ljn
Migrations
Migrating from Bigquery to ClickHouse: Step-by-Step Guide
Written by
Armend Avdijaj
-

1. Introduction
Google BigQuery offers a powerful, serverless data warehouse that excels at handling large-scale, ad-hoc analytical queries. Its managed, decoupled storage and compute architecture simplifies operations, making it an attractive choice for many business intelligence and data exploration use cases. However, for teams building high-concurrency, real-time analytics applications, BigQuery's slot-based pricing model can introduce cost unpredictability and performance ceilings.
The challenge arises when user-facing applications demand consistent, sub-second query latencies. BigQuery, while fast for broad scans, is not architected to be a low-latency query engine, often exhibiting startup times that can be a deal-breaker for interactive dashboards and real-time APIs. Furthermore, the "black box" nature of its resource allocation means engineers have limited levers to pull for fine-grained performance tuning.
The goal is to achieve predictable, lightning-fast query performance at a manageable cost, especially for workloads characterized by high concurrency and repetitive query patterns. This is where ClickHouse, an open-source, performance-oriented columnar database, presents a compelling alternative. Its architecture is explicitly designed for the lowest possible query latency.
This article provides a starter migration playbook for transitioning from BigQuery to ClickHouse. We will cover architectural differences, schema translation, a step-by-step data migration workflow, and post-migration optimization strategies.
Before anything else, we need to discuss the main pain points of using BigQuery, and if and how ClickHouse addresses them:
BigQuery Pain Point | Root Cause | How ClickHouse Addresses It | Key Consideration |
|---|---|---|---|
Cost Unpredictability | Slot-based pricing for on-demand queries or reserved capacity can escalate with high concurrency. | Hardware-based cost model provides predictable expenses. Efficient resource use lowers total cost of ownership. | Requires infrastructure management or choosing a managed ClickHouse service. |
High P99 Query Latency | Serverless architecture has inherent "cold start" or resource allocation delays; not optimized for sub-second responses. | Coupled storage/compute on fast local storage (NVMe) eliminates startup delays. Designed for millisecond-level latency. | Performance is heavily dependent on thoughtful schema design, particularly the |
Operational Opacity | Resource allocation (slots) and internal optimizations are managed by Google, offering limited user control. | Provides granular control over indexing, compression, storage tiers, and query execution settings. | This control comes with the responsibility of tuning and optimization. |
Inefficient DML Operations |
| Specialized table engines ( | Requires a shift in thinking from synchronous DML to asynchronous data collapsing. |
Table 01: Migration Candidacy Checklist
2. Pain Points & Migration Triggers
The decision to migrate is often driven by a specific set of challenges that emerge as data applications mature and scale. The most prominent one is cost volatility. In BigQuery, costs are tied to data scanned (on-demand) or provisioned slots (flat-rate). For applications with many concurrent users running analytical queries, this can lead to rapidly escalating bills, making budgeting difficult.
Next is the problem of latency ceilings. While BigQuery is powerful for large-scale analytics, it is not built for consistent sub-second query performance, a critical requirement for interactive, user-facing applications. The P99 latency (the latency experienced by 99% of users) can be too high for dashboards and APIs that need to feel instantaneous.
Engineers can also face operational opacity. As a fully managed service, BigQuery abstracts away the underlying infrastructure. This convenience comes at the cost of control, limiting an engineer's ability to perform fine-grained tuning of indexing strategies, data compression, or resource allocation.
Lastly, DML inefficiency becomes a significant bottleneck for real-time workloads. Handling frequent updates and deletes, typical in Change Data Capture (CDC) pipelines, is cumbersome and expensive in BigQuery. For instance, the MERGE statement performs a heavy, copy-on-write operation that is poorly suited for streaming or high-frequency updates.
3. Architectural Differences of BigQuery vs. ClickHouse
Understanding the fundamental design philosophies of both systems is crucial for a successful migration. BigQuery uses a serverless, decoupled architecture where data resides in Google's distributed file system and compute resources (slots) are allocated on-demand from a shared pool. ClickHouse, by contrast, traditionally uses a coupled architecture where data lives on local, high-performance storage (like NVMe SSDs) on the same nodes that process queries, minimizing data transfer latency. It can, however, also use object storage like GCS, offering more flexibility.
