ljn
ClickHouse Learnings
Why companies build custom Go ingestion services for ClickHouse pipelines.
Written by
Armend Avdijaj
-

Why Companies Build Custom Go Ingestion Services for ClickHouse
ClickHouse is a well-regarded open-source analytical database management system. Its columnar storage and vectorized query processing are optimized for fast aggregations and analytical queries on large datasets, making it suitable for use cases involving logs, metrics, and user events. For complex reporting on significant data volumes, ClickHouse provides strong performance.
However, ingesting data into ClickHouse, particularly under high-volume, real-time conditions, presents specific challenges. While ClickHouse offers various data insertion methods, directly connecting real-time streams from sources like Apache Kafka can lead to difficulties. Tasks such as ensuring exactly-once processing, handling duplicate events reliably, enriching data by joining with external sources before insertion, or applying complex filtering rules during ingest often require capabilities beyond ClickHouse's native functions or standard ETL tools. These requirements frequently involve state management or external system interactions that are not the primary focus of an OLAP database.
To address these ingestion challenges, many organizations develop custom intermediary services. These services act as a pre-processing layer: they consume raw data, perform necessary transformations and enrichments, batch the results, and then insert prepared data into ClickHouse. Go (Golang) is often selected for building these services due to its performance characteristics, built-in concurrency features (goroutines), and a suitable ecosystem for networking and data handling.
This article examines the reasons behind this approach. We will explore why companies invest in custom Go services for ClickHouse ingestion, detail the functions these services typically implement, discuss the associated risks and costs, and introduce GlassFlow as a managed, Python-oriented alternative for simplifying these stream processing pipelines.
Understanding ClickHouse's Real-Time Ingestion Needs
ClickHouse's design for analytical performance influences its data ingestion patterns. The common method involves sending batches of data via HTTP or the native TCP protocol. Inserts are generally asynchronous: the client sends data, ClickHouse acknowledges receipt, and processes the insertion in the background, enabling high write throughput.
The MergeTree family of table engines, often used for core storage, is optimized for bulk writes and background data merging. While effective for read performance, this batch-oriented, asynchronous model presents challenges when handling continuous, granular real-time data streams:
Implementing Reliable Distributed Deduplication: Real-time sources may produce duplicate events (due to at-least-once delivery from Kafka, network retries, etc.). ClickHouse engines like
ReplacingMergeTreehandle duplicates eventually during background merges based on a key, but this doesn't provide immediate, ingest-time exactly-once semantics. Guaranteeing single processing across multiple ingester instances usually requires external state management (e.g., using Redis) to track recent event IDs before insertion.Performing Necessary Joins Before Data Insertion: Analytical queries often require joining event data with dimension data (e.g., campaign details). While ClickHouse supports joins, performing frequent joins at query time, especially involving large tables or requiring low-latency lookups during ingest, can be inefficient. It is often more practical to pre-join or enrich the data in the intermediary service, creating a denormalized table in ClickHouse optimized for analysis. This typically involves lookups against external databases (like PostgreSQL) or caches.
Efficiently Handling Stateful Transformations or Aggregations During Ingest: Some use cases require maintaining state across events (e.g., sessionization, windowed counts). Performing these purely in ClickHouse might necessitate complex queries over raw data. Pre-calculating these results in an external service and inserting the aggregated data can reduce ClickHouse's query load and storage.
Applying Complex Filtering or Enrichment Logic Upstream: Raw data streams often contain noise or require context not present in the event. While ClickHouse has
WHEREclauses and functions, applying complex business rules or filtering based on external factors is often better handled in a dedicated pre-processing service before data reaches the database, ensuring data quality.
These factors explain why directly connecting real-time sources to ClickHouse may be insufficient for certain applications, leading to the development of custom intermediary services.
Why Build These Custom Services in Go?
When a custom intermediary service is needed for ClickHouse ingestion, Go is frequently chosen as the implementation language for several practical reasons:
Performance and Concurrency: Processing high-volume real-time data requires efficiency. Go is a compiled language offering good performance and resource utilization. Its concurrency model, using lightweight goroutines and channels, simplifies building services that handle numerous concurrent operations (like processing Kafka messages, making parallel external calls, managing batching) effectively, aligning well with ClickHouse's preference for batched inserts.
Robust Ecosystem: The Go ecosystem provides mature libraries for common pipeline components:
Message Queues: Reliable Kafka clients like
segmentio/kafka-goorconfluentinc/confluent-kafka-goare available.Databases: Drivers exist for PostgreSQL (
jackc/pgx), Redis (redis/go-redis), and ClickHouse (ClickHouse/clickhouse-go/v2), facilitating enrichment and state management.Networking: The standard library offers strong support for HTTP interactions and TCP connections.
Fine-Grained Control: A custom Go service allows full control over the implementation. Developers can implement specific business logic for filtering, transformation, enrichment, and error handling precisely as needed, beyond the constraints of some generic tools.
Effective State Management: Tasks like deduplication require managing state. Go's primitives allow for managing moderate state within the service (e.g., using mutex-protected maps), and it integrates well with external stores like Redis for larger or more persistent state needs.
