Connecting Apache Flink and ClickHouse creates significant headaches for data engineers despite both being powerful tools in their respective domains. The core problem? There's no native connector between Flink's stream processing framework and ClickHouse's analytical database, unlike the official connectors available for MySQL, PostgreSQL, or Elasticsearch.
This architectural mismatch forces engineering teams to develop custom integration solutions that inevitably compromise on performance, reliability, or exactly-once processing guarantees. The fundamental issue stems from how differently these systems handle transactions, distribute workloads, and process data - Flink with its checkpoint-based consistency model and ClickHouse with its append-only operations and eventual consistency.
Imagine building real-time data pipelines where your streaming platform and analytics database just won't work together efficiently. That's the reality when connecting Flink and ClickHouse. Unlike other databases with native Flink connectors, ClickHouse lacks this integration, forcing you to create custom solutions that compromise either performance, reliability, or processing guarantees.
We'll examine why connecting these systems is so challenging by exploring four common approaches data engineers have developed: JDBC connectors, HTTP interfaces, two-phase commit patterns, and Kafka intermediaries. Each method attempts to bridge the architectural gap, but introduces its own engineering complexities and trade-offs that impact production deployments.
Architectural Impedance Mismatch
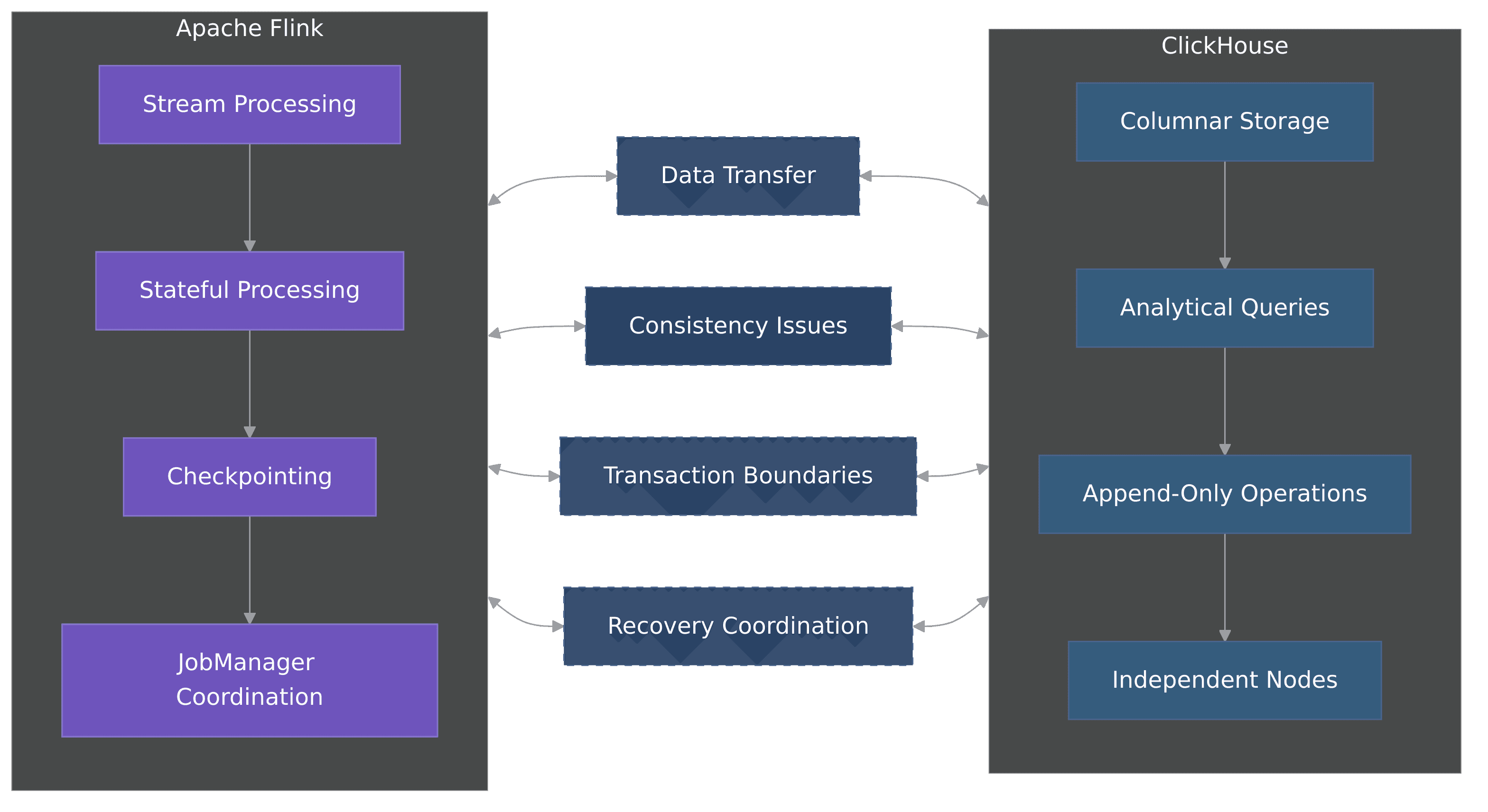
When integrating Flink with ClickHouse, data engineers face fundamental architectural differences that create significant integration challenges. These systems were designed with different priorities, leading to what's known as an "impedance mismatch", a term borrowed from electrical engineering that perfectly describes the friction between these technologies.
Feature
Apache Flink
ClickHouse
Integration Challenge
Processing Paradigm
Continuous dataflow with stateful operators
Columnar storage optimized for analytical queries
Flink processes unbounded streams while ClickHouse expects discrete queries
Transaction Model
Two-phase commit with checkpointing
Append-only operations with eventual consistency
Flink's exactly-once guarantees clash with ClickHouse's limited transaction support
Distribution Design
Centralized coordination via JobManager-TaskManager
Independent nodes with physical replication
Different coordination models complicate synchronization
State Management
Rich stateful operations with fault tolerance
Limited state tracking between operations
Complex stateful operations in Flink are difficult to translate to ClickHouse
Execution Model
Persistent dataflow graph with continuous execution
Discrete query execution with independent execution plans
Conceptual mismatch in how work is scheduled and executed
Data Partitioning
Dynamic partitioning based on keys or ranges
Static partitioning based on predefined schemas
Partitioning strategies may not align between systems
Vertical and horizontal scaling with dynamic resource allocation
Horizontal scaling through sharding
Different scaling strategies create operational complexity
These architectural disparities explain why creating a native connector between Flink and ClickHouse has been challenging and why no official connector exists in the Flink ecosystem. The mismatch between Flink's stream processing model with strong consistency guarantees and ClickHouse's focus on analytical performance creates a fundamental tension in engineering teams.
The following diagram visualizes these architectural differences, highlighting the key components of each system and the integration challenges that arise when connecting them:
Integration Approaches and Their Limitations
When integrating Flink with ClickHouse, engineers have developed several approaches to bridge the architectural gaps. Each method comes with significant limitations that impact performance, reliability, and operational complexity. Let's examine these approaches and their shortcomings through practical examples.
You can find the complete worked examples in this link, so you can follow along with the article.
JDBC Connector Approach
The JDBC connector approach leverages Flink's built-in JDBC sink connector along with ClickHouse's JDBC driver.
Let's consider a real-time user analytics pipeline where we need to process thousands of events per second from a web application and store them in ClickHouse for analysis. We'll implement this using Flink's JDBC connector and examine where this solution falls short under production conditions.
