Code Block 02: ClickHouse Equivalent DDL
5. Migrating the Data
This section outlines a practical, batch-oriented migration path from Redshift to ClickHouse using S3 as an intermediary. We'll break this down into 5 steps:
Inventory & Assessment (Redshift-Specific)
Extract from Redshift (Batch)
Transform for ClickHouse
Load into ClickHouse
Validate & Reconcile
5.1 Inventory & Assessment (Redshift-Specific)
Before exporting data, you need a complete inventory of your Redshift objects. The svv_ and pg_ system views are the primary tools for this discovery phase. You should catalog all schemas, tables, and views, paying close attention to view dependencies, as Redshift's late-binding views can hide logic that needs to be recreated.
The main goals here are as follows:
Analyze Table Structure: Document the
DISTKEY,SORTKEY, and column types for each table. Check forIDENTITYcolumns, as these will need a new strategy like usinggenerateUUIDv4().Assess SUPER and Spectrum Usage: Identify all tables using the
SUPERtype, as they require a flattening step. Identify any external tables using Redshift Spectrum; if their source is already S3, you can ingest that data directly into ClickHouse and bypass Redshift.Define the ClickHouse Ordering Strategy: This is your most critical task. Analyze your most frequent Redshift queries. The columns used in
WHEREclauses andGROUP BYs are the best candidates for your newORDER BYkey in ClickHouse.
The following example SQL queries can help you gather this information from your Redshift cluster:
Code Block 03: Redshift Inventory SQL
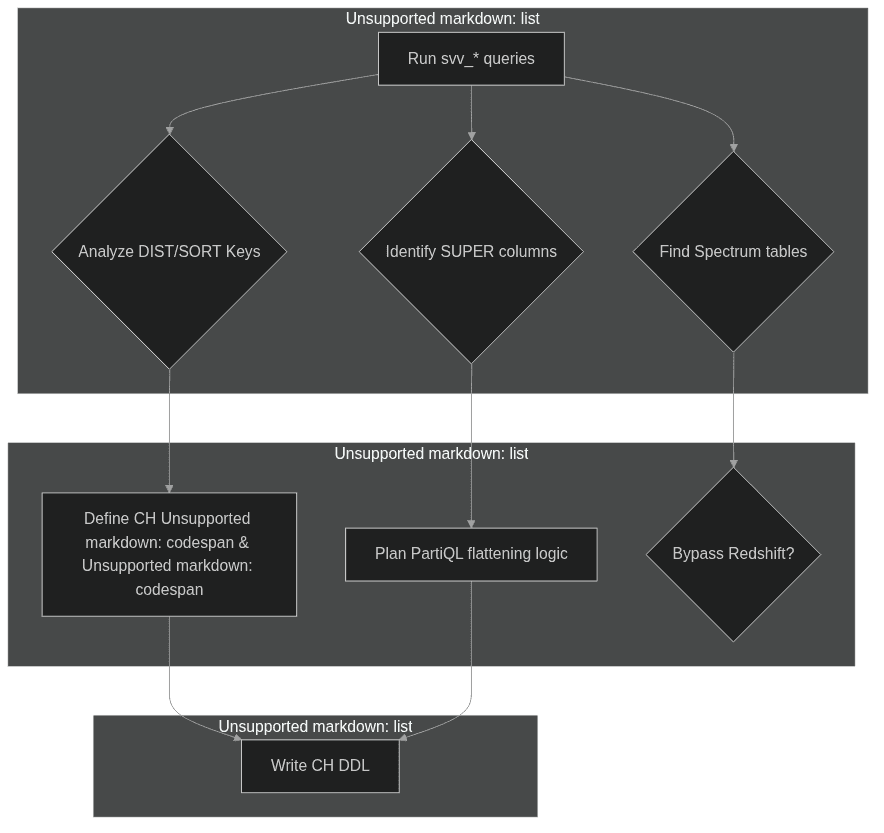
Figure 01: Inventory to Extraction to CH Schema Map
5.2 Extract from Redshift (Batch)
The most efficient way to get large datasets out of Redshift is the UNLOAD command, which writes data in parallel to S3. Parquet is the ideal format for this; it's columnar, preserves data types well, and is highly optimized for ClickHouse ingestion.
