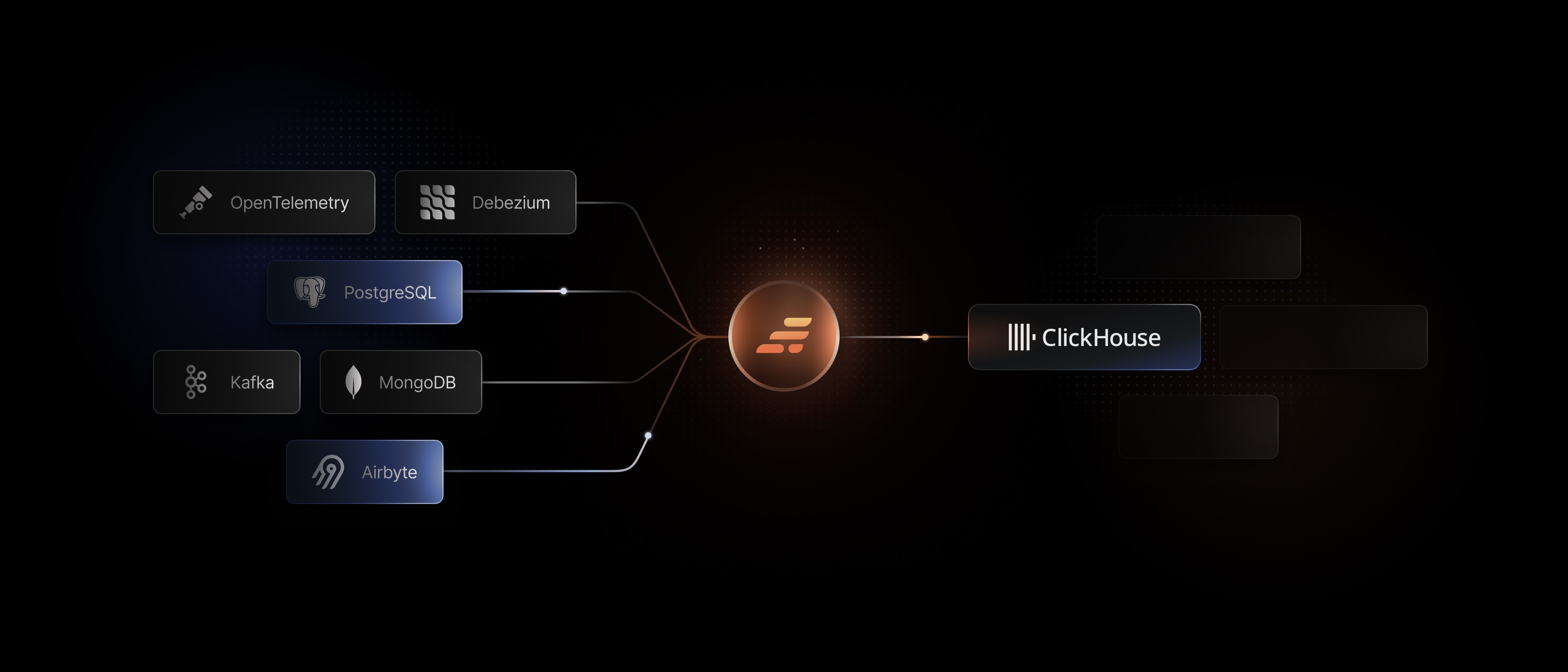
Ingest your data
into ClickHouse from day one
Backfill historical data, keep CDC in sync, handle schema changes, normalize messy data, and keep ClickHouse queries correct.

