ljn
Tutorials
Joining Kafka Streams Before ClickHouse with GlassFlow
Written by
Vimalraj Selvam
-

📌 Part 3: Streaming Enrichment with Glassflow's Join Feature
This article was created by Vimalraj Selvam and originally posted on his blog.
In modern logging pipelines, enriching logs with external data is essential for making them more meaningful and actionable.
We have already explored the following features of Glassflow's ClickHouse ETL in our previous posts:
In this post, with Glassflow's temporal join capability, we will explore on how to merge streaming logs with reference data in real-time - prior to ingestion into ClickHouse which helps to safeguard the performance of your ClickHouse cluster from unneccessary joins.
🧱 Why Use Join in Log Pipelines?
Log enrichment automates log enhancement with contextual data - think routing info, user metadata, or service names. Traditionally, this is handled post-ingestion via expensive analytical JOINs or offline batch enrichment. Glassflow enables this upstream, giving you enriched log entries in ClickHouse without complex post-processing.
⚙️ How Glassflow Stream Join Work
Glassflow supports real-time joining of two Kafka streams:
Dual-stream input: Choose a primary log topic (left) and secondary lookup topic (right).
Join Key: Define one or more fields to match on (e.g.,
user_idorcounter).Time window: Specify how far back to buffer lookup events (up to 7 days).
Result: Glassflow correlates log and lookup events within the window, emitting enriched records downstream.