When unloading, use the PARTITION BY option to create a directory structure in S3 (e.g., s3://bucket/table/year=2023/). This helps manage the data flow and can align with ClickHouse's partitioning. For this to work, your Redshift cluster needs an IAM role with permission to write to the target S3 bucket.
Below is an UNLOAD command that exports our sample table to partitioned Parquet files.
Code Block 04: Redshift UNLOAD to Parquet (Partitioned)
After running the command, you should validate that the files were created using the AWS CLI:
Code Block 05: AWS CLI Validation
5.3 Transform for ClickHouse
This optional step is for cleaning and reshaping data before it enters ClickHouse. It is essential if you are dealing with SUPER columns or if you want to pre-sort your data for maximum ingestion performance.
If your tables contain SUPER data, you can use PartiQL syntax directly in the UNLOAD command's SELECT statement to extract nested fields into standard columns. This is often the easiest way to handle flattening, as it avoids an extra processing step.
The following example modifies the SELECT query from the UNLOAD command to perform this flattening on the fly:
Code Block 06: PartiQL Flattening of SUPER
For more complex transformations, you might perform a post-processing step on the Parquet files in S3. The most impactful optimization is to sort the data within each file to match the ORDER BY key of the target ClickHouse table. This pre-sorting drastically reduces the work ClickHouse does during its initial merge, leading to faster data availability and lower resource consumption. A simple script using a library like PyArrow can handle this, but for very large datasets, a distributed framework like Spark is more appropriate.
Code Block 07: Python: Parquet Post-Processing
5.4 Load into ClickHouse
With prepared data in S3, loading it into ClickHouse is simple. First, create the target table, which will typically use the MergeTree engine or its replicated variant, ReplicatedMergeTree, for clustered environments.
Then, you can ingest the Parquet files using the s3() table function. This function allows ClickHouse to read files directly and in parallel from an S3 bucket, making it highly efficient for bulk loading.
Below is the DDL for our events table in a clustered setup, followed by the INSERT statement to load the data from S3:
Code Block 08: ClickHouse DDL (Cluster-Aware)
Now, use an INSERT SELECT query with the s3() function. The file globbing pattern (*.parquet) allows it to read all Parquet files in the specified path.
Code Block 09: ClickHouse Ingest from S3 Parquet
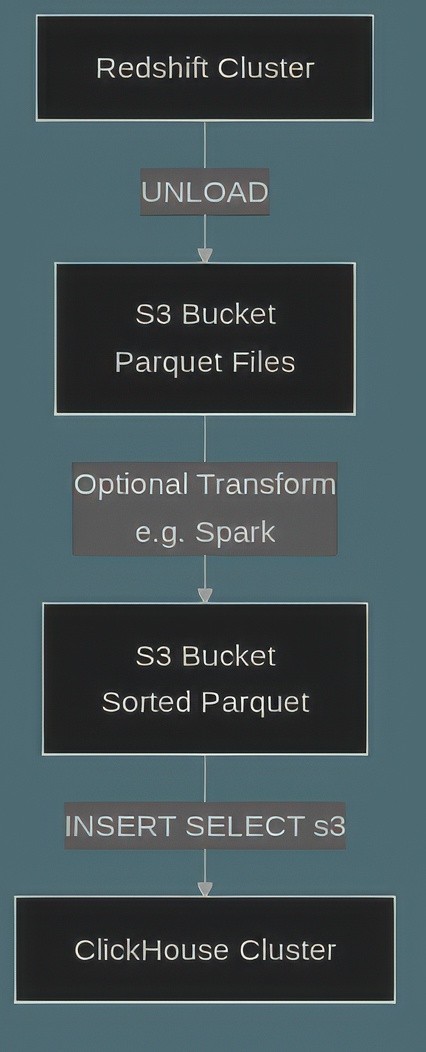
Figure 02: End-to-End Batch Path: S3 to CH
5.5 Validate & Reconcile
After loading the data, the last step is verifying its integrity. Do not skip this step. A thorough validation process ensures no data was lost or corrupted during migration.