These characteristics make Go a suitable language for developing the custom services often required for complex ClickHouse ingestion pipelines.
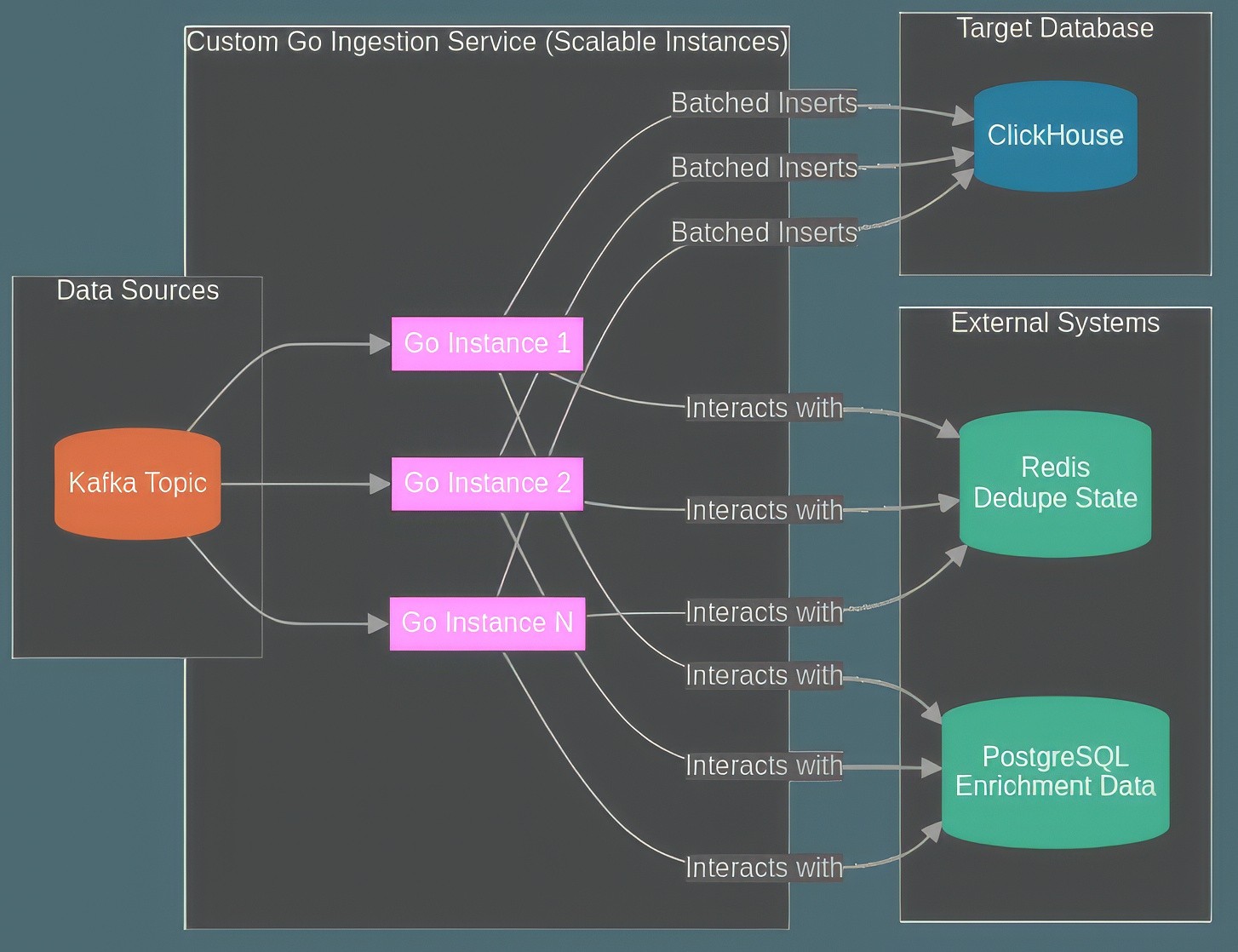
Diagram 1: High-level view showing Kafka feeding multiple Go service instances which interact with external systems (Redis, Postgres) before batching data into ClickHouse.
Core Functions: What Do These Services Typically Handle?
While the exact implementation depends on the use case, custom Go services for ClickHouse ingestion generally handle a common set of pre-processing functions. These functions directly address the challenges of direct ingestion and prepare data for efficient storage and analysis.
1. Real-Time Deduplication
The Goal: To prevent duplicate records from being stored in ClickHouse, which is crucial for data integrity, especially when input sources like Kafka provide at-least-once delivery guarantees or when network retries might occur.
Implementation: This function necessitates state management. The Go service must track event identifiers (unique IDs) it has processed within a defined recent period. A common technique uses an external key-value store like Redis for its speed and atomic operations. When an event arrives, the service attempts to set a key in Redis derived from the event ID, using a command like
SETNX(SET if Not eXists) with a specific expiration time (TTL). If the command succeeds (the key was set), the event is considered new. If it fails (the key already existed), the event is identified as a duplicate and is typically discarded.Considerations: This approach requires managing the Redis instance (capacity, latency) and choosing an appropriate TTL for the keys – long enough to catch relevant duplicates but short enough to avoid excessive memory use. Handling potential Redis connection errors is also important (should the service fail open or closed?).
