ljn
ClickHouse Learnings
Managing AI backfills safely in ClickHouse clusters.
Written by
Armend Avdijaj
-

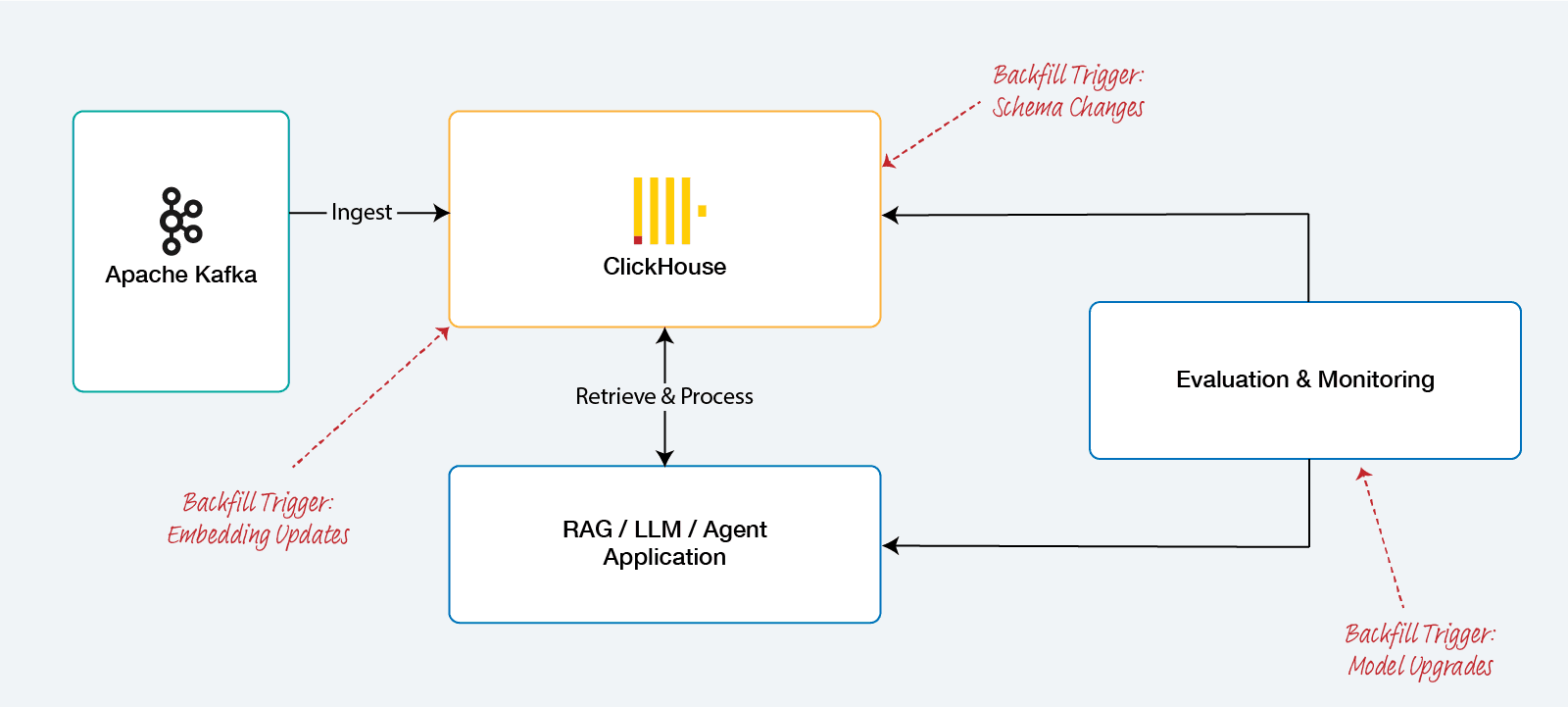
The transition from deterministic software systems to those governed by artificial intelligence has fundamentally reframed the role of the data backfill. In the legacy landscape of data engineering, a backfill was synonymous with a failure in the pipeline—a reactive measure to address data gaps, rectify logic errors in extract-transform-load (ETL) routines, or recover from upstream availability issues. However, within the lifecycle of AI systems, particularly those relying on high-dimensional vector search, large language models (LLMs), and autonomous agentic workflows, the backfill is no longer an edge case. It is, instead, the primary engine of iterative progress. As embedding models are upgraded, retrieval-augmented generation (RAG) strategies refined, and evaluation benchmarks evolved, the necessity to reprocess historical data through updated computational logic becomes a routine operational requirement. ClickHouse, with its industry-leading query speeds and columnar efficiency, has emerged as a preferred destination for these workloads, yet it introduces unique complexities regarding consistency and resource management that necessitate a nuanced understanding of its internal mechanics.
