ljn
ClickHouse Learnings
Remove duplicate events before they reach ClickHouse.
Written by
Armend Avdijaj
-

1. Introduction: The Challenge of Duplicate Events
A critical challenge in modern data pipelines is handling duplicate events. When ingesting data from message brokers like Apache Kafka, the same event often arrives multiple times due to at-least-once delivery guarantees, producer retries, network issues, or upstream system replays. For example, a webhook notification for an SMS delivery might be sent three times due to retry logic, or a payment confirmation event might be duplicated during a network hiccup.
When you ingest these duplicate events into an append-only analytical database like ClickHouse, you end up with multiple identical records for the same unique event. This duplication inflates storage costs, skews analytics (counting the same event multiple times), and forces complex query logic to filter out duplicates at read time.
This article explains a modern architectural pattern that solves this problem by offloading deduplication from the database to a real-time streaming layer. We will demonstrate how to use GlassFlow, an open-source streaming ETL, to identify and remove duplicate events before they reach ClickHouse, delivering clean, unique records ready for fast and accurate queries.
2. Why Handling Duplicates in ClickHouse is Inefficient
ClickHouse and its MergeTree engine family are fundamentally designed for ingesting and analyzing massive, immutable event streams. The append-only nature is a feature that enables incredible write throughput and analytical query speed. It is not, however, designed for deduplication of incoming records.
When faced with duplicate events, engineers typically turn to two native ClickHouse features, both of which come with significant performance trade-offs.
Method 1:
ReplacingMergeTreewith theFINALModifierThe
ReplacingMergeTreetable engine can collapse duplicate rows sharing the same primary key. When a query is executed with theFINALmodifier, ClickHouse performs deduplication at query time, keeping only one row per primary key.This operation is computationally expensive and slow.
FINALdisables many of ClickHouse's read optimizations. It must scan all relevant data parts for a given key and process them on the fly, which leads to significantly higher query latency, especially as data volume and the number of duplicate records grow. It is not a viable solution for user-facing dashboards that demand sub-second response times.
Method 2: Relying on Background Merges
ReplacingMergeTreealso works by asynchronously merging data parts in the background. Over time, these merges will eventually collapse duplicate rows, cleaning up the data on disk.This process is non-deterministic and eventual. Queries run before a merge completes will return duplicate records, as the deduplication is not instantaneous. You cannot predict when the data will be consistent.
Ingesting a high volume of duplicate events creates a massive, continuous background load on the ClickHouse cluster. The constant merging process consumes significant CPU, memory, and I/O, a phenomenon known as write amplification. These resources are stolen from the primary job of the cluster: running analytical queries.
Approach | How It Works | Primary Benefit | Major Drawback |
|---|---|---|---|
| Collapses duplicate rows on-the-fly during query execution. | Guarantees data correctness at query time. | Extremely slow query performance; does not scale for real-time dashboards. |
Background Merges | Asynchronously merges data parts in the background to eventually remove duplicates. | No direct impact on query execution speed. | Eventual consistency (duplicates visible until merge completes); high background resource load (write amplification). |
Table 01: ClickHouse Native Solutions & Their Trade-offs
3. Pre-Ingestion Deduplication with GlassFlow
Instead of burdening the analytical database with complex and resource-intensive deduplication, solve the problem before the data is ingested. Let each component of the stack do what it does best: let the stream processor handle deduplication, and let the analytical database handle analytics on clean data.
GlassFlow is an open-source, real-time streaming ETL tool designed to sit between message brokers like Kafka and databases like ClickHouse. It is purpose-built to handle stateful stream transformations like deduplication and temporal joins.
Below is a summary of how GlassFlow's deduplication works:
Consume: GlassFlow connects to the source Kafka topic and ingests the raw event stream containing duplicates.
Track Unique IDs: As each event arrives, GlassFlow checks the unique identifier (e.g.,
sms_id) against a key-value store (BadgerDB). If the ID has not been seen before, the event is forwarded downstream and the ID is stored.Discard Duplicates: If an event arrives with an ID that already exists in the store, it is identified as a duplicate and discarded. Only the first event for each unique ID passes through.