The following Go snippet shows the core logic using a Redis client:
In this function, redisClient.SetNX attempts to create the key. If wasSet is false, the key already existed, indicating a duplicate.
2. Pre-computation Joins and Enrichment
The Goal: To add context to incoming stream data by joining it with related information from other systems before it is stored in ClickHouse. This avoids potentially costly joins during analysis and creates richer, more self-contained records.
Implementation: The Go service receives an event, extracts relevant keys (like ad_id or user_id), and uses these to query external systems. These could include relational databases (e.g., PostgreSQL for campaign details), caches (e.g., Redis for user profiles), or other microservices via APIs (e.g., for geo-IP lookups). Go's concurrency capabilities often allow these lookups to be performed efficiently, sometimes in parallel. The retrieved information is then merged with the original event data.
Benefit: This pre-joining results in denormalized, wider tables in ClickHouse, which generally leads to faster analytical query performance as the join complexity is handled during ingestion.
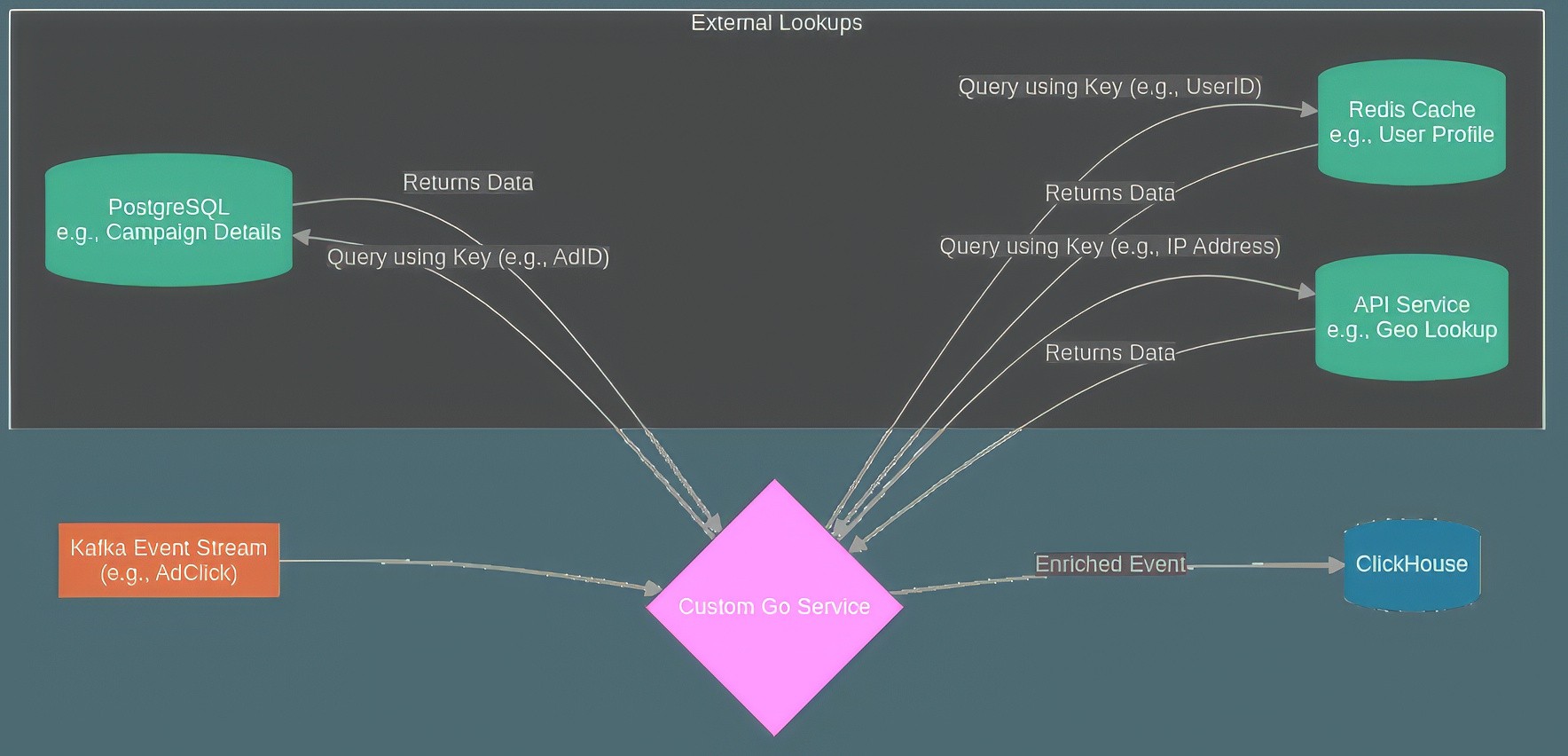
Diagram 2: The Go service acts as an orchestrator, receiving stream events and querying various external systems for enrichment data before sending the combined result to ClickHouse.