Data organization also differs significantly. BigQuery uses PARTITION BY and CLUSTER BY to prune data and co-locate related information. In ClickHouse, the ORDER BY clause is crucial; it physically sorts data on disk and creates a sparse primary key index, which is the cornerstone of its speed. While ClickHouse also has a PARTITION BY clause, its primary role is for data management, such as dropping old partitions efficiently.
Their indexing strategies are a direct result of these organizational differences. BigQuery manages pruning automatically based on partition and cluster metadata. ClickHouse gives the developer direct control through its dense primary key index, sparse skip indexes, and projections, which act like materialized aggregations to accelerate queries.
With semi-structured data, BigQuery offers native support for STRUCT and ARRAY types, queried using functions like UNNEST. ClickHouse can handle nested data via its Nested data structures, but performance often benefits from flattening JSON into explicit, typed columns during ingestion.
Concept | BigQuery Approach | ClickHouse Approach | Migration Implication |
|---|---|---|---|
Architecture | Serverless, decoupled storage & compute. | Coupled storage & compute (with object storage options). | Shift from a fully managed service to a system requiring more hands-on tuning. |
Data Sorting |
| Mandatory | The |
Partitioning |
|
| The partitioning strategy can often be mapped directly. |
Updates/Deletes | Expensive | Efficient, asynchronous collapsing via | DML workflows must be redesigned for ClickHouse's asynchronous model. |
Nested Data |
|
| Schemas may need to be flattened during ETL for optimal performance. |
Table 02: Conceptual Differences Matrix
4. Schema and Data Model Translation
Translating your BigQuery schema to ClickHouse requires mapping of data types and a rethinking of data organization. The most critical step is translating BigQuery's CLUSTER BY keys into the ClickHouse ORDER BY clause. This decision will have the single largest impact on query performance. Similarly, BigQuery's time-based PARTITION BY clause can be mapped directly to ClickHouse's PARTITION BY.
For data types, most scalar types have direct equivalents. BigQuery STRUCTs can be deconstructed into flattened columns in ClickHouse for better performance or mapped to Nested data structures if the nested relationship is essential for queries.
BigQuery Type | ClickHouse Recommended Type(s) | Notes |
|---|---|---|
|
| Use |
|
| |
|
| |
|
|
|
|
| Specify precision and timezone explicitly. |
|
| |
|
| Match precision (P) and scale (S) to your data. |
| Flattened Columns or | Flattening is often more performant. |
|
| Maps directly to ClickHouse arrays. |
Table 03: BigQuery to ClickHouse Type Mapping Guide
To illustrate, let's look at a typical BigQuery DDL for an events table that uses partitioning, clustering, and nested data:
The equivalent, optimized ClickHouse DDL would flatten the STRUCT and use the CLUSTER BY keys for the ORDER BY clause. This schema prepares ClickHouse to answer queries filtered by user_id and event_type with maximum speed.
5. A Step-by-Step Migration Pipeline
We suggest a structured, five-step process for migrating from BigQuery to ClickHouse: auditing the source, extracting the data to GCS, preparing it for optimal ingestion, loading it into ClickHouse, and finally, verifying data parity.
5.1. Auditing the Source
First, catalog your existing BigQuery assets using its INFORMATION_SCHEMA. This allows you to identify all tables, views, and nested structures that need to be migrated. It is also crucial to identify tables with high DML rates, as these will require a specialized engine like ReplacingMergeTree in ClickHouse to handle updates or deletes.
The following queries help inventory your tables and specifically find those with nested data structures that require special handling:
5.2. Extraction: Exporting from BigQuery to GCS
The most efficient way to export large datasets from BigQuery is using the EXPORT DATA command, which unloads data to Google Cloud Storage (GCS). Parquet is the ideal format as it is columnar, compressed, and highly compatible with ClickHouse. Aligning the export partition strategy with your target ClickHouse partition key can simplify the ingestion process.
This command exports the user_events table into partitioned Parquet files in a GCS bucket:
5.3. Preparation: Optimizing Data for Ingestion
For maximum ingestion performance, the Parquet files in GCS should be sorted by the ClickHouse ORDER BY key before loading. This pre-sorting drastically reduces the merge overhead on the ClickHouse server, as the data is already in the desired physical order. This can be done using a Python script with the PyArrow library. While this script is effective, converting a large dataset to a single in-memory table (dataset.to_table()) can cause out-of-memory errors. For production workloads involving terabytes of data, this sorting and flattening step should be performed using a distributed processing framework like Apache Spark or Dask.