The Problems
Most ClickHouse projects break
in the first 30 days
ClickHouse queries are fast but getting correct data into ClickHouse is the hard part. Most teams face these issues:
Historical backfills are painful
You need old PostgreSQL, MySQL, or MongoDB data in ClickHouse before your analytics are useful. But historical imports usually break when live updates start.
Keeping ClickHouse continuously synced from Postgres WAL, MySQL binlog, MongoDB, or Debezium quickly becomes messy. Teams end up maintaining custom glue code.
CDC becomes fragile
Historical imports and CDC running together create race conditions. Older rows overwrite newer state. Your analytics become inconsistent.
Backfills overwrite live updates
Data plane and. control plane separated. We manage upgrades, orchestration, reliability, and operations while your data stays in your infrastrucure.
CDC becomes fragile
Data plane and. control plane separated. We manage upgrades, orchestration, reliability, and operations while your data stays in your infrastrucure.
CDC becomes fragile
Data plane and. control plane separated. We manage upgrades, orchestration, reliability, and operations while your data stays in your infrastrucure.
CDC becomes fragile
Data plane and. control plane separated. We manage upgrades, orchestration, reliability, and operations while your data stays in your infrastrucure.
CDC becomes fragile
Data plane and. control plane separated. We manage upgrades, orchestration, reliability, and operations while your data stays in your infrastrucure.
How GlassFlow Solves It
Built specifically to solve ClickHouse
ingestion pains
GlassFlow sits between your sources and ClickHouse. Problems are resolved upstream, not patched downstream.
01
Safe Historical Backfills
Data plane and. control plane separated. We manage upgrades, orchestration, reliability, and operations while your data stays in your infrastrucure.
02
Metrical backfills are painful
03
Safe historical and live sync
04
Schema evolution
05
Data Normalization
06
Multiple Connectors
07
Deduplication
08
Optimized Ingestion

Why GlassFlow
Purposely-built for
ClickHouse Ingestion
General-purpose ETL tools are great at moving data.
ClickHouse ingestion is different.
Generic ETLs
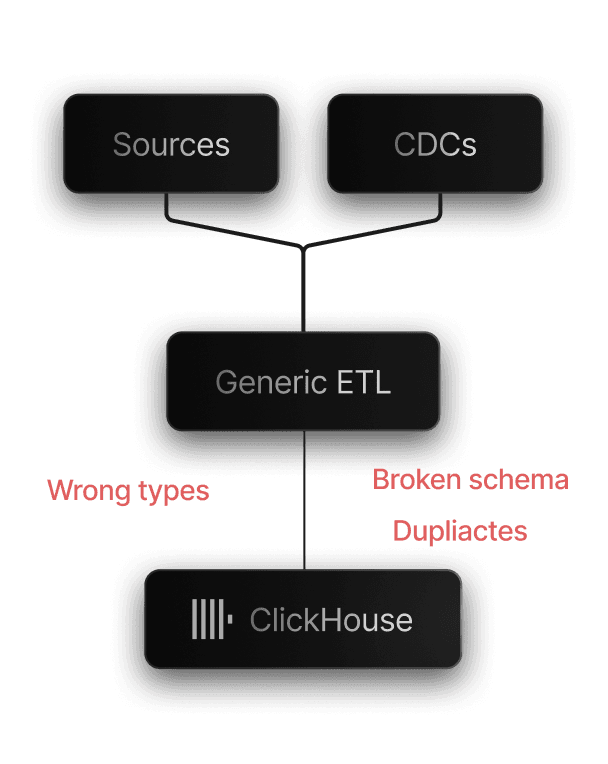
Fix after data arrived

Data arrives in the right shape
Built for teams ingesting 10TB to 100TBs per day.
Scalability
Start simple.
Scale when you need it.
10x growth of your data? Nothing to worry about. Start with GBs and end up with TBs of ingestions per day. Glassflow is built to support you through your entire ClickHouse growth journey.
Horizontal scaling
High throughput ingestion
Low latency
Run GlassFlow your way
Start in minutes or deploy inside your own infrastructure
BYOC - Managed Service
GlassFlow runs in your cloud account
Data plane and. control plane separated. We manage upgrades, orchestration, reliability, and operations while your data stays in your infrastrucure.
Fast setup
Low operational overhead
Production reliability
Full control of data residency
Self-Hosted
GlassFlow runs entirely in your infra
Deploy on Kubernetes or your preffered environment with full control over networking, security, and scaling.
Full infrastracture control
Private environments
Compliance requirements
Custom deployment flexibility
Need prod guarantees?
24/7/365 support
SLAs
Slack/Teams support
Personalized onboarding and training
Implementation engineers