3. Stateful Aggregations
The Goal: To perform calculations that require maintaining state across multiple events, often within time windows (e.g., calculating user session metrics, hourly unique counts, category-based sums). Pre-aggregating this data reduces the volume stored in ClickHouse and simplifies subsequent analytical queries.
Implementation: The service needs to maintain state, either in memory (e.g., using sync.Map or standard maps protected by sync.Mutex) or an external store if the state is large or needs higher durability. As events arrive, the service updates the relevant state (e.g., increments counters, updates window sums). A separate mechanism, often a timed background goroutine, periodically reads the current aggregated state, formats it, flushes it to a designated summary table in ClickHouse, and then clears or checkpoints the local state.
Considerations: Correctly managing state, particularly in a distributed setup with multiple service instances, is challenging. Memory consumption requires monitoring, and a reliable mechanism for flushing and state eviction is essential.
This Go snippet illustrates the concept of updating an in-memory aggregation state:
This function shows the core state update logic. A complete implementation requires additional components for periodically flushing this state to ClickHouse.
4. Filtering and Transformation
The Goal: To clean the incoming data stream by discarding irrelevant or invalid events and to normalize or reshape the remaining data into the specific structure required by the target ClickHouse table.
Implementation: This is often implemented using conditional logic within the Go service.
Filtering: Events might be dropped based on specific field values (e.g., internal test flags), numerical ranges, null values, or string patterns (e.g., filtering bot user agents).
Transformation: Common tasks include converting data types (e.g., string representations of numbers to actual integers/floats, Unix timestamps to time.Time), standardizing formats (e.g., ensuring all timestamps are UTC), renaming fields to match the ClickHouse schema, adding metadata generated by the service (like a processed_at timestamp), or parsing complex/nested data structures (like JSON within a field).
Benefit: This step ensures that the data landing in ClickHouse is valid, relevant, and adheres to the expected schema, improving overall data quality and making analysis easier. Our full Go example includes IP address filtering and timestamp conversion as examples.
Example Scenario: Real-Time Ad Click Processing
To see how these concepts work together, let's consider a typical scenario involving real-time processing of online ad clicks. Events representing user clicks on advertisements are generated and sent to an Apache Kafka topic. The objective is to ingest this clickstream data into ClickHouse to enable near real-time analysis of campaign effectiveness, user engagement, and potentially fraudulent activity.
1. Use Case Definition
Input Data: A stream of JSON messages arrives in the Kafka topic
ad_clicks. Each message represents a single click and contains fields such as:click_id: A unique identifier for the click event.user_id: Identifier for the user who clicked.ad_id: Identifier for the specific ad that was clicked.timestamp_ms: The time of the click as a Unix timestamp in milliseconds.ip_address: The IP address from which the click originated.
Processing Requirements:
Deduplication: Use the
click_idto ensure each click event is processed exactly once, using Redis for state tracking.Enrichment: Enhance the click data by adding
campaign_nameandcampaign_budget. This requires looking up thead_idin acampaignstable stored in PostgreSQL.Filtering: Remove any clicks originating from specified internal or known bot IP address ranges (e.g.,
192.168.1.x).Transformation: Convert the