Time Window Expiration: The stored IDs are automatically evicted after a configurable time window (e.g., 5 minutes). This prevents unbounded memory growth and allows the same ID to be processed again if it reappears after the window expires.
Deliver: Clean, deduplicated events are written to ClickHouse in optimized batches.

Diagram 01: High-Level Architecture Comparison
4. A Step-by-Step Implementation Guide
This section provides a practical, step-by-step walkthrough of implementing the pre-ingestion deduplication architecture. We will follow a real-world scenario from the raw data stream to the final, fast query in ClickHouse.
4.1. The Raw Event Stream
Let's use a real-world example: tracking the delivery status of SMS messages sent through a third-party provider. The provider's API sends webhook events to a Kafka topic when a message is delivered. Due to at-least-once delivery guarantees in Kafka and potential retries from the upstream system, the same event is often delivered multiple times. Our goal is to deduplicate these events so that each unique SMS delivery is recorded only once in ClickHouse.
As shown below, the event for sms_id: "a1b2-c3d4" arrives three times with identical content (a common pattern with webhook retries). The event for sms_id: "e5f6-g7h8" arrives twice. This is the raw, duplicate-heavy data that will be ingested by our pipeline.
Code Block 01: Sample Raw JSON Events from Kafka (with duplicates from retries)
4.2. The GlassFlow Pipeline Configuration
A declarative JSON configuration file defines the entire GlassFlow pipeline. This makes the logic versionable, portable, and easy to manage. The key is the deduplication block, which tells GlassFlow precisely how to identify and eliminate duplicate events.
Let's break down the critical parts of this configuration:
source: Defines the connection to our Kafka topicsms_status_events.deduplication: This is the core of our solution.id_field: "sms_id": Specifies the field used as the unique identifier. Events with the samesms_idare considered duplicates.id_field_type: "string": Specifies the data type of the deduplication key.time_window: "5m": Defines how long each unique ID is remembered in the deduplication store. The first event for eachsms_idpasses through immediately and is written to ClickHouse; any subsequent events with the same ID arriving within the 5-minute window are discarded as duplicates. After the window expires, the ID is evicted from the store.
sink: Defines the destination for the clean data, our ClickHouse table. Themax_batch_sizeandmax_delay_timeparameters are used to optimize writes, ensuring data is sent to ClickHouse in efficient batches.
Code Block 02: GlassFlow Pipeline Configuration for Deduplication
4.3. The Optimized ClickHouse Schema
With GlassFlow handling the real-time deduplication, the ClickHouse table design is much simpler and more efficient.
ENGINE = ReplacingMergeTree(ingested_at): We useReplacingMergeTreeas a best practice. It will act as a final, low-load safeguard to handle any very late-arriving events that might fall outside GlassFlow's processing window. Because GlassFlow has already removed 99% of duplicates, the background merge load on this table will be minimal. Theingested_atcolumn serves as the version field for this engine.status LowCardinality(String): Since thestatusfield has a small number of possible unique values (QUEUED, SENT, DELIVERED, FAILED, etc.), using theLowCardinalitytype significantly improves storage efficiency and query speed.PARTITION BYandORDER BY: Standard best practices are used for partitioning by month and ordering by the primary entity ID to optimize query performance.
Code Block 03: Optimized ClickHouse Table DDL
4.4. The Resulting Data in ClickHouse
After the raw events from section 4.1 pass through the GlassFlow pipeline, only the first event for each sms_id is written to ClickHouse; all subsequent duplicates are discarded. For the sample data (which contained 3 copies of a1b2-c3d4 and 2 copies of e5f6-g7h8), the sms_statuses_latest table would contain only these two clean records:
sms_id | status | updated_at | recipient |
|---|---|---|---|
a1b2-c3d4 | DELIVERED | 2024-10-28 10:00:05 | +15551234567 |
e5f6-g7h8 | DELIVERED | 2024-10-28 10:00:06 | +15557654321 |
4.5. Querying the Data: Simple and Fast
The "old way" required complex, slow aggregations on a table full of duplicate records. The new architecture allows for a simple, direct SELECT on a clean, deduplicated table:
Code Block 04: Query Comparison
By handling the deduplication in the streaming layer, we are transforming an expensive, recurring problem into a simple, efficient read operation, which is exactly what ClickHouse is optimized for.