When implementing a user events pipeline with the JDBC connector, you'll typically start with configuration similar to this:
# Set up the Flink execution environmentenv = StreamExecutionEnvironment.get_execution_environment()env.set_parallelism(4)# Multiple parallel tasks will compete for connectionssettings = EnvironmentSettings.new_instance().in_streaming_mode().build()t_env = StreamTableEnvironment.create(env,settings)# Set necessary JARs - this highlights the first limitation:# Engineers must manually manage dependenciest_env.get_config().get_configuration().set_string("pipeline.jars","file:///path/to/clickhouse-jdbc-0.4.6-all.jar;file:///path/to/flink-connector-jdbc_2.12-1.16.0.jar")# Define a source table from CSV filet_env.execute_sql("""
CREATE TEMPORARY TABLE source_events (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'filesystem',
'path' = 'file:///temp/sample_events.csv',
'format' = 'csv',
'csv.field-delimiter' = ',',
'csv.ignore-parse-errors' = 'true'
)
""")# Define ClickHouse sink using JDBC connector# Note the limited connection pool settings - a major bottleneckt_env.execute_sql("""
CREATE TABLE clickhouse_sink (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:clickhouse://localhost:8123/default',
'table-name' = 'user_events',
'driver' = 'com.clickhouse.jdbc.ClickHouseDriver',
'connection.max-retry-timeout' = '20s',
'sink.buffer-flush.max-rows' = '1000',
'sink.buffer-flush.interval' = '1s',
'sink.max-retries' = '3'
)
""")# Insert operationt_env.execute_sql("""
INSERT INTO clickhouse_sink
SELECT event_id, user_id, event_type, event_time, properties
FROM source_events
""")
# Set up the Flink execution environmentenv = StreamExecutionEnvironment.get_execution_environment()env.set_parallelism(4)# Multiple parallel tasks will compete for connectionssettings = EnvironmentSettings.new_instance().in_streaming_mode().build()t_env = StreamTableEnvironment.create(env,settings)# Set necessary JARs - this highlights the first limitation:# Engineers must manually manage dependenciest_env.get_config().get_configuration().set_string("pipeline.jars","file:///path/to/clickhouse-jdbc-0.4.6-all.jar;file:///path/to/flink-connector-jdbc_2.12-1.16.0.jar")# Define a source table from CSV filet_env.execute_sql("""
CREATE TEMPORARY TABLE source_events (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'filesystem',
'path' = 'file:///temp/sample_events.csv',
'format' = 'csv',
'csv.field-delimiter' = ',',
'csv.ignore-parse-errors' = 'true'
)
""")# Define ClickHouse sink using JDBC connector# Note the limited connection pool settings - a major bottleneckt_env.execute_sql("""
CREATE TABLE clickhouse_sink (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:clickhouse://localhost:8123/default',
'table-name' = 'user_events',
'driver' = 'com.clickhouse.jdbc.ClickHouseDriver',
'connection.max-retry-timeout' = '20s',
'sink.buffer-flush.max-rows' = '1000',
'sink.buffer-flush.interval' = '1s',
'sink.max-retries' = '3'
)
""")# Insert operationt_env.execute_sql("""
INSERT INTO clickhouse_sink
SELECT event_id, user_id, event_type, event_time, properties
FROM source_events
""")
# Set up the Flink execution environmentenv = StreamExecutionEnvironment.get_execution_environment()env.set_parallelism(4)# Multiple parallel tasks will compete for connectionssettings = EnvironmentSettings.new_instance().in_streaming_mode().build()t_env = StreamTableEnvironment.create(env,settings)# Set necessary JARs - this highlights the first limitation:# Engineers must manually manage dependenciest_env.get_config().get_configuration().set_string("pipeline.jars","file:///path/to/clickhouse-jdbc-0.4.6-all.jar;file:///path/to/flink-connector-jdbc_2.12-1.16.0.jar")# Define a source table from CSV filet_env.execute_sql("""
CREATE TEMPORARY TABLE source_events (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'filesystem',
'path' = 'file:///temp/sample_events.csv',
'format' = 'csv',
'csv.field-delimiter' = ',',
'csv.ignore-parse-errors' = 'true'
)
""")# Define ClickHouse sink using JDBC connector# Note the limited connection pool settings - a major bottleneckt_env.execute_sql("""
CREATE TABLE clickhouse_sink (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:clickhouse://localhost:8123/default',
'table-name' = 'user_events',
'driver' = 'com.clickhouse.jdbc.ClickHouseDriver',
'connection.max-retry-timeout' = '20s',
'sink.buffer-flush.max-rows' = '1000',
'sink.buffer-flush.interval' = '1s',
'sink.max-retries' = '3'
)
""")# Insert operationt_env.execute_sql("""
INSERT INTO clickhouse_sink
SELECT event_id, user_id, event_type, event_time, properties
FROM source_events
""")
While this looks effective, testing reveals significant throughput issues when scaling up. Our benchmarks showed how connection pool limitations cripple performance under load:
To understand why this happens, let's examine what occurs when multiple Flink tasks compete for database connections:
defdemonstrate_connection_bottleneck(clickhouse_client):
"""Show how connection pool limitations affect performance under load"""start_time = time.time()# Check initial record countinitial_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]print(f"Initial record count: {initial_count}")# Try to insert many records in parallel - simulating what happens in Flinkbatch_size = 1000num_batches = 20forbatchinrange(num_batches):
# Generate batch datadata = []foriinrange(batch_size):
record_id = batch * batch_size + idata.append([f"parallel_{record_id}",f"user_{random.randint(1,100)}",random.choice(['page_view','click','purchase']),pd.Timestamp.now(),'{}'])# Insert batch using clickhouse-connect# In real Flink JDBC scenario, these would compete for connectionsprint(f"Inserting batch {batch+1}/{num_batches}...")clickhouse_client.insert('user_events',data,column_names=['event_id','user_id','event_type','event_time','properties'])# Get final count and timingfinal_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]elapsed_time = time.time() - start_timeprint(f"Inserted {final_count - initial_count} records in {elapsed_time:.2f} seconds")print(f"Rate: {(final_count - initial_count) / elapsed_time:.2f} records/second")# This demonstration shows ideal throughput without connection limitations# In a real JDBC Flink setup, performance would be much worse
defdemonstrate_connection_bottleneck(clickhouse_client):
"""Show how connection pool limitations affect performance under load"""start_time = time.time()# Check initial record countinitial_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]print(f"Initial record count: {initial_count}")# Try to insert many records in parallel - simulating what happens in Flinkbatch_size = 1000num_batches = 20forbatchinrange(num_batches):
# Generate batch datadata = []foriinrange(batch_size):
record_id = batch * batch_size + idata.append([f"parallel_{record_id}",f"user_{random.randint(1,100)}",random.choice(['page_view','click','purchase']),pd.Timestamp.now(),'{}'])# Insert batch using clickhouse-connect# In real Flink JDBC scenario, these would compete for connectionsprint(f"Inserting batch {batch+1}/{num_batches}...")clickhouse_client.insert('user_events',data,column_names=['event_id','user_id','event_type','event_time','properties'])# Get final count and timingfinal_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]elapsed_time = time.time() - start_timeprint(f"Inserted {final_count - initial_count} records in {elapsed_time:.2f} seconds")print(f"Rate: {(final_count - initial_count) / elapsed_time:.2f} records/second")# This demonstration shows ideal throughput without connection limitations# In a real JDBC Flink setup, performance would be much worse
defdemonstrate_connection_bottleneck(clickhouse_client):
"""Show how connection pool limitations affect performance under load"""start_time = time.time()# Check initial record countinitial_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]print(f"Initial record count: {initial_count}")# Try to insert many records in parallel - simulating what happens in Flinkbatch_size = 1000num_batches = 20forbatchinrange(num_batches):
# Generate batch datadata = []foriinrange(batch_size):
record_id = batch * batch_size + idata.append([f"parallel_{record_id}",f"user_{random.randint(1,100)}",random.choice(['page_view','click','purchase']),pd.Timestamp.now(),'{}'])# Insert batch using clickhouse-connect# In real Flink JDBC scenario, these would compete for connectionsprint(f"Inserting batch {batch+1}/{num_batches}...")clickhouse_client.insert('user_events',data,column_names=['event_id','user_id','event_type','event_time','properties'])# Get final count and timingfinal_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]elapsed_time = time.time() - start_timeprint(f"Inserted {final_count - initial_count} records in {elapsed_time:.2f} seconds")print(f"Rate: {(final_count - initial_count) / elapsed_time:.2f} records/second")# This demonstration shows ideal throughput without connection limitations# In a real JDBC Flink setup, performance would be much worse
This example simulates what happens in a production environment when multiple Flink tasks compete for a limited number of database connections. As the number of parallel tasks increases, connection pool exhaustion creates a bottleneck that significantly reduces throughput.
Even more concerning is the lack of proper integration with Flink's checkpointing mechanism, which leads to data consistency problems:
The problem becomes evident when we simulate a failure during transaction processing:
defdemonstrate_transaction_issues(clickhouse_client):
"""Show how Flink-ClickHouse JDBC lacks transaction coordination with checkpoints"""# First, count recordsinitial_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]# Create unique record IDs for this demonstrationunique_prefix = int(time.time())# Insert a batch of recordsbatch_size = 5000insert_data = []foriinrange(batch_size):
insert_data.append([f"tx_{unique_prefix}_{i}",# Unique IDf"user_{i % 100}",'transaction_test',pd.Timestamp.now(),'{}'])# Insert first half of the data (simulating successful first part of transaction)print(f"Inserting first half of transaction ({batch_size//2} records)...")clickhouse_client.insert('user_events',insert_data[:batch_size//2],column_names=['event_id','user_id','event_type','event_time','properties'])# Simulate a failure and recoveryprint("Simulating failure during transaction...")time.sleep(1)# Flink would normally restart and "replay" from last checkpoint# But the JDBC connector doesn't track what was committed# Leading to potential duplicates or missing recordsprint("Restarting and replaying transaction (potentially creating duplicates)...")clickhouse_client.insert('user_events',insert_data,column_names=['event_id','user_id','event_type','event_time','properties'])# Check for potential duplicatesfinal_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]records_added = final_count - initial_countprint(f"Inserted {records_added} records in total")print(f"Expected: {batch_size}, Actual: {records_added}")ifrecords_added > batch_size:
print(f"Duplicate detection: Found approximately {records_added - batch_size} duplicates")# Count actual duplicates by event_idduplicate_query = f"""
SELECT count()
FROM (
SELECT event_id, count() as cnt
FROM user_events
WHERE event_id LIKE 'tx_{unique_prefix}_%'
GROUP BY event_id
HAVING cnt > 1
)
"""duplicate_count = clickhouse_client.query(duplicate_query).result_rows[0][0]print(f"Actual duplicates by event_id: {duplicate_count}")
defdemonstrate_transaction_issues(clickhouse_client):
"""Show how Flink-ClickHouse JDBC lacks transaction coordination with checkpoints"""# First, count recordsinitial_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]# Create unique record IDs for this demonstrationunique_prefix = int(time.time())# Insert a batch of recordsbatch_size = 5000insert_data = []foriinrange(batch_size):
insert_data.append([f"tx_{unique_prefix}_{i}",# Unique IDf"user_{i % 100}",'transaction_test',pd.Timestamp.now(),'{}'])# Insert first half of the data (simulating successful first part of transaction)print(f"Inserting first half of transaction ({batch_size//2} records)...")clickhouse_client.insert('user_events',insert_data[:batch_size//2],column_names=['event_id','user_id','event_type','event_time','properties'])# Simulate a failure and recoveryprint("Simulating failure during transaction...")time.sleep(1)# Flink would normally restart and "replay" from last checkpoint# But the JDBC connector doesn't track what was committed# Leading to potential duplicates or missing recordsprint("Restarting and replaying transaction (potentially creating duplicates)...")clickhouse_client.insert('user_events',insert_data,column_names=['event_id','user_id','event_type','event_time','properties'])# Check for potential duplicatesfinal_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]records_added = final_count - initial_countprint(f"Inserted {records_added} records in total")print(f"Expected: {batch_size}, Actual: {records_added}")ifrecords_added > batch_size:
print(f"Duplicate detection: Found approximately {records_added - batch_size} duplicates")# Count actual duplicates by event_idduplicate_query = f"""
SELECT count()
FROM (
SELECT event_id, count() as cnt
FROM user_events
WHERE event_id LIKE 'tx_{unique_prefix}_%'
GROUP BY event_id
HAVING cnt > 1
)
"""duplicate_count = clickhouse_client.query(duplicate_query).result_rows[0][0]print(f"Actual duplicates by event_id: {duplicate_count}")
defdemonstrate_transaction_issues(clickhouse_client):
"""Show how Flink-ClickHouse JDBC lacks transaction coordination with checkpoints"""# First, count recordsinitial_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]# Create unique record IDs for this demonstrationunique_prefix = int(time.time())# Insert a batch of recordsbatch_size = 5000insert_data = []foriinrange(batch_size):
insert_data.append([f"tx_{unique_prefix}_{i}",# Unique IDf"user_{i % 100}",'transaction_test',pd.Timestamp.now(),'{}'])# Insert first half of the data (simulating successful first part of transaction)print(f"Inserting first half of transaction ({batch_size//2} records)...")clickhouse_client.insert('user_events',insert_data[:batch_size//2],column_names=['event_id','user_id','event_type','event_time','properties'])# Simulate a failure and recoveryprint("Simulating failure during transaction...")time.sleep(1)# Flink would normally restart and "replay" from last checkpoint# But the JDBC connector doesn't track what was committed# Leading to potential duplicates or missing recordsprint("Restarting and replaying transaction (potentially creating duplicates)...")clickhouse_client.insert('user_events',insert_data,column_names=['event_id','user_id','event_type','event_time','properties'])# Check for potential duplicatesfinal_count = clickhouse_client.query('SELECT count() FROM user_events').result_rows[0][0]records_added = final_count - initial_countprint(f"Inserted {records_added} records in total")print(f"Expected: {batch_size}, Actual: {records_added}")ifrecords_added > batch_size:
print(f"Duplicate detection: Found approximately {records_added - batch_size} duplicates")# Count actual duplicates by event_idduplicate_query = f"""
SELECT count()
FROM (
SELECT event_id, count() as cnt
FROM user_events
WHERE event_id LIKE 'tx_{unique_prefix}_%'
GROUP BY event_id
HAVING cnt > 1
)
"""duplicate_count = clickhouse_client.query(duplicate_query).result_rows[0][0]print(f"Actual duplicates by event_id: {duplicate_count}")
The root cause lies in how JDBC connections work compared to Flink's checkpoint-based consistency model:
This fundamental mismatch creates five critical limitations when using the JDBC connector for Flink-ClickHouse integration:
Connection Pool Bottlenecks: Limited connections significantly throttle throughput as concurrent tasks compete for database connections.