timestamp_msfield into a ClickHouse-compatibleDateTimeformat (UTC). Add aprocessed_attimestamp indicating when the service handled the event.
Output: Store the resulting enriched and validated click events into the
analytics.ad_clicks_enrichedtable within ClickHouse.Goal: Facilitate timely analysis in ClickHouse through dashboards and queries focusing on clicks per campaign, user behaviour, budget pacing, etc.
2. Architecture Overview
A custom Go service provides a suitable architecture for meeting these requirements. The data flow typically involves these components:
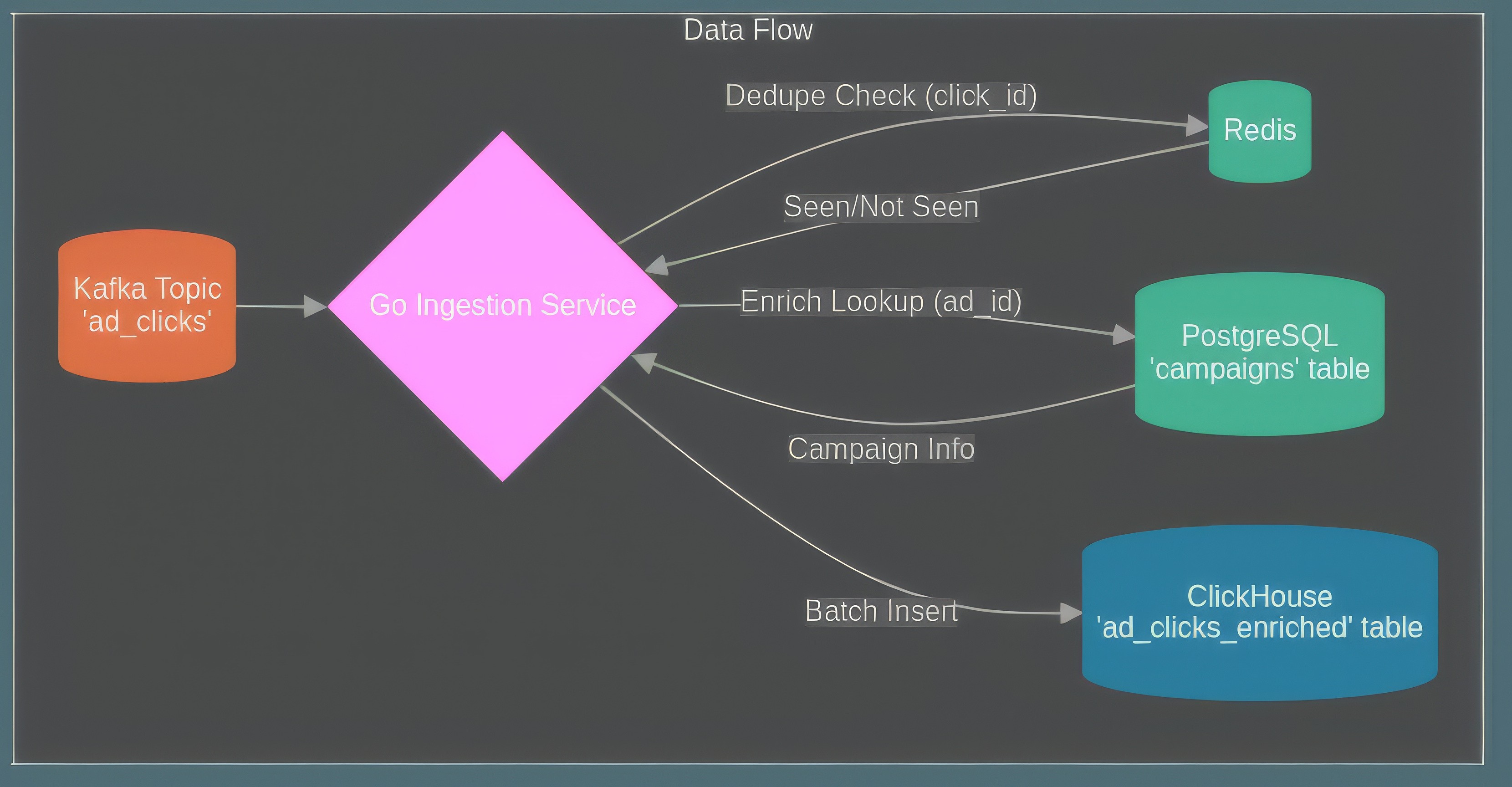
Diagram 3: Architecture showing Kafka feeding Go service instances, which use Redis for deduplication and PostgreSQL for enrichment before inserting batches into Clickhouse.
Kafka (
ad_clickstopic): The entry point, buffering incoming raw click events.Go Ingestion Service: Typically deployed as multiple instances (e.g., containers or pods) for scalability and fault tolerance. Each instance consumes messages from assigned Kafka partitions and executes the processing steps independently.
Redis: Provides a centralized, low-latency store accessible by all Go instances to track click_ids for deduplication. Using SETNX with a TTL ensures consistency.
PostgreSQL: Stores the campaigns dimension table. The Go service queries this table using the ad_id to fetch enrichment data.
ClickHouse: The target analytical database receiving batches of processed
EnrichedClickEventdata into thead_clicks_enrichedtable.
3. Go Service Role
The custom Go service acts as the central orchestrator for each incoming message, performing the required steps in sequence:
Consume & Unmarshal: Read a message from Kafka and parse its JSON payload into the RawClickEvent struct.
Deduplicate: Call the isDuplicate function, which checks Redis using the event's click_id. If it's a duplicate, log it (optionally) and skip further processing for this message. If new, set the key in Redis.
Filter: Apply the filterEvent logic (e.g., checking ip_address). If the event matches filter criteria, skip further processing.
Enrich: Call the enrichEvent function, querying PostgreSQL with the ad_id to retrieve campaign_name and campaign_budget. Handle cases where enrichment data might be missing (e.g., log a warning, assign default values, or potentially skip the event).
Transform: Convert the timestamp_ms to a standard Go time.Time (UTC). Create the final EnrichedClickEvent struct, including the fetched campaign details and adding a processed_at timestamp.
Batch: Append the successfully processed EnrichedClickEvent to an in-memory buffer (batch). This buffer needs thread-safe access (e.g., using a sync.Mutex) if multiple goroutines are processing events concurrently within a single service instance.
Insert: Periodically (based on a timer, e.g., clickhouseFlushInterval) or when the batch buffer reaches a predefined size (e.g., clickhouseBatchSize), send the entire buffer contents to ClickHouse using an efficient bulk insert mechanism provided by the ClickHouse driver (like PrepareBatch). Implement appropriate error handling for the batch insert (retries, logging, potential dead-letter queue).
Commit Offset: Once an event has been successfully processed (either added to the batch buffer or intentionally skipped due to deduplication/filtering/enrichment failure), commit its offset back to Kafka. This signals that the message has been handled and prevents reprocessing in case of a service restart. Note: Committing after adding to the batch assumes the batch insert logic handles failures robustly.
The core processing logic within the service, handling steps 2 through 5 for a single event, is encapsulated in a function like processEvent:
This function demonstrates how the individual core functions (deduplication, filtering, enrichment, transformation) are chained together to process one event before it gets added to the outgoing batch for ClickHouse.