This logic ensures that each log is enriched with matching metadata - before it lands in ClickHouse.
🛠️ Example: Enriching Logs with a Lookup Stream
🔧 Setup Two Kafka Topics
logs: Contains
timestamp,counter,msg, anduser_id. We will use our existing Fluent Bit to produce the logs by making a small change in our Lua script.users: Contains
user_id,username, andregion. We'll leverage kcat CLI utility to produce messages to this topic.
🔧 ClickHouse Schema
For the complete setup, download the docker-compose setup from here
🔧 Produce users topic
Using kcat utility, let's produce some dummy messages:
Press Command + D or ctrl + D to stop producer.
🔧 Setup Flow
With the downloaded docker compose, let's start our end-to-end flow by running docker compose up -d.
The small change that was done in our Lua script is to produce user_id as follows:
🔧 Configure Glassflow
Once the docker compose is up sucessfully, open http://localhost:8080 in your browser and select
Joinbutton from the Welcome screen:

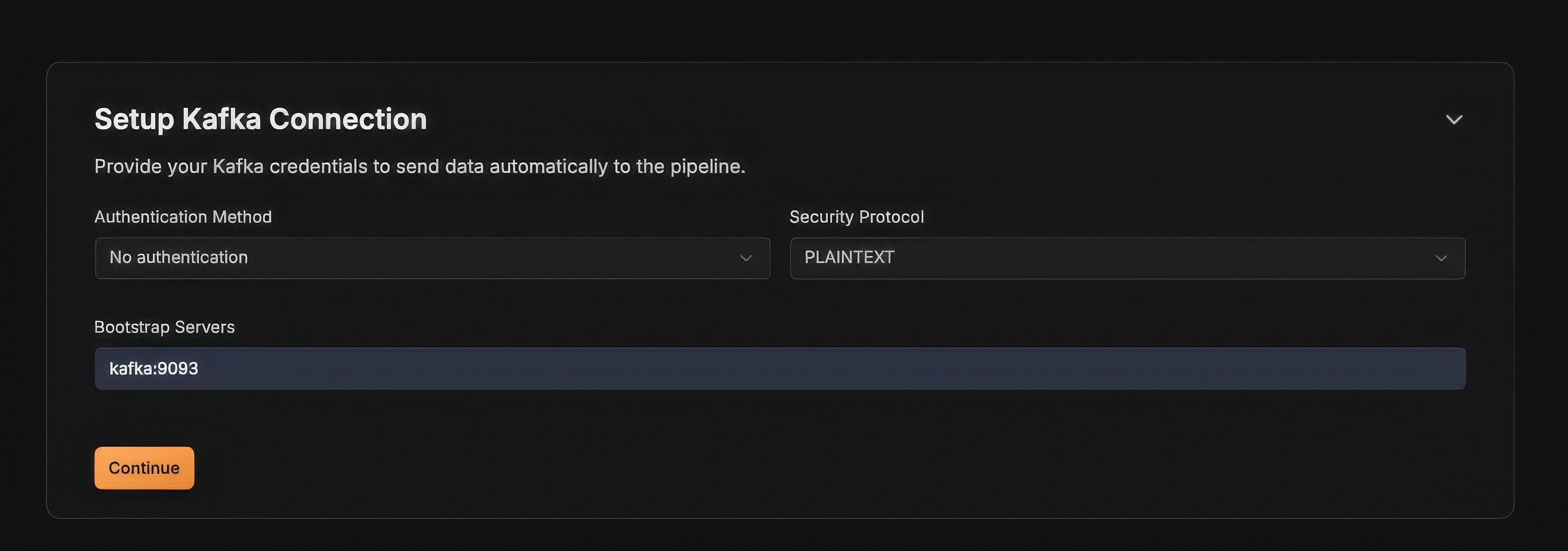
Setup Kafka connection details as follows:
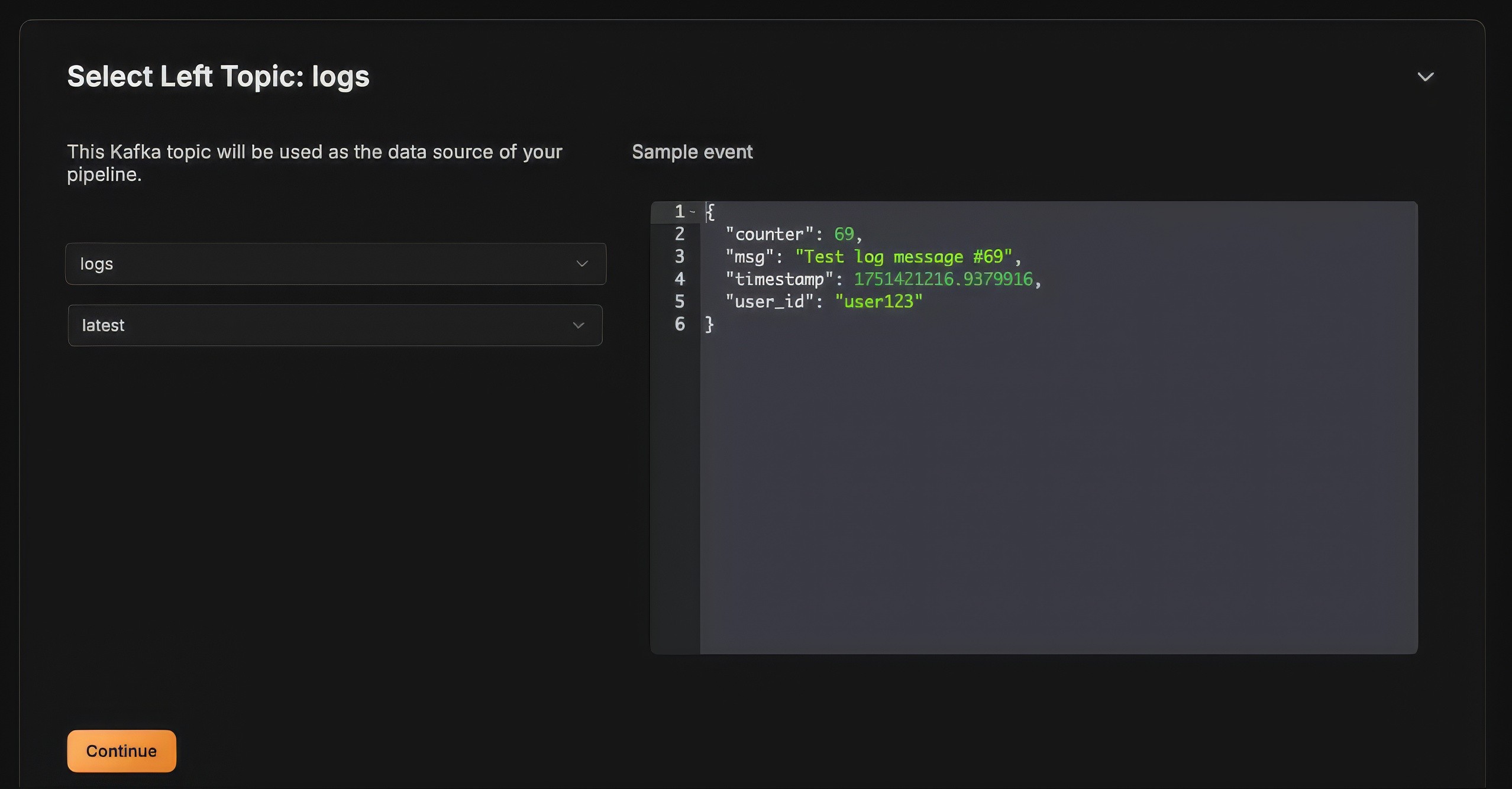
Select the Left Kafka topic where the logs are produced:
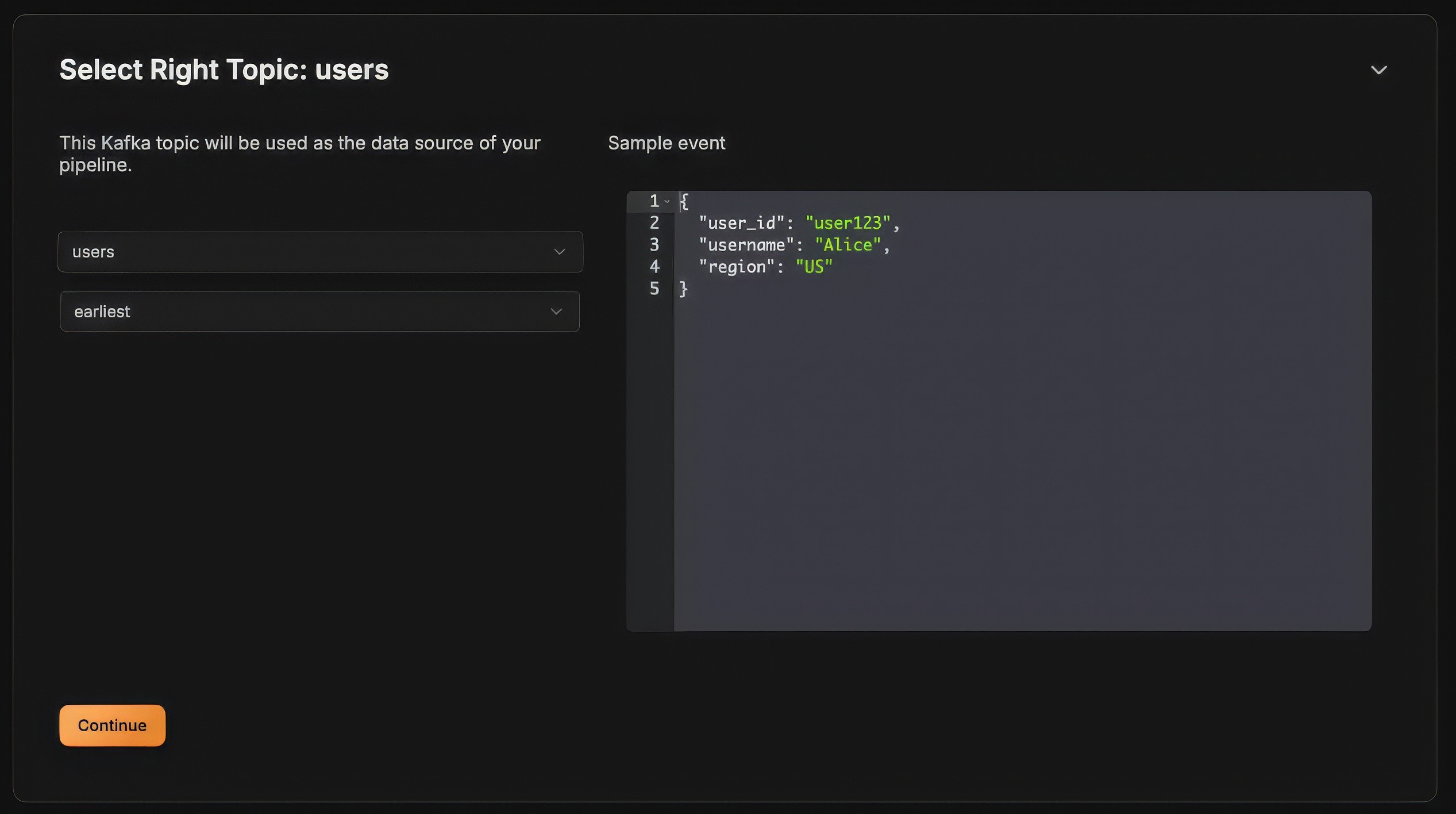
Select the Right Kafka topic where the user details are produced:
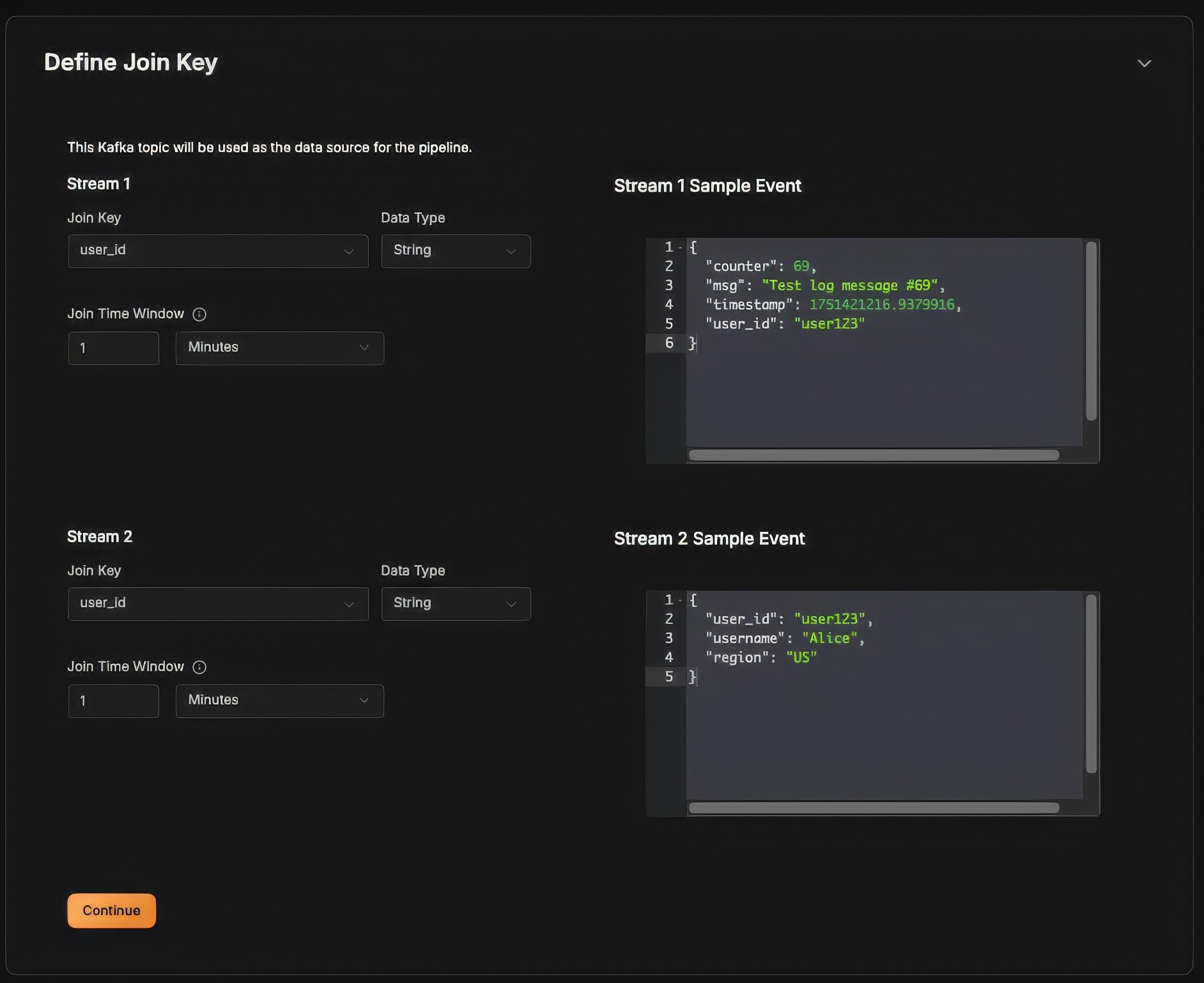
Now, select the join key, in our case it is
user_idand the join time window, let's set it as 1 minute:
Now setup a ClickHouse connection details. Please remember to create a table schema before doing this.