In AI systems backfills aren’t a failure mode, they’re how progress happens.
What is Backfills in ClickHouse Pipelines
In a ClickHouse-centric data ecosystem, a backfill refers to the retroactive ingestion or reprocessing of historical data into a target table, often involving the re-population of dependent materialized views. This process generally initiates at the ingestion layer, where data is sourced from durable storage, such as Amazon S3, or replayed from a message bus like Apache Kafka. Because ClickHouse is optimized for append-only workloads on immutable data parts, the act of "inserting" historical data into a table that already contains a production dataset is not a simple append operation; it is a disruptive event that triggers background merges, increases metadata pressure, and competes for CPU and I/O resources.
The mechanisms through which these backfills occur are diverse and determined by the volume and structure of the data. For smaller datasets, a standard INSERT INTO... SELECT query may suffice, utilizing ClickHouse’s internal functions to pull data from a staging table or an external source. For massive datasets, engineers often leverage partition manipulation, utilizing the physical separation of data on disk to replace entire blocks of time without scanning every row in the table. The technical complexity of these operations arises from the fact that ClickHouse does not support traditional transactional updates across parts; therefore, ensuring that a backfill is both atomic and consistent requires a deliberate architectural pattern rather than reliance on database-level locks.
Backfill Mechanism | Technical Implementation | Primary Risk |
|---|---|---|
Bulk Insert | Standard | Resource contention and partial write inconsistency. |
Partition Exchange |
| Schema divergence between source and target. |
Mutation |
| Massive write amplification and disk I/O saturation. |
Local Processing | Use of | Operational complexity in distributed environments. |
The Deceptive Safety of Reprocessing
Data engineers often find that backfills in ClickHouse feel inherently safe during initial development because of the database's remarkable throughput. In a vacuum, ClickHouse can ingest millions of rows per second, making the prospect of re-running a month of data seem trivial. This perception, however, is a dangerous abstraction that persists only until the backfill encounters the realities of a production cluster. The true risk of a backfill is not the speed of the insert, but the resulting state of the MergeTree background processes.
ClickHouse writes data into immutable "parts." As new parts arrive, a background scheduler merges them into larger parts to optimize for read performance. A high-velocity backfill generates a massive surge of small parts in a very short duration. If the merge scheduler cannot consolidate these parts faster than they are being created, ClickHouse will throw a "Too many parts" error and intentionally block all further insertions into the affected table. In a production environment, this means the backfill can inadvertently shut down the live ingestion stream, creating a critical outage. Furthermore, the system must handle the "Quiet Failure" mode, where a backfill succeeds at the network level but fails to produce a consistent dataset due to duplication or ordering conflicts that only become apparent during downstream analytics.
The Technical Triplets of Backfill Failure
When a backfill operation goes wrong in a ClickHouse environment, the root cause almost invariably falls into one of three categories: duplication, ordering and partial writes, or schema mismatches.
Duplication and the Eventual Correction Problem
Duplication is the primary hurdle when replaying events from Kafka or S3. Because these sources typically operate on "at-least-once" delivery, any network interruption or consumer offset reset results in overlapping data. Data engineers frequently attempt to mitigate this by using the ReplacingMergeTree engine, intending to keep only the latest version of a record.