The script below reads the exported data, flattens the nested properties struct, and sorts the data according to the target ClickHouse ORDER BY key:
5.4. Ingestion: Loading into ClickHouse
Once the data is prepared, flattened, and sorted in GCS, you can load it directly and in parallel into your pre-created ClickHouse table using the s3 table function (which is compatible with GCS).
This INSERT statement reads the transformed Parquet files from GCS and loads them into the user_events table in ClickHouse:
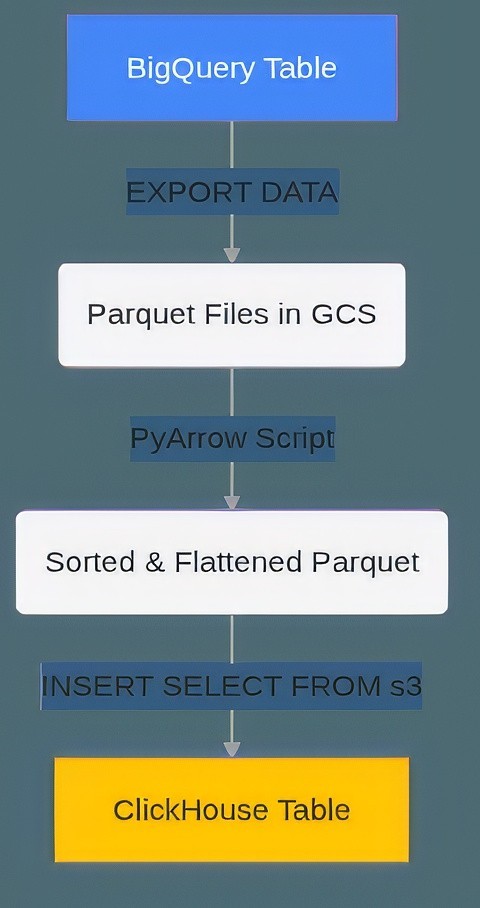
Figure 01: Batch Data Migration Flow Diagram
5.5. Verification: Ensuring Data Parity
After ingestion, it is critical to validate that the data in ClickHouse matches the source in BigQuery. This can be done by comparing row counts, checksums on numeric columns, and boundary checks (MIN/MAX) on key columns like timestamps. Running a suite of equivalent business-critical queries on both platforms is the final step to ensure both functional and performance parity.
These validation queries should be run on both BigQuery and ClickHouse to compare their results:
6. Real-Time Ingestion
A complete migration strategy must account for ongoing, real-time data. The typical approach is a hybrid one: use the batch method described above for the initial historical backfill, and then establish a streaming pipeline for new events. This pipeline would route new events from a source like Pub/Sub or Kafka through a stream processing layer. This layer, which could be a service like GlassFlow, Cloud Functions, or a custom application, is responsible for micro-batching events before inserting them into ClickHouse. This architecture bypasses BigQuery's costly streaming inserts and inefficient DML operations, creating a truly real-time data flow.