No Integration with Checkpointing: JDBC transactions aren't aligned with Flink's checkpoint barriers, making exactly-once processing impossible.
Performance Degradation at Scale: JDBC overhead increases drastically with data volume, creating latency spikes.
Manual Schema Synchronization: Table definitions must be manually kept in sync between Flink and ClickHouse.
So, while the JDBC connector offers simplicity through familiar database APIs, its performance bottlenecks and lack of checkpoint integration make it unsuitable for high-throughput production scenarios.
HTTP Interface Implementation
The HTTP interface bypasses JDBC overhead by communicating directly with ClickHouse's native HTTP API. This approach gives engineers more control but introduces complexity:
The following class creates a direct HTTP connection to ClickHouse, enabling you to send SQL queries and insert data batches using ClickHouse's native HTTP API instead of going through JDBC drivers:
class ClickHouseHTTPClient:
"""Custom HTTP client for ClickHouse interactions"""def__init__(self,host='localhost',port=8123,database='default'):
self.base_url = f"http://{host}:{port}"self.database = databasedefexecute_query(self,query: str) -> requests.Response:
"""Execute a SQL query via HTTP"""params = {'database': self.database,'query': query}try:
response = requests.post(self.base_url,params=params)response.raise_for_status()returnresponseexceptrequests.exceptions.RequestExceptionase:
print(f"Error executing query: {e}")raisedefinsert_batch_json(self,table: str,data: List[Dict[str,Any]]) -> bool:
"""Insert batch of records in JSON format"""json_data = '\n'.join(json.dumps(record)forrecordindata)query = f"INSERT INTO {table} FORMAT JSONEachRow"try:
response = requests.post(f"{self.base_url}/?query={query}",data=json_data,headers={'Content-Type': 'application/json'})response.raise_for_status()returnTrueexceptrequests.exceptions.RequestExceptionase:
print(f"Error inserting data: {e}")returnFalse
class ClickHouseHTTPClient:
"""Custom HTTP client for ClickHouse interactions"""def__init__(self,host='localhost',port=8123,database='default'):
self.base_url = f"http://{host}:{port}"self.database = databasedefexecute_query(self,query: str) -> requests.Response:
"""Execute a SQL query via HTTP"""params = {'database': self.database,'query': query}try:
response = requests.post(self.base_url,params=params)response.raise_for_status()returnresponseexceptrequests.exceptions.RequestExceptionase:
print(f"Error executing query: {e}")raisedefinsert_batch_json(self,table: str,data: List[Dict[str,Any]]) -> bool:
"""Insert batch of records in JSON format"""json_data = '\n'.join(json.dumps(record)forrecordindata)query = f"INSERT INTO {table} FORMAT JSONEachRow"try:
response = requests.post(f"{self.base_url}/?query={query}",data=json_data,headers={'Content-Type': 'application/json'})response.raise_for_status()returnTrueexceptrequests.exceptions.RequestExceptionase:
print(f"Error inserting data: {e}")returnFalse
class ClickHouseHTTPClient:
"""Custom HTTP client for ClickHouse interactions"""def__init__(self,host='localhost',port=8123,database='default'):
self.base_url = f"http://{host}:{port}"self.database = databasedefexecute_query(self,query: str) -> requests.Response:
"""Execute a SQL query via HTTP"""params = {'database': self.database,'query': query}try:
response = requests.post(self.base_url,params=params)response.raise_for_status()returnresponseexceptrequests.exceptions.RequestExceptionase:
print(f"Error executing query: {e}")raisedefinsert_batch_json(self,table: str,data: List[Dict[str,Any]]) -> bool:
"""Insert batch of records in JSON format"""json_data = '\n'.join(json.dumps(record)forrecordindata)query = f"INSERT INTO {table} FORMAT JSONEachRow"try:
response = requests.post(f"{self.base_url}/?query={query}",data=json_data,headers={'Content-Type': 'application/json'})response.raise_for_status()returnTrueexceptrequests.exceptions.RequestExceptionase:
print(f"Error inserting data: {e}")returnFalse
Engineers must then implement a custom Flink sink to use this HTTP client:
class ClickHouseHTTPSink(MapFunction):
"""
Custom Flink sink that sends data to ClickHouse via HTTP.
This demonstrates how engineers must build their own integration.
"""def__init__(self,host='localhost',port=8123,table='user_events',batch_size=1000,flush_interval=1.0):
self.host = hostself.port = portself.table = tableself.batch_size = batch_sizeself.flush_interval = flush_intervalself.client = Noneself.batch = []self.last_flush_time = 0defopen(self,runtime_context: RuntimeContext):
"""Initialize the sink"""self.client = ClickHouseHTTPClient(host=self.host,port=self.port)self.batch = []self.last_flush_time = time.time()defmap(self,value):
"""Process each record"""# Add to batchself.batch.append(value)current_time = time.time()# Flush if batch size reached or interval elapsedif(len(self.batch) >= self.batch_sizeorcurrent_time - self.last_flush_time >= self.flush_interval):
self._flush()self.last_flush_time = current_timereturnvalue# Pass through for downstream operators# _flush method and error handling omitted for brevity
class ClickHouseHTTPSink(MapFunction):
"""
Custom Flink sink that sends data to ClickHouse via HTTP.
This demonstrates how engineers must build their own integration.
"""def__init__(self,host='localhost',port=8123,table='user_events',batch_size=1000,flush_interval=1.0):
self.host = hostself.port = portself.table = tableself.batch_size = batch_sizeself.flush_interval = flush_intervalself.client = Noneself.batch = []self.last_flush_time = 0defopen(self,runtime_context: RuntimeContext):
"""Initialize the sink"""self.client = ClickHouseHTTPClient(host=self.host,port=self.port)self.batch = []self.last_flush_time = time.time()defmap(self,value):
"""Process each record"""# Add to batchself.batch.append(value)current_time = time.time()# Flush if batch size reached or interval elapsedif(len(self.batch) >= self.batch_sizeorcurrent_time - self.last_flush_time >= self.flush_interval):
self._flush()self.last_flush_time = current_timereturnvalue# Pass through for downstream operators# _flush method and error handling omitted for brevity
class ClickHouseHTTPSink(MapFunction):
"""
Custom Flink sink that sends data to ClickHouse via HTTP.
This demonstrates how engineers must build their own integration.
"""def__init__(self,host='localhost',port=8123,table='user_events',batch_size=1000,flush_interval=1.0):
self.host = hostself.port = portself.table = tableself.batch_size = batch_sizeself.flush_interval = flush_intervalself.client = Noneself.batch = []self.last_flush_time = 0defopen(self,runtime_context: RuntimeContext):
"""Initialize the sink"""self.client = ClickHouseHTTPClient(host=self.host,port=self.port)self.batch = []self.last_flush_time = time.time()defmap(self,value):
"""Process each record"""# Add to batchself.batch.append(value)current_time = time.time()# Flush if batch size reached or interval elapsedif(len(self.batch) >= self.batch_sizeorcurrent_time - self.last_flush_time >= self.flush_interval):
self._flush()self.last_flush_time = current_timereturnvalue# Pass through for downstream operators# _flush method and error handling omitted for brevity
This custom sink implementation gives engineers more control over batch sizes, retry logic, and error handling. The main issue is that it shifts the burden of managing these concerns from Flink to the application code, introducing more complexity.