Depending on the size of your database, this can be daunting; start with simple checks like row counts. Then, move to more detailed comparisons. Check the MIN and MAX values on key columns, especially timestamps, to ensure the full data range was migrated. For numerical columns, calculate sums, averages or more detailed statistical measures on both systems and compare the results. Finally, run a few representative business queries such as daily active users—on both Redshift and ClickHouse to confirm the results are identical.
The following queries provide a general template for these validation checks.
Code Block 10: Validation SQL (Both Sides)
Use the following table for a blueprint on which checklists to include:
Check | Redshift SQL | ClickHouse SQL | Purpose |
|---|---|---|---|
Row Count |
|
| Verify no data loss. |
Column MIN/MAX |
|
| Confirm data range integrity. |
NULL Counts |
|
| Check for discrepancies in NULL handling. |
Distinct Count |
|
| Validate cardinality. |
Business Query | Your BI query | Equivalent query in CH SQL | Ensure end-user results match. |
Table 03: Validation Checklist
6. Near-Real-Time / Streaming Option
For many use cases, a batch migration is just the first step. The goal is often to build a real-time data pipeline. A common pattern for this is to perform a one-time historical backfill from Redshift, then switch over to a streaming source like Kafka or Kinesis for ongoing data.
In this architecture, new and updated rows are streamed through a processing layer that handles tasks like deduplication, efficient batching, and schema management before inserting the data into ClickHouse. This approach avoids the performance hits from running frequent, small inserts directly against the database. Tools like GlassFlow are designed for this exact purpose, acting as a specialized streaming ETL layer between Kafka and ClickHouse. This architecture ensures idempotency and high throughput, which is critical for production systems.
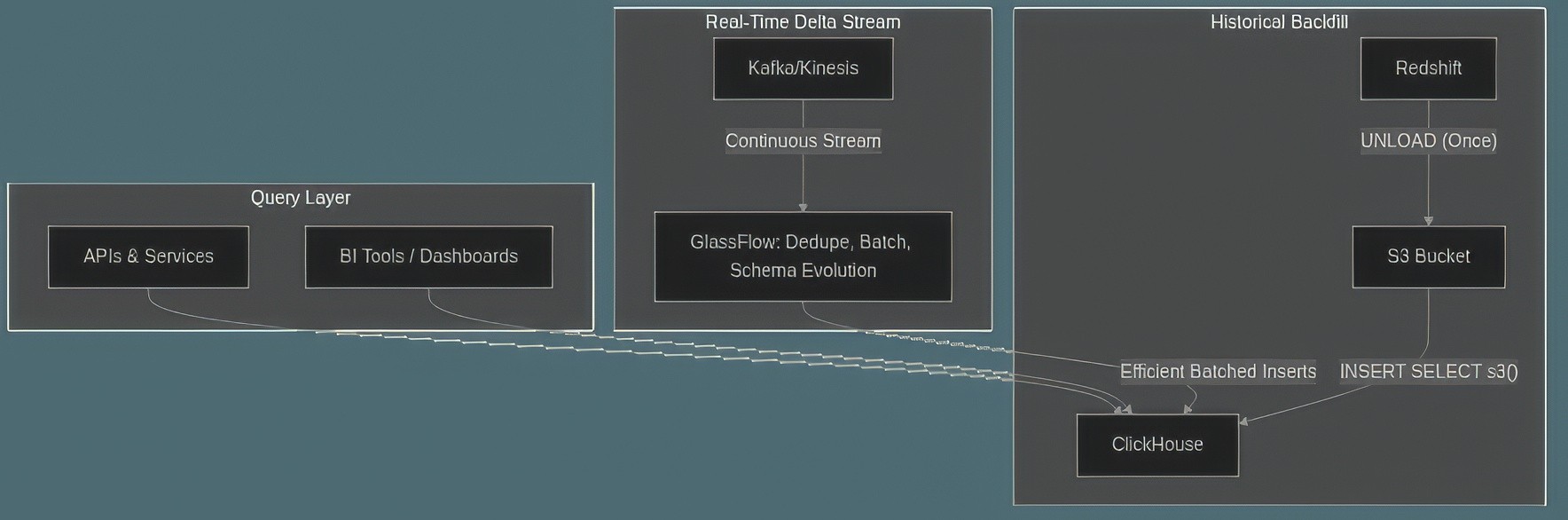
Figure 03: Real-Time Pipeline Diagram
A tool like GlassFlow can be configured with a simple file to manage this stream, ensuring data is correctly processed before it lands in ClickHouse.