The Downsides: Risks and Costs of the Custom Approach
While building a custom Go service offers tailored control and potentially high performance, it's crucial to acknowledge the significant costs and complexities involved. Opting for the DIY route means taking on responsibilities that extend far beyond writing the core processing logic.
1. Development Effort and Cost
Creating a production-ready ingestion service is a substantial software project. It requires skilled engineers proficient in Go, distributed systems patterns, and the specifics of interacting with Kafka, ClickHouse, and any other integrated systems (like Redis or PostgreSQL). This involves not just implementing the core logic but also handling configuration, error management, connections, and testing.
The initial development phase can consume significant time and budget.
2. Maintenance Overhead
Once deployed, a custom service requires continuous care and feeding. It's not a "set it and forget it" component. Maintenance activities become a regular part of the engineering cycle.
Below is a non-exhaustive table including some common Maintenance Tasks for Custom Ingestion Services:
Maintenance Area | Examples | Frequency |
|---|---|---|
Bug Fixing | Addressing logic errors, race conditions, resource leaks | As needed |
Dependency Updates | Updating Go modules, Kafka clients, DB drivers, OS patches | Regularly |
Adaptation | Handling source format changes, ClickHouse schema drift, API versions | Occasionally |
Enhancements | Adding new filtering rules, enrichment sources, optimizations | Periodically |
3. Operational Complexity
Running the service reliably in production often presents the biggest hurdle. You inherit responsibility for the entire operational stack surrounding your Go code.
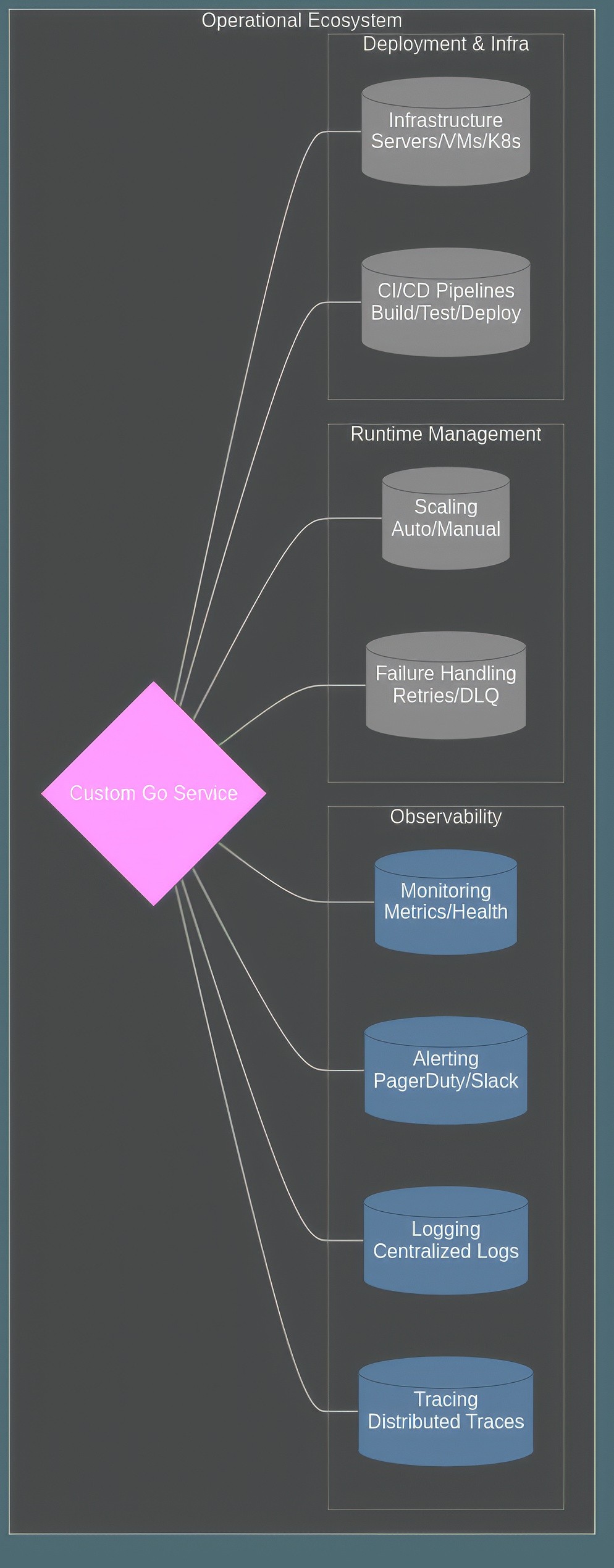
Diagram 4: Operational Responsibilities Surrounding a Custom Service
This operational scope involves:
Infrastructure: Provisioning and managing the underlying servers or container orchestration (like Kubernetes).
Deployment: Implementing safe, automated deployment processes (CI/CD).
Observability: Setting up comprehensive monitoring, logging, and tracing to understand behavior and diagnose issues quickly. Effective alerting is critical for incident response.
Scaling: Designing for horizontal scalability and implementing mechanisms (like Kubernetes HPA) to handle varying loads.