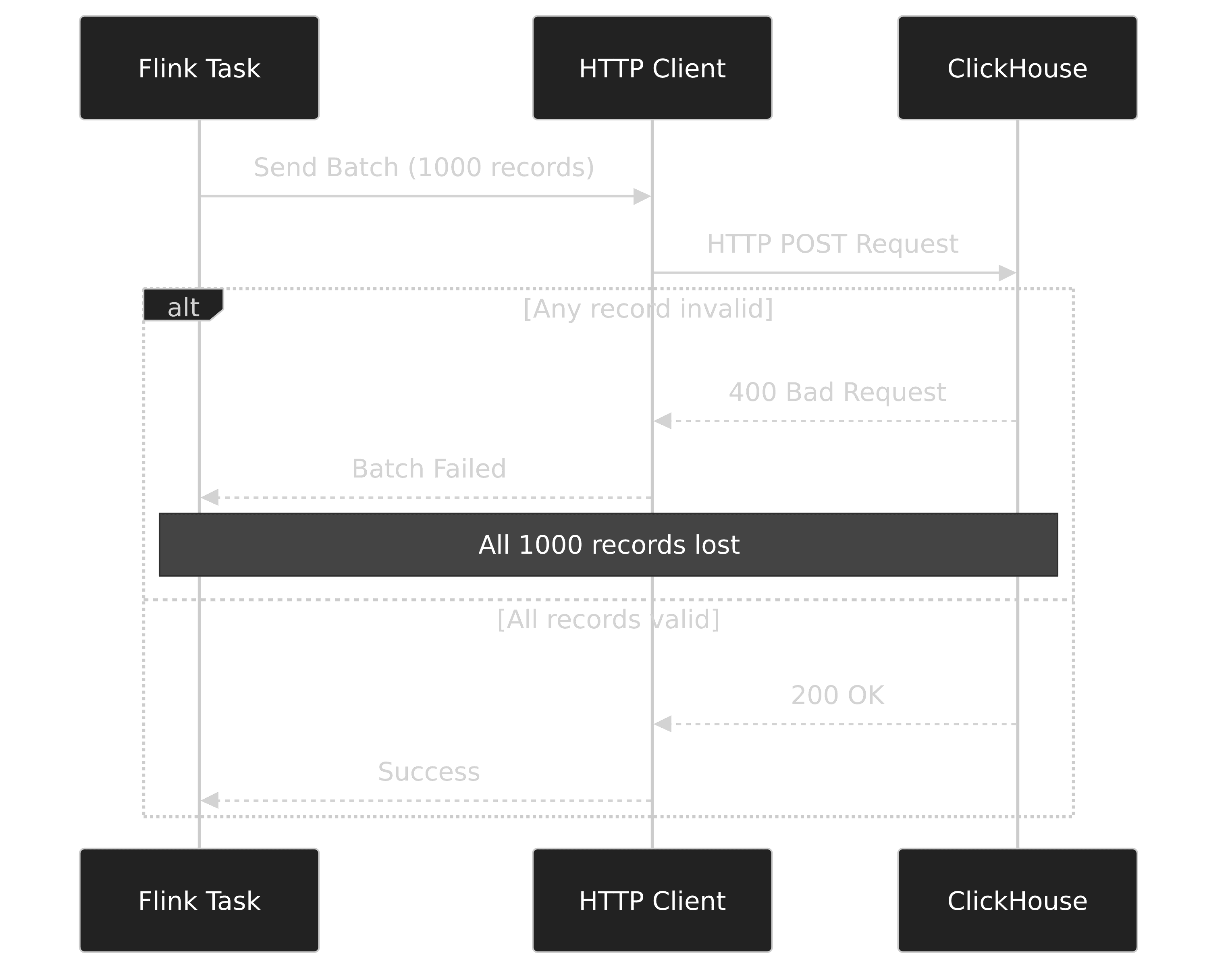
Testing reveals serious error handling issues. When inserting batches with invalid data:
The following sequence diagram illustrates how a single invalid record can cause an entire batch to fail when using the HTTP interface, highlighting the fragility of this approach without advanced error handling:
Concurrent operations also present challenges:
defdemonstrate_concurrency_limitations():
"""Show how HTTP interface struggles with concurrent requests"""client = ClickHouseHTTPClient()# Function to insert a batchdefinsert_batch(batch_id):
try:
batch_size = 1000data = []foriinrange(batch_size):
record = {"event_id": f"concurrent_{batch_id}_{i}","user_id": f"user_{i % 50}","event_type": "concurrency_test","event_time": pd.Timestamp.now().isoformat(),"properties": "{}"}data.append(record)start_time = time.time()success = client.insert_batch_json("user_events",data)elapsed = time.time() - start_timereturn{"batch_id": batch_id,"success": success,"elapsed": elapsed,"records": batch_size}exceptExceptionase:
return{"batch_id": batch_id,"success": False,"error": str(e),"records": 0}# Try to insert multiple batches concurrentlynum_batches = 20print(f"Inserting {num_batches} batches concurrently...")withconcurrent.futures.ThreadPoolExecutor(max_workers=num_batches)asexecutor:
futures = [executor.submit(insert_batch,i)foriinrange(num_batches)]results = [future.result()forfutureinconcurrent.futures.as_completed(futures)]
defdemonstrate_concurrency_limitations():
"""Show how HTTP interface struggles with concurrent requests"""client = ClickHouseHTTPClient()# Function to insert a batchdefinsert_batch(batch_id):
try:
batch_size = 1000data = []foriinrange(batch_size):
record = {"event_id": f"concurrent_{batch_id}_{i}","user_id": f"user_{i % 50}","event_type": "concurrency_test","event_time": pd.Timestamp.now().isoformat(),"properties": "{}"}data.append(record)start_time = time.time()success = client.insert_batch_json("user_events",data)elapsed = time.time() - start_timereturn{"batch_id": batch_id,"success": success,"elapsed": elapsed,"records": batch_size}exceptExceptionase:
return{"batch_id": batch_id,"success": False,"error": str(e),"records": 0}# Try to insert multiple batches concurrentlynum_batches = 20print(f"Inserting {num_batches} batches concurrently...")withconcurrent.futures.ThreadPoolExecutor(max_workers=num_batches)asexecutor:
futures = [executor.submit(insert_batch,i)foriinrange(num_batches)]results = [future.result()forfutureinconcurrent.futures.as_completed(futures)]
defdemonstrate_concurrency_limitations():
"""Show how HTTP interface struggles with concurrent requests"""client = ClickHouseHTTPClient()# Function to insert a batchdefinsert_batch(batch_id):
try:
batch_size = 1000data = []foriinrange(batch_size):
record = {"event_id": f"concurrent_{batch_id}_{i}","user_id": f"user_{i % 50}","event_type": "concurrency_test","event_time": pd.Timestamp.now().isoformat(),"properties": "{}"}data.append(record)start_time = time.time()success = client.insert_batch_json("user_events",data)elapsed = time.time() - start_timereturn{"batch_id": batch_id,"success": success,"elapsed": elapsed,"records": batch_size}exceptExceptionase:
return{"batch_id": batch_id,"success": False,"error": str(e),"records": 0}# Try to insert multiple batches concurrentlynum_batches = 20print(f"Inserting {num_batches} batches concurrently...")withconcurrent.futures.ThreadPoolExecutor(max_workers=num_batches)asexecutor:
futures = [executor.submit(insert_batch,i)foriinrange(num_batches)]results = [future.result()forfutureinconcurrent.futures.as_completed(futures)]
This demonstrates how HTTP interface requires custom concurrency control.