Code Block 11: GlassFlow JSON: Sort + Dedupe + CH Sink
7. Optimizing for ClickHouse (Post-Load)
Once your data is in ClickHouse, you now need to optimize. ClickHouse offers a wide array of tools to fine-tune performance.
7.1 Table Design, Projections, and Materialized Views
Your initial table design is the most important factor, but you can add optimizations later. Projections are a powerful feature that pre-calculates and stores aggregations alongside your raw data. They act like a materialized index, dramatically speeding up common GROUP BY queries.
If you need to maintain aggregated data in a separate table, Materialized Views can be used. They are triggered by inserts into a source table and automatically update an aggregate target table. For CDC workloads, consider using specialized table engines like ReplacingMergeTree (which keeps only the latest version of a row based on a key) or SummingMergeTree (which automatically sums columns for rows with the same primary key).
In this example, we create a projection to accelerate queries that group by event_type:
Code Block 12: Projections & Materialized Views
7.2 Compression, Storage, and TTL
ClickHouse gives you full control over data compression and lifecycle. The default LZ4 codec is fast, but switching to ZSTD can significantly improve compression ratios at the cost of some CPU. You can set this at a column or table level.
Time-to-Live (TTL) expressions are highly relevant for managing data retention, especially for logs or event data. You can set rules to automatically delete old partitions or move them to a slower, cheaper storage tier (like S3) after a certain period.
7.3 Query Tuning & Quotas
To prevent runaway queries and ensure fair resource allocation, use ClickHouse's settings and quotas system. You can create profiles for different user roles that limit max memory usage, execution time, and threads. For exploratory queries on very large tables, encourage the use of SAMPLE to get fast, approximate results.
Here is how you might define a profile for BI users that prevents them from running overly expensive queries.
Code Block 13: Query Settings & Quotas
7.4 Monitoring
A production ClickHouse cluster requires monitoring. The system database is full of useful tables for observing the health and performance of your cluster. Key tables to watch include:
system.parts: To monitor the number and size of data parts for each table. Too many small parts can indicate merge processes are falling behind.system.replication_queue: To check for replication lag between nodes.system.merges: To observe the background merge activity.system.query_log: To analyze query performance and identify slow or failing queries.
A simple health check can query these tables to alert on potential issues.
Code Block 14: Health Checks
8. Redshift-Specific Gotchas
Migrating from Redshift involves a few specific challenges that are important to plan for:
Redshift Quirk | Problem | ClickHouse Strategy |
|---|---|---|
IDENTITY Columns | No native auto-increment feature in ClickHouse. | Use |
Late-Binding Views | Dependencies are not validated on creation, can hide broken logic. | Manually inspect view definitions ( |
| Arrays within JSON must be unnested. | Use |
Transaction Blocks | Redshift uses standard | ClickHouse has very limited transaction support. Design ingestion to be atomic and idempotent. |
Spectrum Bypass | External tables using Redshift Spectrum query S3 directly. | Investigate the original S3 data source. Often more efficient to ingest directly into ClickHouse. |
Table 04: Redshift Quirk to CH Strategy Map
9. Security & Access Control
Replicating Redshift's security model in ClickHouse requires mapping AWS-centric concepts to ClickHouse's internal RBAC system.