The critical technical trap here is twofold. First, Deduplication is limited to the Sorting Key: ClickHouse doesn't have a unique constraint system. It only deduplicates rows that share an identical ORDER BY (Sorting Key). If your backfill process inadvertently alters a column included in the sorting key (e.g., a millisecond shift in an event timestamp), ClickHouse will treat it as a distinct entity, rendering ReplacingMergeTree useless for deduplication.
Finally, the "Eventually" Consistency Gap: Deduplication is an asynchronous background process that occurs only during merges within a specific data part or partition. Consequently, an AI evaluation table being backfilled will show inflated metrics—such as doubled row counts or skewed vector averages—until merges are complete. While the FINAL modifier can force a read-time merge, the computational overhead on billions of rows often collapses query performance, defeating the purpose of using a high-performance OLAP system for real-time AI feedback loops.
Ordering, Partial Writes, and Keeper Consensus
ClickHouse is built for speed, not for strict transactional integrity across multiple data parts. When a massive INSERT SELECT operation fails due to a memory limit violation or a node restart, the system does not roll back the entire transaction. Instead, some blocks of data may have already been written to the disk and registered in ClickHouse Keeper (or ZooKeeper), while others were lost.
This leaves the engineer with "partial writes," a state where the table contains an unpredictable subset of the backfilled data. Detecting these inconsistencies is notoriously difficult because ClickHouse does not natively track the "completeness" of a bulk insert across multiple parts. Resuming the backfill without identifying exactly where it failed leads to overlapping data, while starting over without cleaning the partial writes creates massive duplication. To manage this, engineers must implement idempotency tokens or use the "Shadow Table" pattern, where the backfill occurs in a separate, isolated table before being swapped into production via a metadata operation.
Schema Evolution and Data Incompatibility
The iterative nature of AI development necessitates frequent schema changes. Adding a new feature, such as a "sentiment_score" or an "embedding_version" tag, requires the target table to support the new column. If a backfill is initiated using an updated ingestion script into a table with an old schema, the insert will fail with a "Type mismatch" or "Unknown column" error.
More complex is the problem of modifying existing columns. In ClickHouse, changing a column’s data type is implemented as a "mutation". Mutations are asynchronous and involve rewriting every part on the disk that contains the affected column. If a backfill is running concurrently with a mutation, the disk I/O saturation can be catastrophic, leading to a complete stall of the ingestion pipeline and extreme query latency for end-users.
AI Systems: Amplification of Backfill Risk
While backfilling is a general data engineering challenge, AI systems introduce specific constraints that amplify the risks and costs of reprocessing. These constraints are rooted in the sensitivity of model evaluations, the incompatibility of vector embeddings, and the necessity of historical comparability.
Reprocessing and Evaluation Sensitivity
AI systems are inherently sensitive to input quality; the "garbage in, garbage out" principle is particularly acute in RAG and agentic workflows. When a team updates a retrieval strategy or moves to a more sophisticated reasoning model, they must evaluate the new logic against historical data. This requires backfilling historical traces and spans into evaluation-specific tables.
If the backfill process itself is flawed—introducing duplicates or dropping edge-case interactions—the resulting evaluation metrics, such as Normalized Discounted Cumulative Gain (nDCG) or Contextual Precision, will be fundamentally misleading. In an environment where a 2% improvement in recall justifies a model upgrade, the noise introduced by a sloppy backfill can hide regressions or provide a false sense of progress.
Embedding Model Updates and the Re-indexing Burden
The most resource-intensive backfill in an AI pipeline is the re-embedding of a document corpus. Because embedding vectors are tied to the specific mathematical space of the model that generated them, they are not interoperable across model versions. Switching from an OpenAI text-embedding-ada-002 model to a newer text-embedding-3-small model requires every historical document in ClickHouse to be re-embedded and the vector column updated.