In a Flink context, this would require careful tuning of:
Parallelism
Batch sizes
Connection timeouts
Retry policies
Most critical is the lack of integration with Flink's checkpointing mechanism:
defdemonstrate_checkpoint_issues():
"""Show how HTTP interface lacks integration with Flink's checkpointing"""# In Flink's checkpointing mechanism, operators need to:# 1. Snapshot their state (what's been processed)# 2. Restore from snapshot after failure# 3. Ensure exactly-once semantics through transactions# With HTTP interface, we'd need to implement custom logic# Simulate state tracking that would be neededclass CheckpointState:
def__init__(self):
self.last_checkpoint_time = 0self.processed_batches = set()self.in_flight_batches = {}defstart_batch(self,batch_id):
"""Record a batch as being processed"""self.in_flight_batches[batch_id] = {"start_time": time.time(),"records": [],"status": "processing"}defadd_record(self,batch_id,record_id):
"""Add a record to an in-flight batch"""ifbatch_idinself.in_flight_batches:
self.in_flight_batches[batch_id]["records"].append(record_id)defcomplete_batch(self,batch_id,success):
"""Mark a batch as complete"""ifbatch_idinself.in_flight_batches:
ifsuccess:
# Move batch from in-flight to processedself.processed_batches.add(batch_id)record_count = len(self.in_flight_batches[batch_id]["records"])self.in_flight_batches[batch_id]["status"] = "completed"print(f"Batch {batch_id} completed: {record_count} records")else:
# Mark as failed - would need retry logicself.in_flight_batches[batch_id]["status"] = "failed"print(f"Batch {batch_id} failed")defcheckpoint(self):
"""Create a checkpoint of the current state"""self.last_checkpoint_time = time.time()# In a real implementation, would persist this statecheckpoint_data = {"timestamp": self.last_checkpoint_time,"processed_batches": list(self.processed_batches),"in_flight_batches": self.in_flight_batches}print(f"Checkpoint created at {self.last_checkpoint_time}")returncheckpoint_datadefrestore(self,checkpoint_data):
"""Restore from a checkpoint after failure"""self.last_checkpoint_time = checkpoint_data["timestamp"]self.processed_batches = set(checkpoint_data["processed_batches"])self.in_flight_batches = checkpoint_data["in_flight_batches"]# Need to handle in-flight batchesretry_batches = []forbatch_id,batch_infoinself.in_flight_batches.items():
ifbatch_info["status"] == "processing":
retry_batches.append(batch_id)print(f"Restored checkpoint from {self.last_checkpoint_time}")print(f"Processed batches: {len(self.processed_batches)}")print(f"Batches to retry: {len(retry_batches)}")# In a real implementation, would need to restart these batchesreturnretry_batches# Demonstrate the complexity of checkpoint integrationprint("Simulating Flink checkpointing with HTTP interface...")state = CheckpointState()# Process some batches successfullyforiinrange(5):
batch_id = f"batch_{i}"state.start_batch(batch_id)# Add records to batchforjinrange(100):
state.add_record(batch_id,f"record_{j}")# Complete batchstate.complete_batch(batch_id,True)# Process a batch that will be in-flight during checkpointin_flight_batch = "batch_in_flight"state.start_batch(in_flight_batch)forjinrange(50):
state.add_record(in_flight_batch,f"record_{j}")# Create checkpointcheckpoint_data = state.checkpoint()# Process a bit more dataforjinrange(50,100):
state.add_record(in_flight_batch,f"record_{j}")# Simulate failure before batch completesprint("\nSimulating failure before in-flight batch completes...")# Create new state object (simulating operator restart)new_state = CheckpointState()# Restore from checkpointretry_batches = new_state.restore(checkpoint_data)
defdemonstrate_checkpoint_issues():
"""Show how HTTP interface lacks integration with Flink's checkpointing"""# In Flink's checkpointing mechanism, operators need to:# 1. Snapshot their state (what's been processed)# 2. Restore from snapshot after failure# 3. Ensure exactly-once semantics through transactions# With HTTP interface, we'd need to implement custom logic# Simulate state tracking that would be neededclass CheckpointState:
def__init__(self):
self.last_checkpoint_time = 0self.processed_batches = set()self.in_flight_batches = {}defstart_batch(self,batch_id):
"""Record a batch as being processed"""self.in_flight_batches[batch_id] = {"start_time": time.time(),"records": [],"status": "processing"}defadd_record(self,batch_id,record_id):
"""Add a record to an in-flight batch"""ifbatch_idinself.in_flight_batches:
self.in_flight_batches[batch_id]["records"].append(record_id)defcomplete_batch(self,batch_id,success):
"""Mark a batch as complete"""ifbatch_idinself.in_flight_batches:
ifsuccess:
# Move batch from in-flight to processedself.processed_batches.add(batch_id)record_count = len(self.in_flight_batches[batch_id]["records"])self.in_flight_batches[batch_id]["status"] = "completed"print(f"Batch {batch_id} completed: {record_count} records")else:
# Mark as failed - would need retry logicself.in_flight_batches[batch_id]["status"] = "failed"print(f"Batch {batch_id} failed")defcheckpoint(self):
"""Create a checkpoint of the current state"""self.last_checkpoint_time = time.time()# In a real implementation, would persist this statecheckpoint_data = {"timestamp": self.last_checkpoint_time,"processed_batches": list(self.processed_batches),"in_flight_batches": self.in_flight_batches}print(f"Checkpoint created at {self.last_checkpoint_time}")returncheckpoint_datadefrestore(self,checkpoint_data):
"""Restore from a checkpoint after failure"""self.last_checkpoint_time = checkpoint_data["timestamp"]self.processed_batches = set(checkpoint_data["processed_batches"])self.in_flight_batches = checkpoint_data["in_flight_batches"]# Need to handle in-flight batchesretry_batches = []forbatch_id,batch_infoinself.in_flight_batches.items():
ifbatch_info["status"] == "processing":
retry_batches.append(batch_id)print(f"Restored checkpoint from {self.last_checkpoint_time}")print(f"Processed batches: {len(self.processed_batches)}")print(f"Batches to retry: {len(retry_batches)}")# In a real implementation, would need to restart these batchesreturnretry_batches# Demonstrate the complexity of checkpoint integrationprint("Simulating Flink checkpointing with HTTP interface...")state = CheckpointState()# Process some batches successfullyforiinrange(5):
batch_id = f"batch_{i}"state.start_batch(batch_id)# Add records to batchforjinrange(100):
state.add_record(batch_id,f"record_{j}")# Complete batchstate.complete_batch(batch_id,True)# Process a batch that will be in-flight during checkpointin_flight_batch = "batch_in_flight"state.start_batch(in_flight_batch)forjinrange(50):
state.add_record(in_flight_batch,f"record_{j}")# Create checkpointcheckpoint_data = state.checkpoint()# Process a bit more dataforjinrange(50,100):
state.add_record(in_flight_batch,f"record_{j}")# Simulate failure before batch completesprint("\nSimulating failure before in-flight batch completes...")# Create new state object (simulating operator restart)new_state = CheckpointState()# Restore from checkpointretry_batches = new_state.restore(checkpoint_data)
defdemonstrate_checkpoint_issues():
"""Show how HTTP interface lacks integration with Flink's checkpointing"""# In Flink's checkpointing mechanism, operators need to:# 1. Snapshot their state (what's been processed)# 2. Restore from snapshot after failure# 3. Ensure exactly-once semantics through transactions# With HTTP interface, we'd need to implement custom logic# Simulate state tracking that would be neededclass CheckpointState:
def__init__(self):
self.last_checkpoint_time = 0self.processed_batches = set()self.in_flight_batches = {}defstart_batch(self,batch_id):
"""Record a batch as being processed"""self.in_flight_batches[batch_id] = {"start_time": time.time(),"records": [],"status": "processing"}defadd_record(self,batch_id,record_id):
"""Add a record to an in-flight batch"""ifbatch_idinself.in_flight_batches:
self.in_flight_batches[batch_id]["records"].append(record_id)defcomplete_batch(self,batch_id,success):
"""Mark a batch as complete"""ifbatch_idinself.in_flight_batches:
ifsuccess:
# Move batch from in-flight to processedself.processed_batches.add(batch_id)record_count = len(self.in_flight_batches[batch_id]["records"])self.in_flight_batches[batch_id]["status"] = "completed"print(f"Batch {batch_id} completed: {record_count} records")else:
# Mark as failed - would need retry logicself.in_flight_batches[batch_id]["status"] = "failed"print(f"Batch {batch_id} failed")defcheckpoint(self):
"""Create a checkpoint of the current state"""self.last_checkpoint_time = time.time()# In a real implementation, would persist this statecheckpoint_data = {"timestamp": self.last_checkpoint_time,"processed_batches": list(self.processed_batches),"in_flight_batches": self.in_flight_batches}print(f"Checkpoint created at {self.last_checkpoint_time}")returncheckpoint_datadefrestore(self,checkpoint_data):
"""Restore from a checkpoint after failure"""self.last_checkpoint_time = checkpoint_data["timestamp"]self.processed_batches = set(checkpoint_data["processed_batches"])self.in_flight_batches = checkpoint_data["in_flight_batches"]# Need to handle in-flight batchesretry_batches = []forbatch_id,batch_infoinself.in_flight_batches.items():
ifbatch_info["status"] == "processing":
retry_batches.append(batch_id)print(f"Restored checkpoint from {self.last_checkpoint_time}")print(f"Processed batches: {len(self.processed_batches)}")print(f"Batches to retry: {len(retry_batches)}")# In a real implementation, would need to restart these batchesreturnretry_batches# Demonstrate the complexity of checkpoint integrationprint("Simulating Flink checkpointing with HTTP interface...")state = CheckpointState()# Process some batches successfullyforiinrange(5):
batch_id = f"batch_{i}"state.start_batch(batch_id)# Add records to batchforjinrange(100):
state.add_record(batch_id,f"record_{j}")# Complete batchstate.complete_batch(batch_id,True)# Process a batch that will be in-flight during checkpointin_flight_batch = "batch_in_flight"state.start_batch(in_flight_batch)forjinrange(50):
state.add_record(in_flight_batch,f"record_{j}")# Create checkpointcheckpoint_data = state.checkpoint()# Process a bit more dataforjinrange(50,100):
state.add_record(in_flight_batch,f"record_{j}")# Simulate failure before batch completesprint("\nSimulating failure before in-flight batch completes...")# Create new state object (simulating operator restart)new_state = CheckpointState()# Restore from checkpointretry_batches = new_state.restore(checkpoint_data)
With HTTP interface, you must implement:
Custom state tracking for exactly-once semantics.
Deduplication mechanisms for retry scenarios.
Coordination between Flink checkpoints and ClickHouse transactions.
Recovery logic for in-flight batches.
The HTTP Interface approach has these key limitations:
Custom Error Handling: Engineers must implement sophisticated error detection, recovery, and retry mechanisms.
Manual Concurrency Control: No built-in connection pooling or backpressure mechanisms.
No Checkpoint Integration: Lack of integration with Flink's checkpointing system.
Batch Management Complexity: Determining optimal batch sizes and flush intervals becomes a manual tuning exercise.
The HTTP interface provides better performance than JDBC by bypassing middleware overhead, but shifts significant complexity to application code. Organizations requiring stronger consistency guarantees often turn to more sophisticated patterns like two-phase commits to bridge the architectural divide.