Authentication: Where Redshift relies on IAM users and roles, ClickHouse has its own user management system. You can configure it to use LDAP or Kerberos for centralized authentication.
Authorization: Redshift's
GRANT/REVOKEcommands on schemas and tables map directly to ClickHouse'sGRANT/REVOKEsystem. Create roles in ClickHouse that correspond to your IAM policies to manage permissions at scale.Encryption: Both systems support encryption at rest and in transit. In ClickHouse, you configure TLS for client connections and can enable disk-level encryption. For sensitive credentials, avoid storing them in SQL scripts; use the server-side configuration or a secrets manager.
Row-Level Security: Redshift uses Virtual Private Database (VPD) policies attached to users. ClickHouse has a similar concept called Row Policies, which allows you to define filter conditions that are automatically applied to
SELECTqueries for specific roles.
10. Cut-Over Strategy
A successful migration requires a careful cut-over plan to minimize downtime and risk. A phased approach is almost always the best choice.
Backfill and Dual-Write: Perform the initial batch load from Redshift to ClickHouse. At the same time, set up a dual-write process where new data is written to both Redshift and ClickHouse. For streaming workloads, this means your Kafka pipeline will sink to both databases.
Shadowing and Validation: Once the systems are in sync, redirect a portion of your read traffic (or run queries in parallel) to ClickHouse. This "shadowing" phase is critical for comparing query results, performance, and dashboards to ensure correctness without impacting users.
Cut-Over: When you are confident that ClickHouse is correct and performant, you can perform the final cut-over. This typically involves updating application connection strings or changing a DNS record to point to the new ClickHouse cluster. Keep the Redshift cluster running and receiving data for a short period to allow for a quick rollback if needed.
Decommission: After a successful cut-over period (e.g., one week), you can stop writing to Redshift and eventually decommission the cluster.
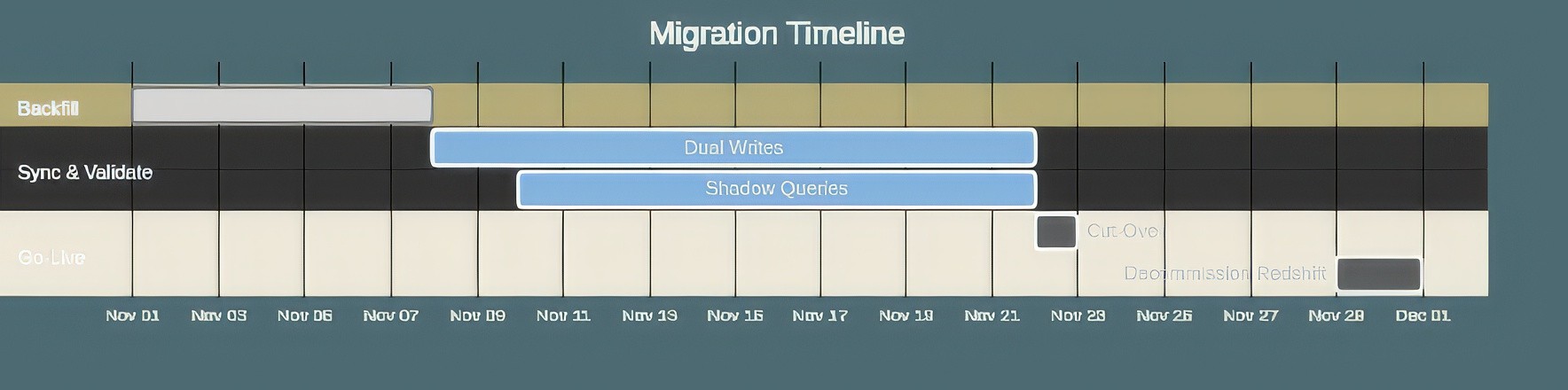
Figure 04: Timeline: Backfill to Validate to Cutover
11. Data Modeling Considerations: From Redshift to ClickHouse
As we've already discussed, a critical aspect in migrations is the difference in data modeling approaches between Redshift and ClickHouse; Redshift typically follows traditional data warehousing patterns with normalized star or snowflake schemas, and ClickHouse often performs better with denormalized, wide tables. Understanding when and how to adjust your data model is crucial for a successful migration.
