ljn
Product Updates
Teams kept asking if Glassflow would scale, so we rebuilt it to grow from small to massive workloads without changing your pipeline.
Written by
Armend Avdijaj
-

TL;DR:
Glassflow sets a new benchmark for high-throughput ClickHouse ingestion and transformation.
Scale beyond 500,000 records per second within a single pipeline.
New horizontal scaling approach reaches 500k+ recs/sec through multiple replicas
High throughput works for flexible transformations, stateful transformations and longer time windows
For more details, check our Glassflow performance benchmarking page
I hear it in almost every conversation I have with data engineers. The question is always the same:
Can GlassFlow handle my current load, and will it also handle my load in the future?
I get why people are asking this. If you are responsible for a ClickHouse pipeline, you are making a long-term decision. You’re looking for a partner, not a bottleneck. You need an architecture that scales with you, not one you’ll outgrow in six months.
Today, I have a definitive answer.
Yes. Glassflow is built to handle your load today—and whatever scale you hit tomorrow.
And I do not say that lightly. Our team spent the last few months rebuilding Glassflow's scaling from the ground up.
What we achieved
We tested Glassflow on a Kafka-to-ClickHouse pipeline under sustained load and scaled it by increasing the number of replicas. We ingested 70m events and observed how the product is reacting.
The key result is simple:
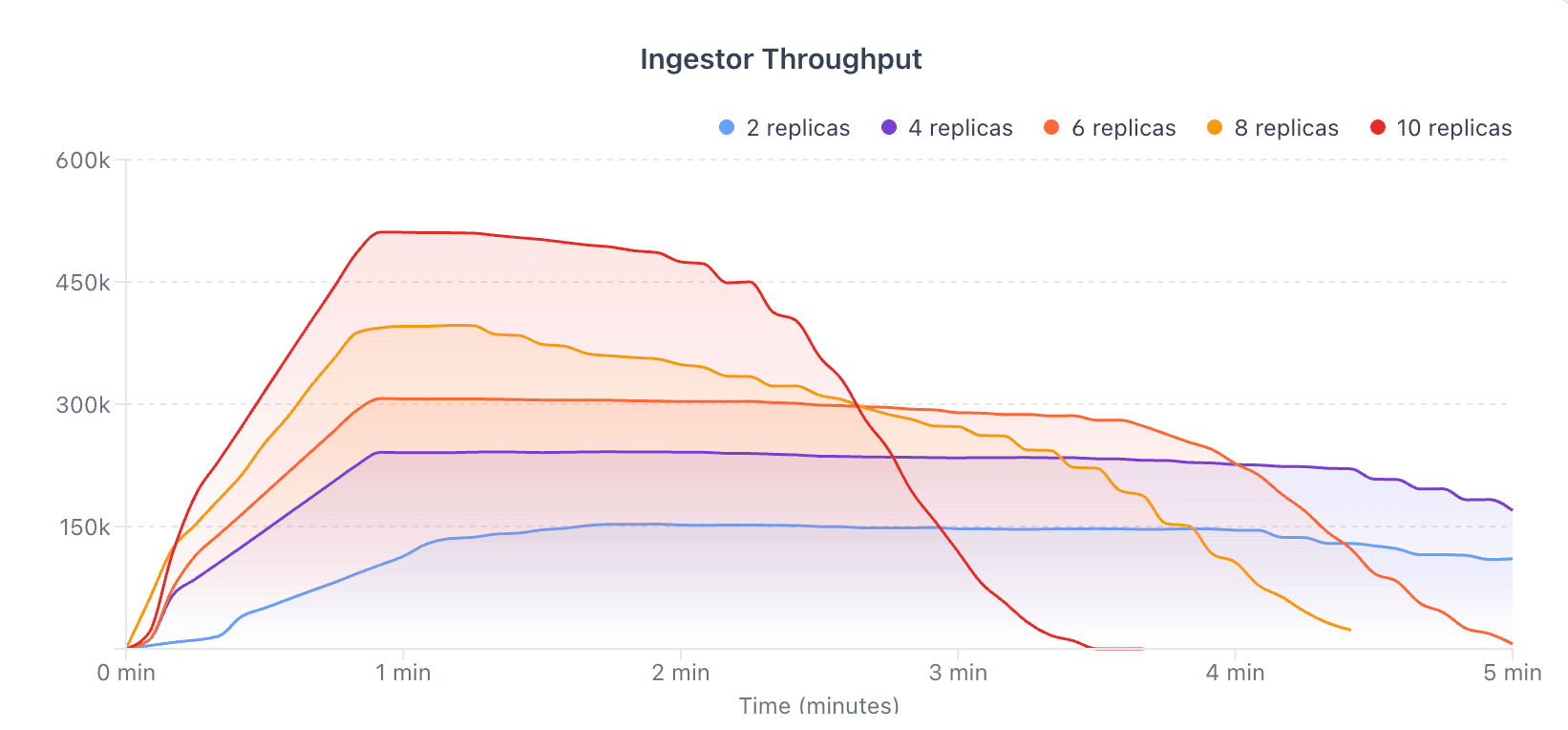
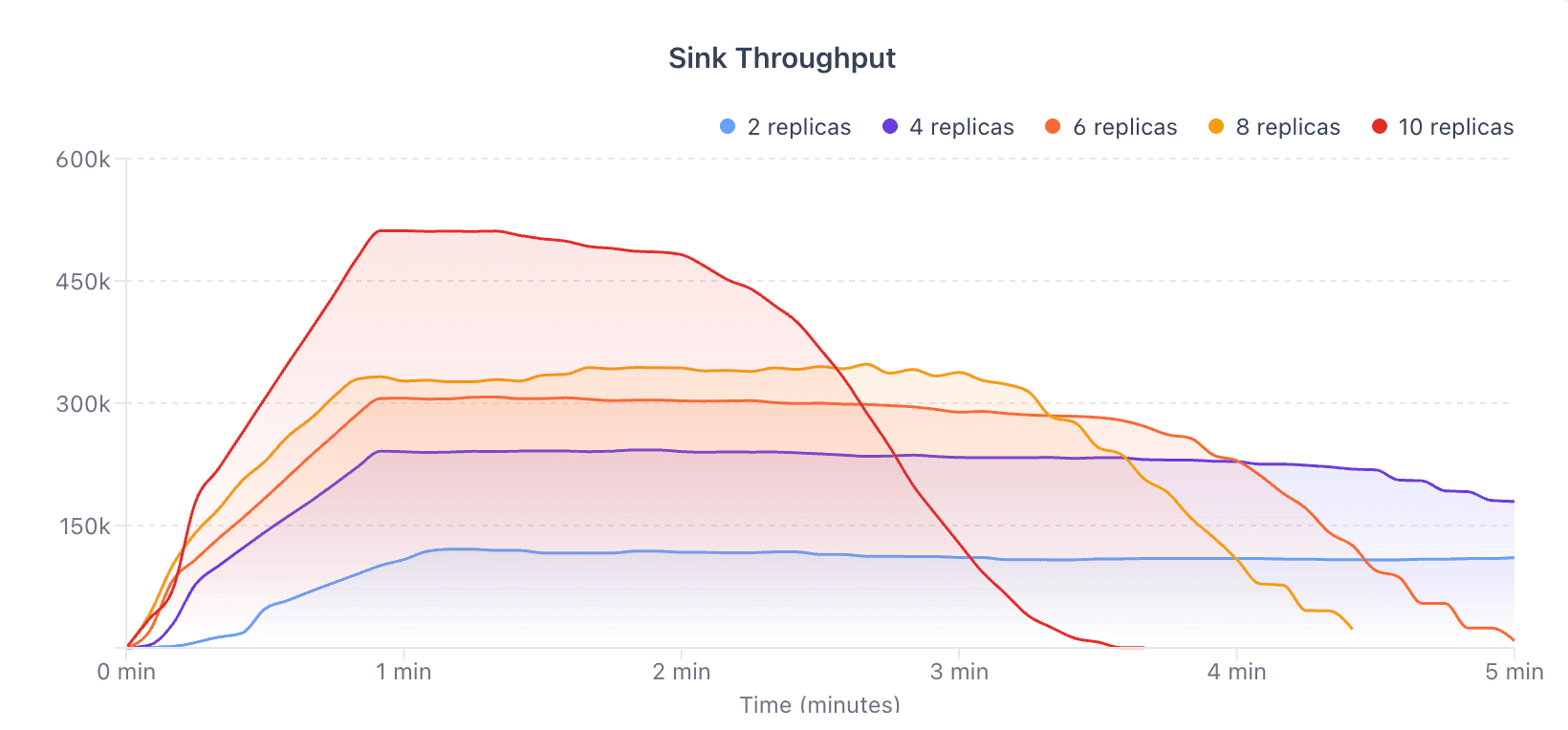
(Full charts and details here).
Our throughput scales linearly. As we added capacity, performance followed in a predictable curve.
At higher replica counts, we hit the 500,000 recs/sec milestone—without compromising end-to-end processing. Not just ingestion, but transformation and delivery into ClickHouse.
Take a look at the scaling curve below. Each added replica translates directly into higher throughput.:
Throughput increases consistently
The system keeps behaving the same way
There is no sudden bottleneck or drop-off
That is what the performance charts show: not just that Glassflow is fast, but that it scales cleanly.
What does it mean for our users?
The first implication is simple.
Glassflow becomes one of the most scalable ingestion systems for ClickHouse pipelines.
But more importantly, it changes how you scale.
Most systems force you into complexity as you grow. You start with one pipeline, then at some point you need to split it: multiple consumers, multiple instances, different pipelines reading from the same source. Things get harder to reason about very quickly.