5. Performance, Cost, and Operational Benefits
Adopting an architecture that offloads deduplication from ClickHouse to a streaming layer like GlassFlow yields transformative benefits that go far beyond just cleaning up data. This approach fundamentally improves the performance, cost-efficiency, and operational simplicity of the entire real-time analytics stack.
The most immediate and impactful benefit is a massive reduction in query latency. In the traditional model, querying deduplicated data requires using the FINAL modifier or SELECT DISTINCT. Both methods are computationally expensive, forcing ClickHouse to perform slow, on-the-fly deduplication at read time. This results in unpredictable query performance that degrades significantly as data volume and the number of duplicates increase, making it unsuitable for real-time dashboards and user-facing applications. By delivering pre-deduplicated data, the GlassFlow architecture transforms this complex operation into a simple SELECT query. These queries are orders of magnitude faster and have predictable, low-latency performance, as ClickHouse can leverage its full suite of read optimizations on the clean dataset.
This performance gain is directly tied to a significant reduction in the operational load on the ClickHouse cluster. Ingesting a high volume of duplicate events creates a constant state of background work as the ReplacingMergeTree engine continuously merges data parts to collapse rows. This process, known as write amplification, consumes a substantial amount of CPU, memory, and I/O. Pre-ingestion deduplication drastically reduces this merge pressure. By feeding ClickHouse clean, unique records, the background merge activity becomes minimal, freeing up the cluster's resources to do what it does best: serve analytical queries with maximum speed. This translates directly to lower operational costs, as clusters no longer need to be over-provisioned to handle the dual load of ingestion merges and analytical reads.
The diagram below illustrates the internal mechanics of the two approaches:
a) The traditional method forces the ClickHouse node to constantly merge numerous small data parts and perform expensive read-time computations.
b) The optimized architecture allows the ClickHouse node to maintain clean, consolidated data parts, leading to minimal background work and fast, direct reads.