Two-Phase Commit Pattern
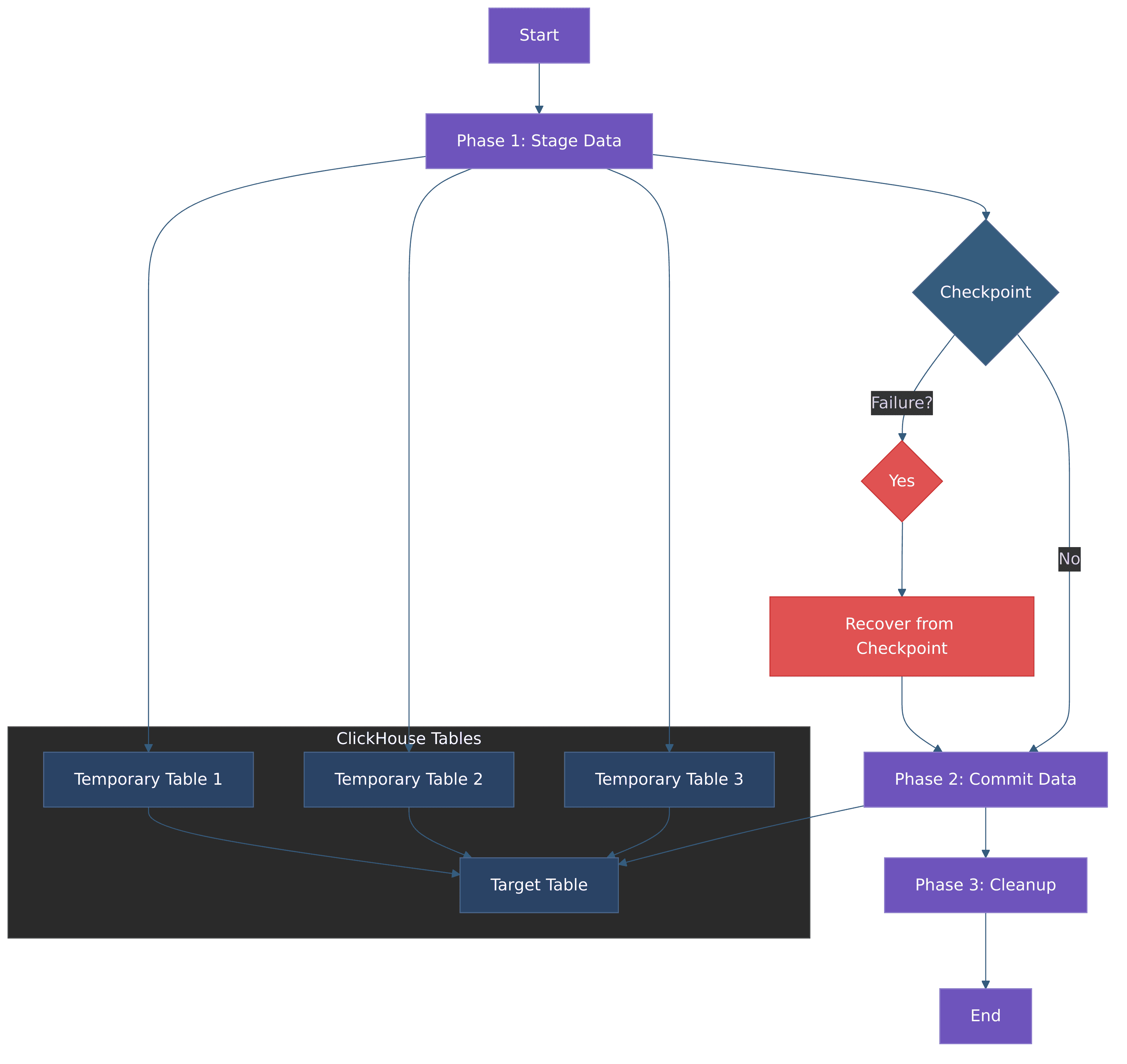
The two-phase commit pattern attempts to bridge the transactional gap between Flink and ClickHouse by implementing a form of distributed transaction protocol. This approach uses temporary staging tables in ClickHouse to implement prepare (stage) and commit phases that can be coordinated with Flink's checkpointing mechanism.
In this example, we implement a custom Flink sink that follows the two-phase commit pattern, first staging data in temporary tables before committing it to the final destination:
class ClickHouseTwoPhaseCommitSink(SinkFunction):
"""A sink that implements a two-phase commit pattern for ClickHouse"""def__init__(self,host='localhost',port=8123,target_table='user_events',batch_size=1000):
self.host = hostself.port = portself.target_table = target_tableself.batch_size = batch_sizeself.client = Noneself.temp_table = Noneself.batch = []self.transaction_id = Nonedefopen(self,runtime_context: RuntimeContext):
"""Initialize the sink and create temporary table"""self.client = clickhouse_connect.get_client(host=self.host,port=self.port)self._create_temp_table()self.transaction_id = str(uuid.uuid4())self.batch = []def_create_temp_table(self):
"""Create a temporary table for staging data"""# Generate a unique name for the temporary tabletable_hash = hashlib.md5(f"{self.target_table}_{time.time()}".encode()).hexdigest()[:8]self.temp_table = f"temp_{self.target_table}_{table_hash}"# Create a temporary table with the same structure plus transaction trackingself.client.command(f"""
CREATE TABLE IF NOT EXISTS {self.temp_table} (
event_id String,
user_id String,
event_type String,
event_time DateTime64(3),
properties String,
_transaction_id String
) ENGINE = MergeTree()
ORDER BY (event_time, user_id)
""")def_stage_batch(self):
"""Stage batch data in temporary table (first phase)"""ifnotself.batch:
return# Prepare data for insertion with transaction IDformatted_data = []forrecordinself.batch:
record_with_tx = dict(record)record_with_tx['_transaction_id'] = self.transaction_idformatted_data.append(record_with_tx)# Insert into temporary tableself.client.insert(self.temp_table,formatted_data,column_names=['event_id','user_id','event_type','event_time','properties','_transaction_id'])self.batch = []defcommit_transaction(self):
"""Commit staged data to target table (second phase)"""# Move data from temporary to target tableself.client.command(f"""
INSERT INTO {self.target_table}
SELECT * FROM {self.temp_table}
WHERE _transaction_id = '{self.transaction_id}'
""")# Clear temporary tableself.client.command(f"""
ALTER TABLE {self.temp_table}
DELETE WHERE _transaction_id = '{self.transaction_id}'
""")
class ClickHouseTwoPhaseCommitSink(SinkFunction):
"""A sink that implements a two-phase commit pattern for ClickHouse"""def__init__(self,host='localhost',port=8123,target_table='user_events',batch_size=1000):
self.host = hostself.port = portself.target_table = target_tableself.batch_size = batch_sizeself.client = Noneself.temp_table = Noneself.batch = []self.transaction_id = Nonedefopen(self,runtime_context: RuntimeContext):
"""Initialize the sink and create temporary table"""self.client = clickhouse_connect.get_client(host=self.host,port=self.port)self._create_temp_table()self.transaction_id = str(uuid.uuid4())self.batch = []def_create_temp_table(self):
"""Create a temporary table for staging data"""# Generate a unique name for the temporary tabletable_hash = hashlib.md5(f"{self.target_table}_{time.time()}".encode()).hexdigest()[:8]self.temp_table = f"temp_{self.target_table}_{table_hash}"# Create a temporary table with the same structure plus transaction trackingself.client.command(f"""
CREATE TABLE IF NOT EXISTS {self.temp_table} (
event_id String,
user_id String,
event_type String,
event_time DateTime64(3),
properties String,
_transaction_id String
) ENGINE = MergeTree()
ORDER BY (event_time, user_id)
""")def_stage_batch(self):
"""Stage batch data in temporary table (first phase)"""ifnotself.batch:
return# Prepare data for insertion with transaction IDformatted_data = []forrecordinself.batch:
record_with_tx = dict(record)record_with_tx['_transaction_id'] = self.transaction_idformatted_data.append(record_with_tx)# Insert into temporary tableself.client.insert(self.temp_table,formatted_data,column_names=['event_id','user_id','event_type','event_time','properties','_transaction_id'])self.batch = []defcommit_transaction(self):
"""Commit staged data to target table (second phase)"""# Move data from temporary to target tableself.client.command(f"""
INSERT INTO {self.target_table}
SELECT * FROM {self.temp_table}
WHERE _transaction_id = '{self.transaction_id}'
""")# Clear temporary tableself.client.command(f"""
ALTER TABLE {self.temp_table}
DELETE WHERE _transaction_id = '{self.transaction_id}'
""")
class ClickHouseTwoPhaseCommitSink(SinkFunction):
"""A sink that implements a two-phase commit pattern for ClickHouse"""def__init__(self,host='localhost',port=8123,target_table='user_events',batch_size=1000):
self.host = hostself.port = portself.target_table = target_tableself.batch_size = batch_sizeself.client = Noneself.temp_table = Noneself.batch = []self.transaction_id = Nonedefopen(self,runtime_context: RuntimeContext):
"""Initialize the sink and create temporary table"""self.client = clickhouse_connect.get_client(host=self.host,port=self.port)self._create_temp_table()self.transaction_id = str(uuid.uuid4())self.batch = []def_create_temp_table(self):
"""Create a temporary table for staging data"""# Generate a unique name for the temporary tabletable_hash = hashlib.md5(f"{self.target_table}_{time.time()}".encode()).hexdigest()[:8]self.temp_table = f"temp_{self.target_table}_{table_hash}"# Create a temporary table with the same structure plus transaction trackingself.client.command(f"""
CREATE TABLE IF NOT EXISTS {self.temp_table} (
event_id String,
user_id String,
event_type String,
event_time DateTime64(3),
properties String,
_transaction_id String
) ENGINE = MergeTree()
ORDER BY (event_time, user_id)
""")def_stage_batch(self):
"""Stage batch data in temporary table (first phase)"""ifnotself.batch:
return# Prepare data for insertion with transaction IDformatted_data = []forrecordinself.batch:
record_with_tx = dict(record)record_with_tx['_transaction_id'] = self.transaction_idformatted_data.append(record_with_tx)# Insert into temporary tableself.client.insert(self.temp_table,formatted_data,column_names=['event_id','user_id','event_type','event_time','properties','_transaction_id'])self.batch = []defcommit_transaction(self):
"""Commit staged data to target table (second phase)"""# Move data from temporary to target tableself.client.command(f"""
INSERT INTO {self.target_table}
SELECT * FROM {self.temp_table}
WHERE _transaction_id = '{self.transaction_id}'
""")# Clear temporary tableself.client.command(f"""
ALTER TABLE {self.temp_table}
DELETE WHERE _transaction_id = '{self.transaction_id}'
""")
# Set up the Flink environmentenv = StreamExecutionEnvironment.get_execution_environment()env.enable_checkpointing(60000)# Enable checkpointing every 60 seconds# Create a sample data stream# In a real application, this would come from Kafka, files, or other sourcesstream = env.from_collection(generate_sample_data())# Apply the custom ClickHouse sinkclickhouse_sink = ClickHouseTwoPhaseCommitSink(host='localhost',port=8123,target_table='user_events',batch_size=1000)stream.add_sink(clickhouse_sink)# Execute the jobenv.execute("ClickHouse Two-Phase Commit Example")
# Set up the Flink environmentenv = StreamExecutionEnvironment.get_execution_environment()env.enable_checkpointing(60000)# Enable checkpointing every 60 seconds# Create a sample data stream# In a real application, this would come from Kafka, files, or other sourcesstream = env.from_collection(generate_sample_data())# Apply the custom ClickHouse sinkclickhouse_sink = ClickHouseTwoPhaseCommitSink(host='localhost',port=8123,target_table='user_events',batch_size=1000)stream.add_sink(clickhouse_sink)# Execute the jobenv.execute("ClickHouse Two-Phase Commit Example")
# Set up the Flink environmentenv = StreamExecutionEnvironment.get_execution_environment()env.enable_checkpointing(60000)# Enable checkpointing every 60 seconds# Create a sample data stream# In a real application, this would come from Kafka, files, or other sourcesstream = env.from_collection(generate_sample_data())# Apply the custom ClickHouse sinkclickhouse_sink = ClickHouseTwoPhaseCommitSink(host='localhost',port=8123,target_table='user_events',batch_size=1000)stream.add_sink(clickhouse_sink)# Execute the jobenv.execute("ClickHouse Two-Phase Commit Example")
defmeasure_performance_impact():