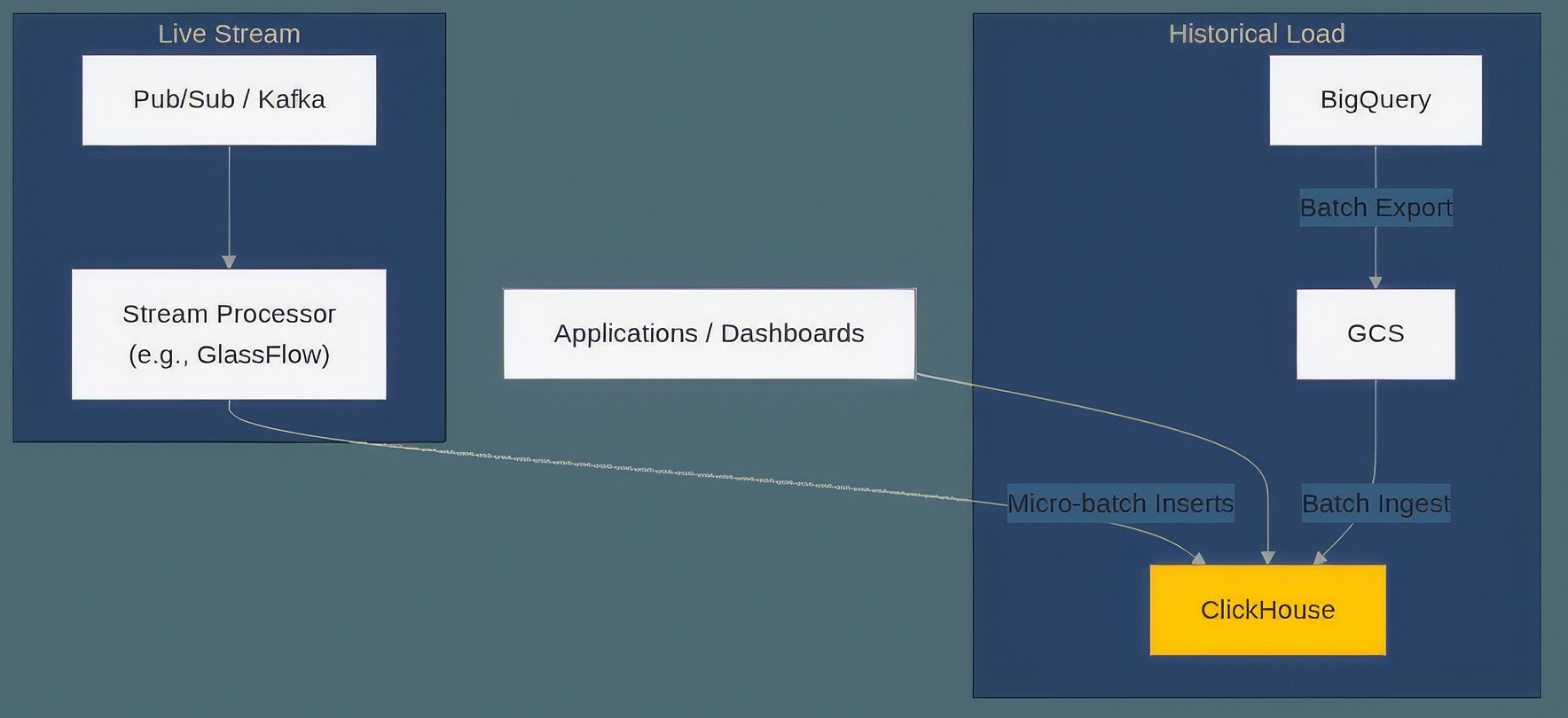
Figure 02: Streaming Architecture for Live Data
7. Post-Migration
Once your data is in ClickHouse, you can unlock further performance gains through its advanced features. Projections can pre-calculate and store common aggregations alongside your raw data, acting like materialized indexes that dramatically speed up dashboard queries. If you need to maintain aggregated data in a separate table, Materialized Views can be triggered by inserts to automatically update an aggregate target table.
You can also fine-tune storage and I/O by setting column-level compression codecs like ZSTD for better compression or LZ4 for faster decompression. Finally, implementing TTL (Time-to-Live) policies allows you to automatically delete aging data or move it to colder, cheaper object storage, effectively managing your data lifecycle.
These examples show how to add a projection for faster aggregations and how to set a TTL to manage data retention:
8. Common Migration Pitfalls & Solutions
Going through the architectural differences between BigQuery and ClickHouse can present several challenges. A common one is attempting to emulate DML. Simple: do not try to replicate BigQuery's synchronous MERGE statements. Instead, completely embrace ClickHouse's asynchronous model by using ReplacingMergeTree or CollapsingMergeTree table engines, which handle deduplication and updates efficiently in the background.
Another challenge is handling nested schemas. The UNNEST pattern common in BigQuery queries must be refactored. The most performant approach in ClickHouse is to flatten schemas during the ETL phase, creating a wider, more explicit table structure.
Finally, avoid relying on defaults. Success in ClickHouse requires deliberate schema design. Unlike BigQuery's more automated approach, the ORDER BY key is the single most important decision you will make for query performance. Choose it carefully based on your most common query filter conditions.