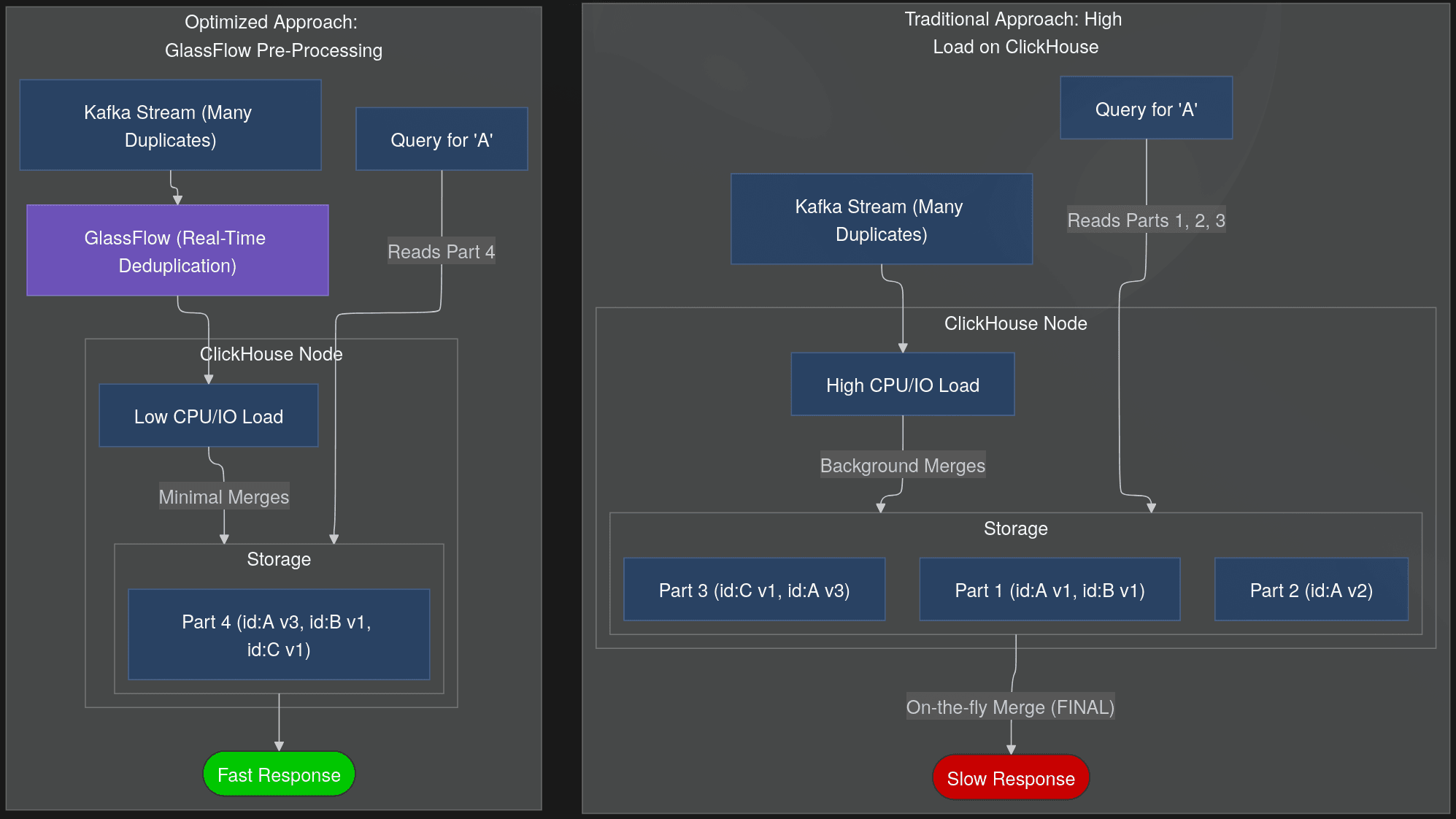
Figure 01: Internal Workload Comparison
Furthermore, this architectural change simplifies the entire data logic ecosystem. When deduplication is handled within ClickHouse, the complex SQL logic required to solve it (FINAL, DISTINCT, window functions) must be replicated everywhere the data is consumed (in BI tools, application code, and ad-hoc analyst queries). This creates a maintenance nightmare where a change in logic requires updating dozens of downstream dependencies. By centralizing the deduplication logic in the GlassFlow pipeline configuration, you create a single source of truth. The logic is defined once, in a simple, declarative way, and all downstream consumers work with a clean, ready-to-use dataset.
Finally, separating the concerns of stream processing and analytics leads to a more scalable and resilient system. The deduplication workload, which is I/O and CPU intensive in a specific way, is handled by GlassFlow, a purpose-built stream processor designed for that task. The analytical query workload is handled by ClickHouse. This decoupling allows each component to be scaled independently based on its specific needs. If ingestion volume spikes, you can scale the GlassFlow workers. If query concurrency increases, you can scale the ClickHouse cluster. This is far more efficient and cost-effective than scaling a single, monolithic system trying to do both jobs at once.
The table below summarizes the clear advantages of this modern approach over the traditional, database-centric method:
Metric | ClickHouse-Only Approach | GlassFlow + ClickHouse Approach |
|---|---|---|
Query Performance | Slow and unpredictable due to | Fast, simple |
ClickHouse Resource Use | High CPU/IO from constant background merges. | Low background load; resources are available for queries. |
Data Consistency | Eventual consistency; queries can return stale data. | Near real-time consistency; data in ClickHouse is already clean. |
Logic Complexity | Complex SQL ( | Simple, declarative logic centralized in the streaming layer. |
Operational Cost | Requires over-provisioning ClickHouse to handle merges. | More efficient resource usage; right-sized clusters. |
Table 02: Cost-Benefit Analysis Summary
6. Key Considerations and Best Practices
Implementing this architecture successfully requires understanding a few key trade-offs and best practices.