Resilience: Building in robust error handling, retries, and potentially dead-letter queues to cope with transient failures in dependent systems (networks, databases, Kafka).
Each of these areas requires specific expertise and tooling, adding significantly to the total cost of ownership.
4. State Management Challenges: The Achilles' Heel
If your service needs to track state (for deduplication or aggregations), complexity increases substantially.
Consistency: How do you ensure state is correct when multiple instances might try to update it concurrently (e.g., using Redis)? This requires careful use of atomic operations and strategies to handle race conditions.
Durability & Recovery: In-memory state is fast but lost on restart. Persisting state externally (like Redis) makes it durable but introduces another system dependency to manage, monitor, and make resilient. How will state be recovered or reconciled after a failure?
Scalability: The external state store itself needs to be scaled and maintained as data volumes grow.
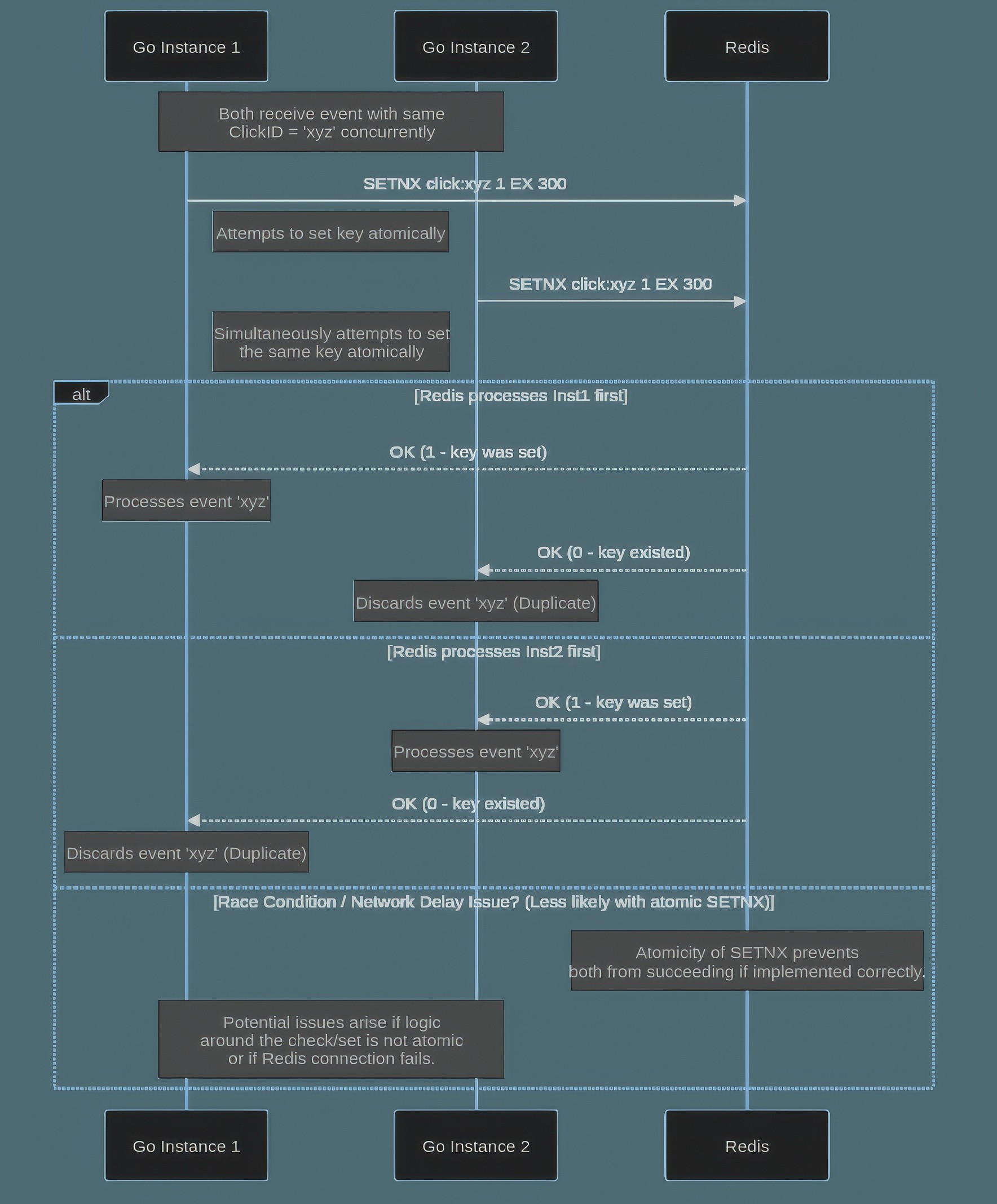
Diagram 5: A simple diagram showing two Go Service instances attempting simultaneous SETNX operations on the same key in Redis, illustrating the need for atomicity.
Getting state management right, especially in a distributed system, is notoriously difficult and a common source of bugs and operational pain.
5. Performance Tuning and Bottlenecks
While Go offers excellent performance potential, it's not automatic. Your custom service can still become a bottleneck. Achieving and maintaining high throughput requires careful performance tuning. This might involve:
Optimizing Go code (e.g., reducing allocations, improving concurrency patterns).