Model Component | Backfill Requirement | Operational Impact |
|---|---|---|
Embedding Model | Total re-embedding of corpus. | Extreme API/GPU cost and I/O-bound re-indexing. |
Vector Index (HNSW) | Complete graph rebuild. | Massive RAM consumption proportional to |
Quantization (QBit) | Bit-plane transposition. | SIMD-intensive data transformation on disk. |
Building an HNSW index in ClickHouse is a heavy operation. The memory requirement for the index is calculated by summing the storage for the vectors themselves and the memory needed for the in-memory graph structure :
$$
Memory_{HNSW} = (N \times D \times Size_{Float}) + (N \times M \times 4 \times 2)
$$
Where $N$ is the number of vectors, $D$ is dimensionality, and $M$ represents the maximum connections per layer. For a dataset of 10 million vectors with 1,536 dimensions, this can reach 80+ of RAM. Executing this as a backfill mutation on a live cluster often triggers OOM kills unless the cluster is significantly over-provisioned or the backfill is isolated to a dedicated replica. Note: you can learn more about the calculation at ClickHouse documentation.
Deep Dive: The 100GB Memory Spike
Raw Data: 10M vectors stored as 32-bit floats = ~61GB.
HNSW Graph Overhead ($M$): To enable fast searching, ClickHouse builds a graph. With a production-standard $M=32$ (the number of bi-directional links per vector), the pointers and hierarchical layers add 6-10GB.
Operational Buffer: Between alignment, indexing buffers, and OS caching, you need a 80+GB RAM footprint to avoid an OOM (Out of Memory) crash during construction.
The QBit Solution and its Constraints
To address the rigidity of vector backfills, ClickHouse developed the QBit data type, which stores floating-point numbers as bit planes. This enables "dynamic quantization," where the engineer can specify the precision (number of bits to read) at query time without needing to re-embed the data or change the schema. While QBit provides long-term flexibility, the initial transition to this format still requires a massive backfill that utilizes AVX-512 intrinsics to transpose the data from standard arrays into bit-level storage.
The Agentic AI Multiplier: Traces and State
Agentic systems, which use multiple AI agents to pursue goals through role-based orchestration, introduce a fourth dimension to backfilling: session-based state and trace integrity. Unlike a traditional log where each row is independent, an AI agent's data is a chain of cause and consequence.
Trace Datasets and Span Linking
Backfilling agentic data requires the reconstruction of "traces"—step-by-step records of reasoning, tool usage, and recovery behavior. In ClickHouse, this is typically stored in a schema where each "span" (an individual unit of work) is a row linked by a TraceId.
A failure in the backfill that results in a "partial trace"—where the agent's initial plan is present but the final outcome is missing—renders the entire interaction useless for forensic analysis or model training. Data engineers must ensure that backfills preserve the temporal ordering of these spans, often requiring complex ASOF JOIN operations to link spans with their relevant environment metadata at the exact millisecond they occurred.
State Snapshots and SQLite Persistence
Modern agent frameworks often utilize state snapshots to allow agents to resume from interruptions. When backfilling this state into ClickHouse for analytics, engineers must handle structured JSON objects that represent the agent’s internal "memory".
Some architectures, such as AgentFS, use SQLite files to store agent state because they are portable and queryable. Backfilling these into a centralized ClickHouse instance requires a specialized bridge that can parse the SQLite binary, flatten the state transitions, and convert the JSON patches into a columnar format suitable for aggregation.
State Type | Management Strategy | Backfill Challenge |
|---|---|---|
Short-term Memory | JSON patches or in-memory deltas. | Reconstructing chronological order from late-arriving events. |
Long-term Memory | Vector embeddings in ClickHouse/Redis. | Re-embedding and indexing to maintain semantic continuity. |
Operational State | SQLite snapshots or Key-Value stores. | Bridging row-based state into columnar analytical tables. |
Common Failure Patterns in Initial Backfill Attempts
When data engineers first encounter the need for a ClickHouse backfill, they often rely on traditional database habits that fail under the unique constraints of OLAP architectures.