A critical parameter in this configuration is the time_window set within the GlassFlow pipeline. This setting dictates how long GlassFlow remembers each unique ID in its deduplication store. When an event arrives, GlassFlow immediately checks if the ID exists in the store: if not, the event passes through to ClickHouse and the ID is stored; if it does exist, the event is discarded as a duplicate. The time window controls when stored IDs are evicted, not how long events are buffered.
This creates a trade-off between deduplication effectiveness and memory usage. A shorter window, for instance one minute (1m), uses less memory but risks missing duplicates if some events are delayed in the source systems for longer than that minute. Conversely, a longer window, such as one hour (1h), provides a much more robust buffer against delayed duplicate events, but requires more memory to store the larger set of unique IDs. The ideal window size must be chosen based on how long duplicates typically arrive after the original event in your data stream.
This leads to a crucial question: what happens to data that arrives after the processing window has closed? This is where the synergy between GlassFlow and ClickHouse's ReplacingMergeTree creates a resilient, two-stage solution for handling late data. GlassFlow acts as the first and primary line of defense, catching and eliminating the vast majority of duplicates in real-time before they ever touch the database. This keeps the ClickHouse cluster clean and efficient for 99.9% of the workload. ReplacingMergeTree then serves as an effective, low-load final backstop. In the rare event that a duplicate record arrives exceptionally late (long after the GlassFlow window has passed) the ReplacingMergeTree engine will gracefully handle it during its next background merge cycle. Because this happens so infrequently, it places almost no additional load on the cluster, giving you the best of both worlds: immediate consistency for most data, and eventual consistency for the rare exceptions.
Additional to handling late data, this architecture also provides a powerful operational guarantee: idempotency. An idempotent pipeline is one that can re-process the same input data multiple times without changing the final state of the target system. This is a critical feature for data integrity in real-world production environments. For example, if you need to recover from a downstream failure or re-run a process after a new deployment, you might need to replay a batch of source data from Kafka. In a traditional append-only pipeline, this would create a storm of unwanted duplicate records in ClickHouse. With this pattern, however, GlassFlow's stateful deduplication will correctly process the replayed events, apply the same "keep first" logic, and ensure that only a single record for each entity is preserved. This makes the entire data pipeline far more resilient and simplifies operational procedures significantly.
7. Final Thoughts
At the end of the day, the challenge of handling duplicate events in ClickHouse is a sign that we're asking it to solve a problem it wasn't designed for. ClickHouse is a great engine for analyzing massive, immutable streams of events. It's designed to perform when you're asking questions about what happened over time. The friction arises when we ingest messy, duplicate-heavy data and then try to clean it up at query time. Trying to solve this with database-side tricks like FINAL or by relying on ReplacingMergeTree background merges is inefficient, slow, and puts a huge strain on your cluster.
The solution we've explored here reframes this as what it really is: a stream processing problem, not a database problem. By placing a specialized, stateful stream processor like GlassFlow in front of ClickHouse, we create a clean division of labor. GlassFlow does the heavy lifting of identifying and eliminating duplicate events in real-time, before they reach the database. This allows ClickHouse to do what it was born to do: run incredibly fast analytical queries on clean, well-structured data. Each component plays to its strengths.
The ultimate gain from this approach is a healthier, more scalable, and more cost-effective data stack. Your ClickHouse cluster is no longer burning CPU and I/O cycles on a constant treadmill of background merges. Your query performance becomes predictably fast, which is the foundation of any reliable real-time application. And your deduplication logic is no longer scattered across complex SQL queries but is centralized, versionable, and easy to reason about.
So, if your team is hitting the performance walls of FINAL or watching your cluster resources get consumed by write amplification from duplicate events, the answer probably isn't a bigger cluster or a more complex query. Instead, focus on solving the problem where it originates: in the stream itself.
8. References
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