Tuning Kafka consumer parameters.
Optimizing batch sizes and insertion methods specifically for ClickHouse.
Improving the performance of external database queries used for enrichment.
Conducting load tests to identify limits and regressions.
This tuning process requires specialized skills and tools.
6. Standardization Issues: The Wild Wild West
In organizations where multiple teams might build similar services, the custom approach can lead to significant divergence. Without strong architectural guidance and shared libraries, each implementation might use different patterns, libraries, monitoring approaches, and deployment methods. This lack of standardization makes services harder to understand across teams, increases maintenance complexity, and hinders the development of common operational tooling and expertise.
In summary, the custom Go path, while powerful, brings a heavy backpack of development, maintenance, and operational responsibilities. These ongoing costs and complexities need careful consideration before embarking on this route.
An Alternative Path: Simplifying Pipelines with GlassFlow (Python)
The complexities and long-term costs associated with building and maintaining custom ingestion services have led to the rise of managed stream processing platforms. These platforms aim to abstract away infrastructure management and provide higher-level tools for building data pipelines. GlassFlow is one such platform, offering a Python-native approach designed to simplify the development and operation of real-time pipelines, including those targeting ClickHouse.
1. Introducing GlassFlow
GlassFlow presents itself as a solution for "Deduplicated Kafka Streams for ClickHouse," aiming to provide "Clean Data. No maintenance. Less load for ClickHouse." It focuses on simplifying the process compared to building custom solutions.
2. How GlassFlow Addresses Custom Build Pain Points
GlassFlow directly targets several of the challenges inherent in the custom service approach:
Simplified Setup & Maintenance: Offers features like "Deduplication with one click" and "Joins, simplified". It provides "Managed Kafka and ClickHouse Connectors," removing the need to build/maintain them. The comparison graphic highlights replacing tasks like connector management, resource optimization, state management, debugging, schema handling, and error handling with a simpler "Click, Click, Done" workflow, promising setup "in no time".
Managed Operations: As a managed platform with a "serverless engine," it handles operational tasks. "Auto Scaling of Workers" adjusts resources based on Kafka partitions, aiming for efficient execution without manual intervention.
Built-in State Management: Provides "Stateful Processing" using a "lightweight state store" for low-latency, in-memory deduplication and joins. It states GlassFlow "handles execution and state management automatically" for joins and includes "24 hours deduplication checks" for ongoing data accuracy.
Data Accuracy & ClickHouse Efficiency: Aims for "Accurate Data Without Effort" by handling duplicates and using stateful storage (which helps with late events). By processing before ClickHouse ("removing duplicates and executing joins before ingesting"), it promises "Less load for ClickHouse," reducing the need for operations like
FINALorJOINs within ClickHouse, lowering storage costs, and improving query performance. ClickHouse receives clean, optimized data.Clear Pipeline Structure: The "Simple Pipeline" diagram shows a clear flow: Kafka -> GlassFlow (handling Deduplication, Join, State Storage) -> ClickHouse.
Final Thoughts: Choosing Your Path for ClickHouse Ingestion
ClickHouse provides exceptional performance for analytical queries, but getting real-time data into it effectively often requires careful pre-processing. Direct ingestion can struggle with complexities like deduplication, real-time enrichment, stateful calculations, and advanced filtering. This frequently necessitates an intermediary layer between your data sources and ClickHouse.
We've explored two primary strategies for building this layer:
Custom Ingestion Services (often in Go): This approach offers maximum control and the potential for highly tuned performance. You build exactly what you need, implementing precise business logic and leveraging Go's concurrency for high throughput. However, this path demands significant upfront development effort and, crucially, entails substantial ongoing costs for maintenance, operations (scaling, monitoring, alerting), and managing infrastructure complexities like state persistence.
Managed Stream Processing Platforms (like GlassFlow with Python): These platforms aim to simplify the process by handling infrastructure, scaling, and operational concerns. Developers focus on writing transformation logic, often in familiar languages like Python, using pre-built connectors. This typically leads to faster development cycles and reduced operational burden. The trade-off might be less fine-grained control compared to a custom build and reliance on the platform's specific features and abstractions.
So, which path is right for you? The decision resides on evaluating your specific circumstances:
Factor | Consideration |
|---|---|
Team Skills & Ecosystem | Is your team deeply experienced with Go and distributed systems operations, or is Python and its data ecosystem a better fit? |
Time-to-Market | How quickly do you need the pipeline running? Managed platforms generally offer a faster route to deployment. |
Operational Resources | Do you have the team capacity and budget to operate and maintain a custom, mission-critical service 24/7? Or is offloading operations a priority? |
Complexity & Control | Are your processing requirements highly specialized, demanding custom low-level implementation, or do they align with common patterns? |
Performance Needs | While managed platforms strive for efficiency, extreme scale or ultra-low latency might still necessitate a custom-tuned service. |
By weighing these factors you can make an informed decision, and hopefully save you and your team a lot of headaches in the process.
Try GlassFlow Open Source on GitHub!
References
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