Problem | Common (but Incorrect) Approach | Recommended ClickHouse Solution |
|---|---|---|
Handling record updates | Running frequent | Use the |
Querying nested data | Storing raw JSON in a | Flatten the JSON structure into typed columns during ingestion for dramatically faster queries. |
Designing the primary key | Using a unique | Use low-cardinality columns from common |
Table 03: Problem & Solution Map
9. Executing the Cut-Over
A successful migration requires a careful, phased cut-over plan to minimize downtime and risk:
Phase 1: Dual Writes: First, perform the historical backfill. Then, implement a streaming pipeline that writes all new data to both BigQuery and ClickHouse simultaneously. This ensures both systems are kept in sync.
Phase 2: Shadowing: Begin routing a portion of read traffic from internal tools or a canary user group to the ClickHouse cluster. This phase is critical for validating stability, performance, and correctness under a real production load without impacting external users.
Phase 3: Go-Live: Once you are confident in the ClickHouse cluster's performance and stability, remap your primary applications and BI tools to the ClickHouse endpoint. It is wise to maintain the BigQuery pipeline as a short-term fallback for a week or two before decommissioning.
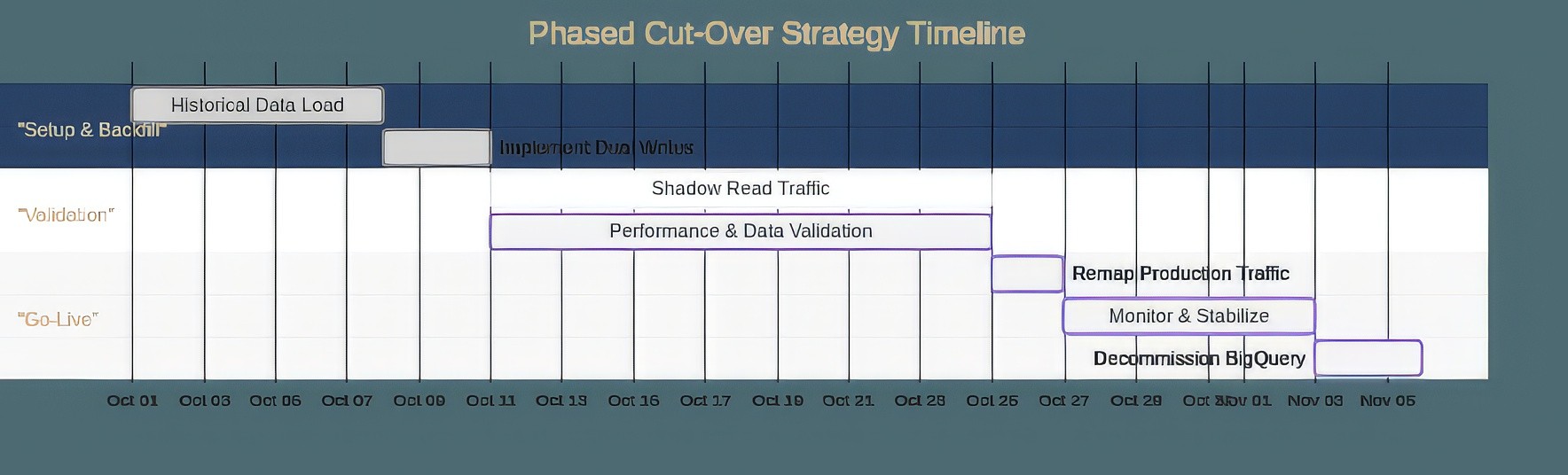
Figure 03: Phased Cut-Over Strategy Timeline
10. Final Thoughts
Migrating from BigQuery to ClickHouse can present a lot of advantages; you're going from a managed, serverless model to a performance-first, controlled environment. This transition represents a change in operational philosophy. The primary gains are predictable low-latency performance at high concurrency and a more transparent, often lower, cost structure, especially for real-time analytical workloads. Of course, this comes at the cost of initially investing more time in fine-tuning your schema to your exact requirements.
Success will not come out of the blue; it is dependent on a careful redesign of the data model centered around the ClickHouse ORDER BY key. If you're willing to embrace the architectural differences and plan the migration methodically, you will be able to build and operate user-facing analytics applications that are both incredibly fast and cost-effective.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