"""Compare two-phase commit vs direct inserts performance"""client = clickhouse_connect.get_client(host='localhost',port=8123)batch_size = 10000# Generate test data (omitted for brevity)data = [/* batchof10000records */]data_with_tx = [/* samedatawithtransactionIDs */]# Measure direct insert performancestart_time = time.time()client.insert("user_events_direct",data,column_names=[...])direct_time = time.time() - start_timeprint(f"Direct insert: {batch_size} records in {direct_time:.2f} seconds")# Measure two-phase commit (simplified)# Phase 1: Stage to temp table# Phase 2: Commit to target table# Phase 3: Clean up temp table# Results comparisonprint(f"Two-phase commit is {total_2pc_time/direct_time:.2f}x slower")
defmeasure_performance_impact():
"""Compare two-phase commit vs direct inserts performance"""client = clickhouse_connect.get_client(host='localhost',port=8123)batch_size = 10000# Generate test data (omitted for brevity)data = [/* batchof10000records */]data_with_tx = [/* samedatawithtransactionIDs */]# Measure direct insert performancestart_time = time.time()client.insert("user_events_direct",data,column_names=[...])direct_time = time.time() - start_timeprint(f"Direct insert: {batch_size} records in {direct_time:.2f} seconds")# Measure two-phase commit (simplified)# Phase 1: Stage to temp table# Phase 2: Commit to target table# Phase 3: Clean up temp table# Results comparisonprint(f"Two-phase commit is {total_2pc_time/direct_time:.2f}x slower")
defmeasure_performance_impact():
"""Compare two-phase commit vs direct inserts performance"""client = clickhouse_connect.get_client(host='localhost',port=8123)batch_size = 10000# Generate test data (omitted for brevity)data = [/* batchof10000records */]data_with_tx = [/* samedatawithtransactionIDs */]# Measure direct insert performancestart_time = time.time()client.insert("user_events_direct",data,column_names=[...])direct_time = time.time() - start_timeprint(f"Direct insert: {batch_size} records in {direct_time:.2f} seconds")# Measure two-phase commit (simplified)# Phase 1: Stage to temp table# Phase 2: Commit to target table# Phase 3: Clean up temp table# Results comparisonprint(f"Two-phase commit is {total_2pc_time/direct_time:.2f}x slower")
Returning the following:
The diagram below illustrates the workflow of the two-phase commit process and how temporary tables in ClickHouse are used to ensure data consistency:
The coordination complexity becomes particularly evident during failure scenarios:
defdemonstrate_coordination_complexity():
"""Show the complexity of coordinating two-phase commits with Flink checkpoints"""# Create a mapping table to track checkpoints and transactionsclient.command("DROP TABLE IF EXISTS checkpoint_transactions")client.command("""
CREATE TABLE checkpoint_transactions (
checkpoint_id String,
transaction_id String,
temp_table String,
status String,
created_at DateTime64(3)
) ENGINE = MergeTree()
ORDER BY checkpoint_id
""")# Simulate a series of checkpoints and commit/abort decisionsscenarios = [{"checkpoint_id": "cp1","action": "commit","records": 1000},{"checkpoint_id": "cp2","action": "abort","records": 1500},{"checkpoint_id": "cp3","action": "commit","records": 2000},{"checkpoint_id": "cp4","action": "abort","records": 1200},{"checkpoint_id": "cp5","action": "commit","records": 1800},]# Process each scenarioforscenarioinscenarios:
# Create temporary table for this checkpointcheckpoint_id = scenario["checkpoint_id"]transaction_id = str(uuid.uuid4())table_hash = hashlib.md5(f"cp_{checkpoint_id}_{time.time()}".encode()).hexdigest()[:8]temp_table = f"temp_events_{table_hash}"# Record checkpoint-transaction mappingclient.insert("checkpoint_transactions",[[checkpoint_id,transaction_id,temp_table,"pending",pd.Timestamp.now()]],column_names=['checkpoint_id','transaction_id','temp_table','status','created_at'])# Simulate checkpoint completion and actionifscenario["action"] == "commit":
# Move data from temporary to target tableclient.command(f"""
INSERT INTO user_events
SELECT * FROM {temp_table}
WHERE _transaction_id = '{transaction_id}'
""")# Update statusclient.command(f"""
ALTER TABLE checkpoint_transactions
UPDATE status = 'committed'
WHERE checkpoint_id = '{checkpoint_id}'
""")else: # abort# Update statusclient.command(f"""
ALTER TABLE checkpoint_transactions
UPDATE status = 'aborted'
WHERE checkpoint_id = '{checkpoint_id}'
""")
defdemonstrate_coordination_complexity():
"""Show the complexity of coordinating two-phase commits with Flink checkpoints"""# Create a mapping table to track checkpoints and transactionsclient.command("DROP TABLE IF EXISTS checkpoint_transactions")client.command("""
CREATE TABLE checkpoint_transactions (
checkpoint_id String,
transaction_id String,
temp_table String,
status String,
created_at DateTime64(3)
) ENGINE = MergeTree()
ORDER BY checkpoint_id
""")# Simulate a series of checkpoints and commit/abort decisionsscenarios = [{"checkpoint_id": "cp1","action": "commit","records": 1000},{"checkpoint_id": "cp2","action": "abort","records": 1500},{"checkpoint_id": "cp3","action": "commit","records": 2000},{"checkpoint_id": "cp4","action": "abort","records": 1200},{"checkpoint_id": "cp5","action": "commit","records": 1800},]# Process each scenarioforscenarioinscenarios:
# Create temporary table for this checkpointcheckpoint_id = scenario["checkpoint_id"]transaction_id = str(uuid.uuid4())table_hash = hashlib.md5(f"cp_{checkpoint_id}_{time.time()}".encode()).hexdigest()[:8]temp_table = f"temp_events_{table_hash}"# Record checkpoint-transaction mappingclient.insert("checkpoint_transactions",[[checkpoint_id,transaction_id,temp_table,"pending",pd.Timestamp.now()]],column_names=['checkpoint_id','transaction_id','temp_table','status','created_at'])# Simulate checkpoint completion and actionifscenario["action"] == "commit":
# Move data from temporary to target tableclient.command(f"""
INSERT INTO user_events
SELECT * FROM {temp_table}
WHERE _transaction_id = '{transaction_id}'
""")# Update statusclient.command(f"""
ALTER TABLE checkpoint_transactions
UPDATE status = 'committed'
WHERE checkpoint_id = '{checkpoint_id}'
""")else: # abort# Update statusclient.command(f"""
ALTER TABLE checkpoint_transactions
UPDATE status = 'aborted'
WHERE checkpoint_id = '{checkpoint_id}'
""")
defdemonstrate_coordination_complexity():
"""Show the complexity of coordinating two-phase commits with Flink checkpoints"""# Create a mapping table to track checkpoints and transactionsclient.command("DROP TABLE IF EXISTS checkpoint_transactions")client.command("""
CREATE TABLE checkpoint_transactions (
checkpoint_id String,
transaction_id String,
temp_table String,
status String,
created_at DateTime64(3)
) ENGINE = MergeTree()
ORDER BY checkpoint_id
""")# Simulate a series of checkpoints and commit/abort decisionsscenarios = [{"checkpoint_id": "cp1","action": "commit","records": 1000},{"checkpoint_id": "cp2","action": "abort","records": 1500},{"checkpoint_id": "cp3","action": "commit","records": 2000},{"checkpoint_id": "cp4","action": "abort","records": 1200},{"checkpoint_id": "cp5","action": "commit","records": 1800},]# Process each scenarioforscenarioinscenarios:
# Create temporary table for this checkpointcheckpoint_id = scenario["checkpoint_id"]transaction_id = str(uuid.uuid4())table_hash = hashlib.md5(f"cp_{checkpoint_id}_{time.time()}".encode()).hexdigest()[:8]temp_table = f"temp_events_{table_hash}"# Record checkpoint-transaction mappingclient.insert("checkpoint_transactions",[[checkpoint_id,transaction_id,temp_table,"pending",pd.Timestamp.now()]],column_names=['checkpoint_id','transaction_id','temp_table','status','created_at'])# Simulate checkpoint completion and actionifscenario["action"] == "commit":
# Move data from temporary to target tableclient.command(f"""
INSERT INTO user_events
SELECT * FROM {temp_table}
WHERE _transaction_id = '{transaction_id}'
""")# Update statusclient.command(f"""
ALTER TABLE checkpoint_transactions
UPDATE status = 'committed'
WHERE checkpoint_id = '{checkpoint_id}'
""")else: # abort# Update statusclient.command(f"""
ALTER TABLE checkpoint_transactions
UPDATE status = 'aborted'
WHERE checkpoint_id = '{checkpoint_id}'
""")
Returning the following:
Coordination complexities demonstrated:
Tracking checkpoint-transaction relationships.