The Naive INSERT SELECT
The most common first attempt is to execute a large INSERT INTO table SELECT * FROM staging. While this is syntactically correct, it is operationally disastrous at scale. In a ClickHouse cluster, a heavy SELECT query will consume every available CPU core and saturate the disk I/O to maximize throughput. If the cluster is serving live user traffic, the production queries will stall, leading to application timeouts. Furthermore, if the query fails after six hours of execution, the engineer has no built-in mechanism to determine which data blocks were committed, resulting in a corrupted dataset that is almost impossible to clean manually.
The POPULATE Keyword Illusion
ClickHouse provides the POPULATE keyword during the creation of materialized views to process existing data in the source table. This is frequently marketed to beginners as the standard way to "backfill" a view.
However, POPULATE is not atomic and does not handle concurrent inserts. Any data that lands in the source table while the POPULATE query is running will be missed by the view, leading to a permanent discrepancy between the source and the aggregate. In large-scale systems, the POPULATE query is also unthrottled and can consume so much memory that it crashes the server, with no way to resume the operation from where it left off.
Manual Part Manipulation without Staging
Sophisticated engineers often try to bypass the SQL layer by manually copying data parts across the filesystem. While this avoids the overhead of the INSERT query, it creates a massive "metadata explosion" in ClickHouse Keeper. Registering thousands of new parts simultaneously can overwhelm the consensus mechanism of the cluster, leading to "Read-only table" errors or node divergence.
The Blueprint for Safe and Resilient Backfills
Executing a successful backfill in ClickHouse requires a shift from "Direct Edit" thinking to "Shadow Table" architectures. This ensures isolation, atomicity, and efficient resource allocation.
Step 1: Isolation through the Shadow Table Pattern
The primary requirement for a safe backfill is to avoid writing directly to the production table. Instead, the engineer creates a "Shadow Table"—an identical copy of the production table with a temporary suffix (e.g., events_v2_backfill).
Schema Alignment: Ensure the shadow table has the exact same structure, partitioning key, and sorting key as the target.
Isolated Population: Ingest the historical data into this shadow table. Because this table is not being queried by users, the engineer can push the system to its limits, utilize higher thread counts, and ignore the impact on query latency.
Data Quality Validation: Once the ingestion is complete, the engineer can run validation queries—checking row counts, sum totals, and schema conformance—without any risk to the production environment.
Step 2: Atomic Cut-over with EXCHANGE TABLES
Once the shadow table is validated, the "Direct Edit" approach would suggest copying the data into production. The "Resilient" approach uses EXCHANGE TABLES. This is a metadata-only operation that renames the tables on the underlying filesystem in a single atomic step.
SQL
This operation happens in milliseconds and ensures that application queries never see a "half-baked" state of the data. If the backfill contains errors discovered later, the old data is still available in the (now renamed) shadow table for immediate restoration.
Step 3: Materialized View Synchronization
Backfilling materialized views is uniquely difficult because views only trigger on new inserts. If you simply move parts into a source table, the dependent views will remain empty.
The resilient workflow for views is:
Pause ingestion to the production source table.
Create a temporary staging table to hold the new live data.
Execute the backfill into a new aggregate table for the view.
Once the backfill is complete, create the new materialized view with a
WHEREclause that starts at the current timestamp, ensuring no overlap with the backfilled data.Atomically swap the view targets and resume ingestion.
The Role of Specialized Stream Processors: GlassFlow
In modern AI data stacks, managing the complexity of deduplication and temporal joining within ClickHouse or custom Python consumers often becomes an unscalable technical debt. This is the operational gap filled by specialized stream processing engines like GlassFlow.
Pre-Ingestion Deduplication and "Exactly-Once" Semantics
The most significant contribution of GlassFlow to the backfill process is its ability to perform deduplication upstream of ClickHouse. By utilizing a built-in state store with a configurable lookback window (up to 7 days), GlassFlow ensures that only unique events are sent to ClickHouse. This eliminates the need for ReplacingMergeTree on the database side, allowing the engineer to use the simpler and faster MergeTree engine and avoiding the resource-heavy FINAL modifier.