We took a different approach.
Glassflow scales horizontally within a single pipeline.
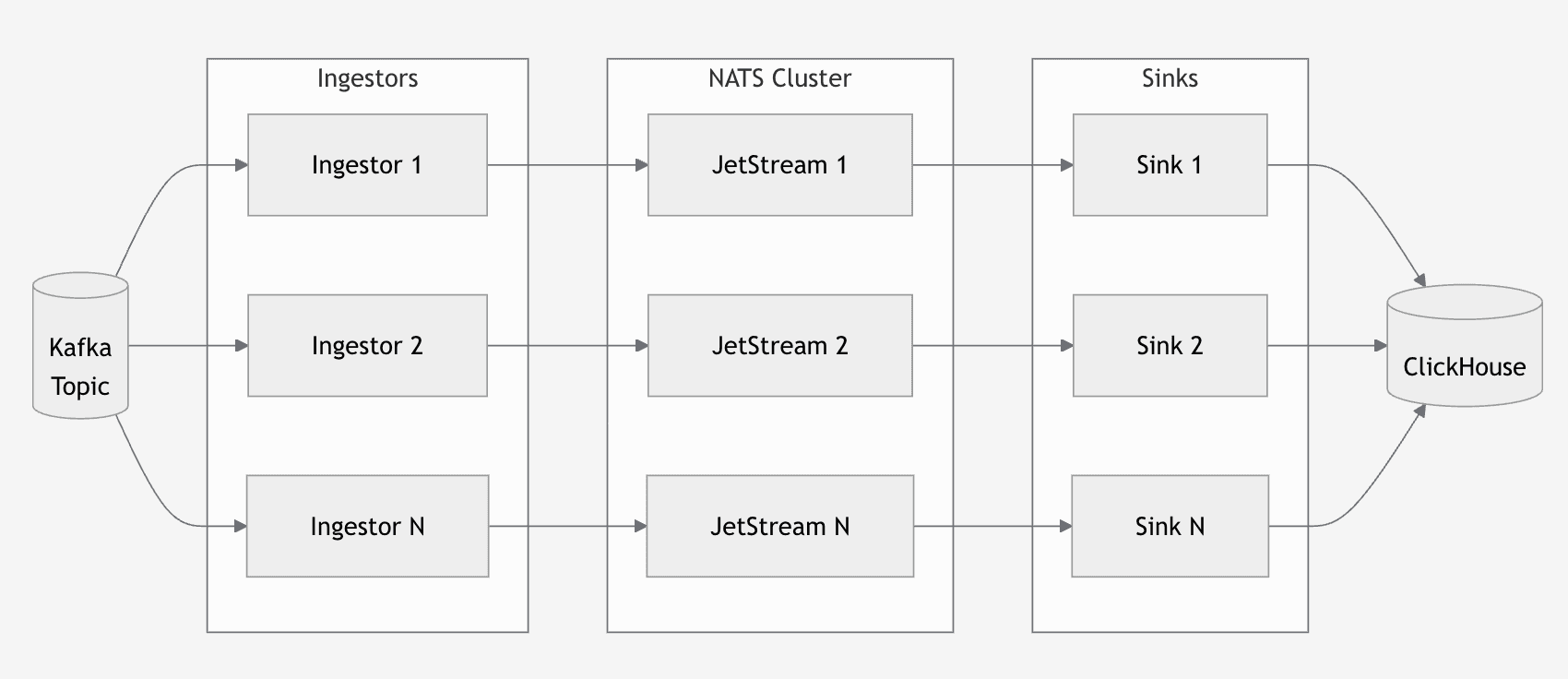
You start with a single pipeline that handles your initial load, which can be much smaller.
As your data grows, you do not split it. You do not duplicate logic. You do not redesign anything.
You simply add more resources.
The pipeline stays the same. The behavior stays the same. It just does more work.
That has a few important implications for data engineering teams:
No need to manage multiple pipelines reading from the same source
No need to duplicate or keep logic in sync
No instance-based scaling model where you stitch things together manually
No architectural changes as you grow
Scaling becomes a resource decision, not an engineering project.
Even if you introduce state or longer time windows, the system's scaling behavior remains unchanged. You still just add capacity to the same pipeline.
At the same time, everything is optimized for ClickHouse.
Data is written in such a way that keeps ingestion efficient and queries fast. Scaling your pipeline not only increases throughput; it also keeps your analytical layer performing well.
Closing
We rebuilt it so we can answer that one question with confidence:
Can GlassFlow handle my current and future ingestion loads? Yes, it can!
And you will not have to rethink your system when that load grows.
If you want to go deeper into the performance metrics, check the full GlassFlow performance breakdown.
And if you are currently hitting limits with your pipeline, I would genuinely love to hear where things break. Contact us here.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