Handling recovery for incomplete transactions.
Managing cleanup of temporary tables.
Ensuring atomicity of two-phase operations.
So, in conclusion, the two-phase commit pattern has five major limitations:
Higher Latency: Multi-stage processing significantly increases end-to-end processing time
Complex Implementation: Error handling and recovery logic add substantial complexity
Resource Overhead: Additional queries and table operations impact overall system performance
Operational Complexity: Monitoring and managing temporary tables adds operational burden
Though the two-phase commit pattern approximates the transactional guarantees Flink expects, its operational complexity and performance impact often prove prohibitive at scale. This leads some organizations to reconsider their architecture entirely, introducing message brokers like Kafka as intermediaries.
Kafka as Intermediary Layer
The Kafka intermediary approach avoids direct integration between Flink and ClickHouse by introducing Apache Kafka as a message broker between them. Flink writes to Kafka topics, and ClickHouse consumes from these topics independently.
# In Flink application - write results to Kafkaenv = StreamExecutionEnvironment.get_execution_environment()settings = EnvironmentSettings.new_instance().in_streaming_mode().build()t_env = StreamTableEnvironment.create(env,settings)# Add Required Kafka Connector JARt_env.get_config().get_configuration().set_string("pipeline.jars","file:///path/to/flink-connector-kafka.jar")# Define a Source Tablet_env.execute_sql("""
CREATE TEMPORARY TABLE source_events (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'datagen',
'rows-per-second' = '100',
'fields.user_id.kind' = 'random',
'fields.event_type.kind' = 'random'
)
""")# Define a Kafka Sink Tablet_env.execute_sql("""
CREATE TABLE kafka_events (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user-events',
'properties.bootstrap.servers' = 'kafka:9092',
'format' = 'json'
)
""")# Insert Data From Source to Kafkat_env.execute_sql("""
INSERT INTO kafka_events
SELECT event_id, user_id, event_type, event_time, properties
FROM source_events
""")
# In Flink application - write results to Kafkaenv = StreamExecutionEnvironment.get_execution_environment()settings = EnvironmentSettings.new_instance().in_streaming_mode().build()t_env = StreamTableEnvironment.create(env,settings)# Add Required Kafka Connector JARt_env.get_config().get_configuration().set_string("pipeline.jars","file:///path/to/flink-connector-kafka.jar")# Define a Source Tablet_env.execute_sql("""
CREATE TEMPORARY TABLE source_events (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'datagen',
'rows-per-second' = '100',
'fields.user_id.kind' = 'random',
'fields.event_type.kind' = 'random'
)
""")# Define a Kafka Sink Tablet_env.execute_sql("""
CREATE TABLE kafka_events (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user-events',
'properties.bootstrap.servers' = 'kafka:9092',
'format' = 'json'
)
""")# Insert Data From Source to Kafkat_env.execute_sql("""
INSERT INTO kafka_events
SELECT event_id, user_id, event_type, event_time, properties
FROM source_events
""")
# In Flink application - write results to Kafkaenv = StreamExecutionEnvironment.get_execution_environment()settings = EnvironmentSettings.new_instance().in_streaming_mode().build()t_env = StreamTableEnvironment.create(env,settings)# Add Required Kafka Connector JARt_env.get_config().get_configuration().set_string("pipeline.jars","file:///path/to/flink-connector-kafka.jar")# Define a Source Tablet_env.execute_sql("""
CREATE TEMPORARY TABLE source_events (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'datagen',
'rows-per-second' = '100',
'fields.user_id.kind' = 'random',
'fields.event_type.kind' = 'random'
)
""")# Define a Kafka Sink Tablet_env.execute_sql("""
CREATE TABLE kafka_events (
event_id STRING,
user_id STRING,
event_type STRING,
event_time TIMESTAMP(3),
properties STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user-events',
'properties.bootstrap.servers' = 'kafka:9092',
'format' = 'json'
)
""")# Insert Data From Source to Kafkat_env.execute_sql("""
INSERT INTO kafka_events
SELECT event_id, user_id, event_type, event_time, properties
FROM source_events
""")
On the ClickHouse side, we create a Kafka engine table to consume the topic:
-- Create a ClickHouse table using Kafka engine to act as a queue for incoming dataCREATETABLE user_events_queue (
event_id String,
user_id String,
event_type String,
event_time DateTime,
properties String
) ENGINE = Kafka
SETTINGS kafka_broker_list = 'kafka:9092',
kafka_topic_list = 'user-events',
kafka_group_name = 'clickhouse_consumer_group',
kafka_format = 'JSONEachRow';
-- Create a materialized view to transform incoming Kafka data and store in target tableCREATE MATERIALIZED VIEW user_events_mv TO user_events ASSELECT
event_id,
user_id,
event_type,
event_time,
properties
FROM
-- Create a ClickHouse table using Kafka engine to act as a queue for incoming dataCREATETABLE user_events_queue (
event_id String,
user_id String,
event_type String,
event_time DateTime,
properties String
) ENGINE = Kafka
SETTINGS kafka_broker_list = 'kafka:9092',
kafka_topic_list = 'user-events',
kafka_group_name = 'clickhouse_consumer_group',
kafka_format = 'JSONEachRow';
-- Create a materialized view to transform incoming Kafka data and store in target tableCREATE MATERIALIZED VIEW user_events_mv TO user_events ASSELECT
event_id,
user_id,
event_type,
event_time,
properties
FROM
-- Create a ClickHouse table using Kafka engine to act as a queue for incoming dataCREATETABLE user_events_queue (
event_id String,
user_id String,
event_type String,
event_time DateTime,
properties String
) ENGINE = Kafka
SETTINGS kafka_broker_list = 'kafka:9092',
kafka_topic_list = 'user-events',
kafka_group_name = 'clickhouse_consumer_group',
kafka_format = 'JSONEachRow';
-- Create a materialized view to transform incoming Kafka data and store in target tableCREATE MATERIALIZED VIEW user_events_mv TO user_events ASSELECT
event_id,
user_id,
event_type,
event_time,
properties
FROM
This approach decouples the writing and reading components, allowing each system to operate independently. Kafka serves as a buffer that can handle backpressure and provides its own consistency guarantees. However, this introduces additional infrastructure complexity and potential latency.
The following diagram illustrates the data flow when using Kafka as an intermediary between Flink and ClickHouse:
Testing for our simulation reveals significant latency impact compared to direct insertion:
The exactly-once processing challenges becomes apparent during recovery scenarios:
The Kafka intermediary approach has these significant limitations:
Increased Infrastructure Complexity: Three separate distributed systems to manage.
Higher Latency: Additional network hops and processing stages.
Exactly-Once Challenges: Coordination required across multiple systems.
Operational Overhead: More components to monitor and maintain.
Increased Costs: Additional hardware, software, and operational expenses.
The Kafka intermediary approach effectively decouples Flink and ClickHouse, but introduces a third distributed system to manage and coordinate. This additional complexity highlights the fundamental challenge: there is no perfect solution for connecting these architecturally disparate systems.
Approach Comparison
After evaluating four integration approaches between Flink and ClickHouse, a clear pattern of trade-offs emerges. Each method attempts to bridge the architectural gap between these systems, but introduces its own limitations that impact reliability, performance, and operational complexity. The table below summarizes the key limitations of each approach based on our testing and analysis.
Integration Approach
Key Limitations
JDBC Connector
• Connection pool bottlenecks severely limit throughput
• No integration with Flink's checkpointing mechanism
• Performance degradation at scale due to JDBC overhead
• Manual schema synchronization required
• Limited error handling capabilities
HTTP Interface
• Custom error handling complexity with no built-in recovery
• Manual concurrency control without proper backpressure
• No checkpoint integration for exactly-once processing
Each approach attempts to solve the integration challenge, but none provides an ideal solution.
Last Thoughts
The lack of a native connector between Flink and ClickHouse creates significant engineering challenges that force teams to make difficult trade-offs. Whether prioritizing consistency, performance, or operational simplicity, no single approach provides a perfect solution.
In practice, most teams select an integration method based on their specific requirements and constraints. Organizations with strict consistency needs might accept the operational burden of two-phase commits, while those prioritizing simplicity might tolerate the potential duplicates of a JDBC solution.
If the challenges outlined in this article have convinced you to explore other options, our article Alternatives to Flink for ClickHouse Integration examines several alternatives that may better meet your operational and performance requirements.