Stateful Transformations and Temporal Joins
AI backfills often require joining disparate streams—for example, joining a "user_query" stream with a "model_trace" stream that arrived several minutes later. GlassFlow handles these temporal joins in-memory, matching records across streams and producing an enriched, flattened JSON object ready for ClickHouse. This "denormalization at ingestion" strategy is the only way to maintain sub-second query performance in ClickHouse when dealing with complex AI session data.
Reliability and the Dead-Letter-Queue (DLQ)
Backfills are prone to "loud failures"—unhandled exceptions caused by corrupted historical records or unexpected data formats. In a standard pipeline, one bad record can stall the entire Kafka consumer. GlassFlow utilizes a Dead-Letter-Queue to automatically isolate these faulty events, allowing the rest of the backfill to proceed uninterrupted. Engineers can then inspect the isolated records, update the transformation logic, and reprocess the failures without re-running the entire terabyte-scale backfill.
Practical Optimization Benchmarks for Backfill Operations
For data engineers tasked with executing these operations, ClickHouse offers several internal tuning knobs that can drastically reduce backfill duration and resource impact.
Balancing Parallelism and Resource Contention
By default, ClickHouse is an "all-you-can-eat" engine; it will consume all available resources for a single query to return the result as fast as possible. For a background backfill, this is a misconfiguration.
Parameter | Backfill Optimization | Rationale |
|---|---|---|
| Lower to 25% of cores. | Prevents the backfill from starving production queries of CPU. |
| Limit to 2–4. | Reduces the rate of part creation to avoid the "Too many parts" limit. |
| Set to 60–80% of RAM. | Prevents a single heavy backfill query from triggering a system-wide OOM. |
| Set to 0 (unlimited). | Ensures a long-running backfill doesn't timeout due to slow source I/O. |
Tuning Block Sizes for Columnar Efficiency
The most effective way to reduce the load on the ClickHouse merge scheduler is to increase the size of the ingested blocks. In standard streaming, blocks are small to minimize latency. In a backfill, latency is secondary to throughput.
Engineers should increase min_insert_block_size_rows to 1,000,000 or higher and min_insert_block_size_bytes to 1 GB. This forces ClickHouse to buffer more data in memory before writing it to the disk, resulting in fewer, larger parts that require significantly less background merging.
The Dedicated Backfill Replica Strategy
In high-stakes environments, the most resilient strategy is the use of a dedicated backfill replica.
Detach and Spin-up: Spin up a new ClickHouse node as a temporary replica of the production cluster.
Isolated Workload: Point the backfill ingestion entirely at this replica. It will consume its own CPU and memory without affecting the production nodes serving user dashboards.
Synchronization: Once the backfill is complete, the replica will naturally synchronize the new parts to the other nodes via the
ReplicatedMergeTreemechanism, which throttles the transfer to prevent bandwidth saturation.
Conclusions
The shift toward AI-centric data architectures has turned the backfill from a repair mechanism into a fundamental developmental workflow. Success in this paradigm is not defined by the speed of ingestion, but by the resilience of the architecture to continuous, high-volume reprocessing.
The essential findings of this analysis indicate that:
Immutability must be respected: Attempting to "update" data in ClickHouse is a high-cost operation. The "Shadow Table" pattern is the only scalable way to manage schema evolution and logic changes.
Deduplication should be an upstream process: Relying on database-level eventual consistency (
ReplacingMergeTree) creates analytical noise and resource bottlenecks. Upstream engines like GlassFlow provide the "Exactly-Once" guarantees necessary for rigorous AI evaluation.Vector Search requires specialized handling: The re-indexing of HNSW graphs and the transition to
QBitprecision tuning are the most resource-intensive operations in the AI lifecycle. They must be managed through dedicated replicas and SIMD-optimized transformations.
For the data engineer, the primary next step is an audit of the current ingestion pipeline for idempotency. Every part of the stack, from the Kafka consumer to the ClickHouse schema, must be designed to process the same record multiple times without altering the analytical outcome. Only by mastering the "Safe Backfill" can an organization move at the speed of the models themselves, ensuring that the data serving the AI is as evolved as the intelligence it powers.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