Traditional Redshift Modeling vs. ClickHouse Approach
Redshift inherits many conventions from traditional data warehousing:
Star Schema: Fact tables surrounded by dimension tables, optimized for flexibility and storage efficiency.
Snowflake Schema: Further normalized star schema with dimension tables split into sub-dimensions.
Slowly Changing Dimensions (SCD): Type 2 SCDs track historical changes with effective dates.
In ClickHouse, these patterns are not the same, due to its columnar storage and query execution model:
Wide Denormalized Tables: ClickHouse is great with fewer, wider tables that minimize JOINs.
Materialized Views for Aggregations: Pre-computed aggregations replace many dimension lookups.
Dictionaries for Lookups: Efficient key-value lookups replace small dimension tables.
When to Denormalize
Consider denormalization in ClickHouse when:
Your queries frequently JOIN the same tables with stable relationships.
Dimension data changes infrequently (e.g., product categories, geographic regions).
Query latency is critical and must be sub-second.
You can afford increased storage for better query performance.
Your data pipeline can handle the complexity of maintaining denormalized data.
Below is an example transformation from Redshift star schema to ClickHouse denormalized model:
When to Keep Normalized
Maintain normalized structures when:
Dimension data changes frequently (e.g., customer profiles, inventory status).
Data consistency is crucial.
Storage costs are a main concern.
You need flexibility for ad-hoc queries across many dimensions.
Update complexity would be too much for your data pipeline.
Hybrid Approach
Often, the optimal solution combines both approaches:
Core Fact Table: Keep the main fact table with high-cardinality IDs
Denormalized Projections: Use ClickHouse Projections to create denormalized views
Dictionaries for Lookups: Replace small, stable dimension tables with ClickHouse Dictionaries
Materialized Views: Pre-aggregate common query patterns
Below is an example hybrid implementation:
Migration Strategy for Data Models
When migrating from Redshift to ClickHouse:
Start Conservative: Begin with a structure similar to your Redshift schema
Identify Hot Paths: Monitor query patterns to identify frequently accessed JOIN paths
Incrementally Denormalize: Create denormalized tables or projections for high-frequency queries
Measure and Iterate: Compare performance and storage trade-offs
Maintain Flexibility: Keep source data in a flexible format for future remodeling
Remember that ClickHouse's powerful compression often mitigates the storage overhead of denormalization. A denormalized table in ClickHouse might use less storage than a normalized structure in Redshift due to superior compression algorithms.
The key here is to think of your data differently, and not try to bring the same thought process to a new paradigm. Adjust to the new paradigm, suffer less.
12. Final Thoughts
Redshift is a great tool; a capable data warehouse for traditional BI. However, it can struggle with the demands of real-time, high-throughput analytical applications. Its scaling model can lead to unpredictable costs and its architecture is not optimized for the sub-second latencies these workloads require.
ClickHouse on the other hand, offers a powerful alternative, giving engineers precise control over performance, storage, and cost. Its design is explicitly for speed on large-scale analytical queries.
We know first hand how a migration is a significant undertaking that requires careful planning, especially around data modeling. The key is to shift your thinking from Redshift's DISTKEY/SORTKEY model to ClickHouse's PARTITION BY/ORDER BY model. This will make it way easier for you and your team to understand the gains you'll be getting with ClickHouse.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