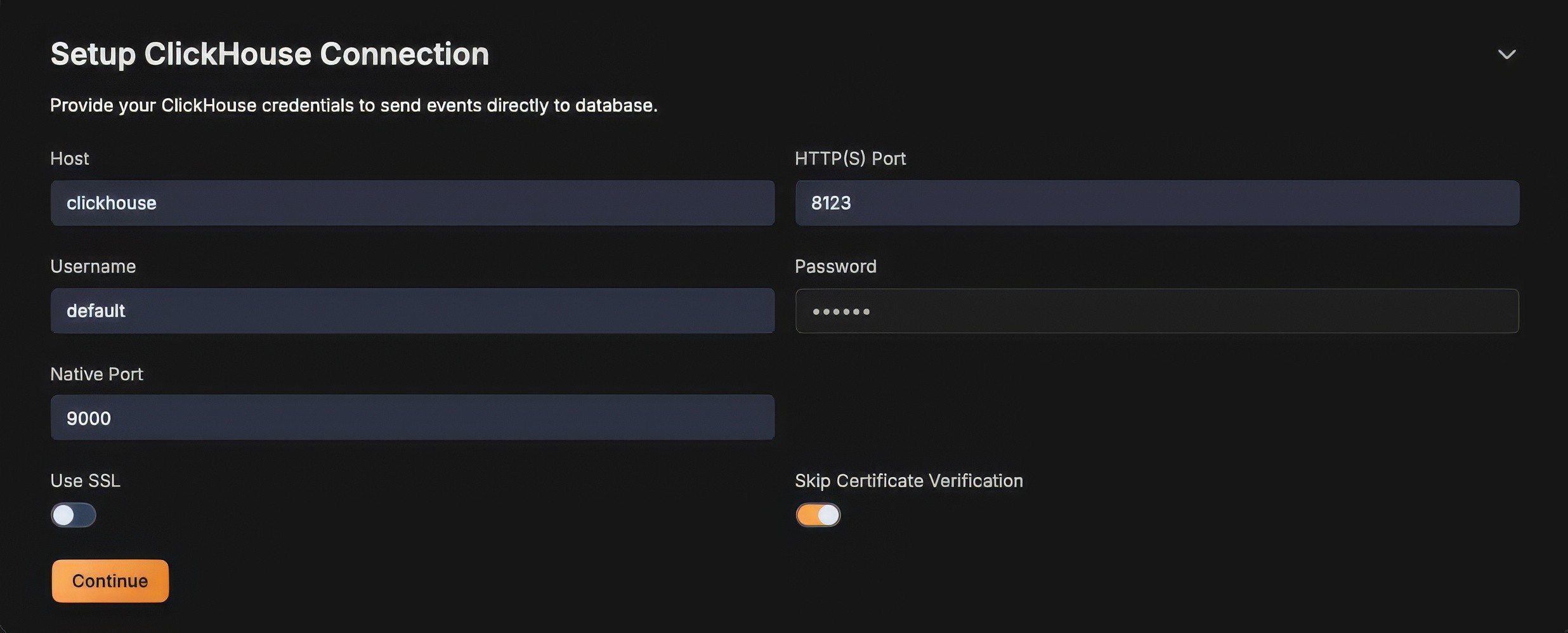
Select the target database and table to where the logs must be ingested at this stage.
Map the left / right topic keys to the appropriate column names in ClickHouse.
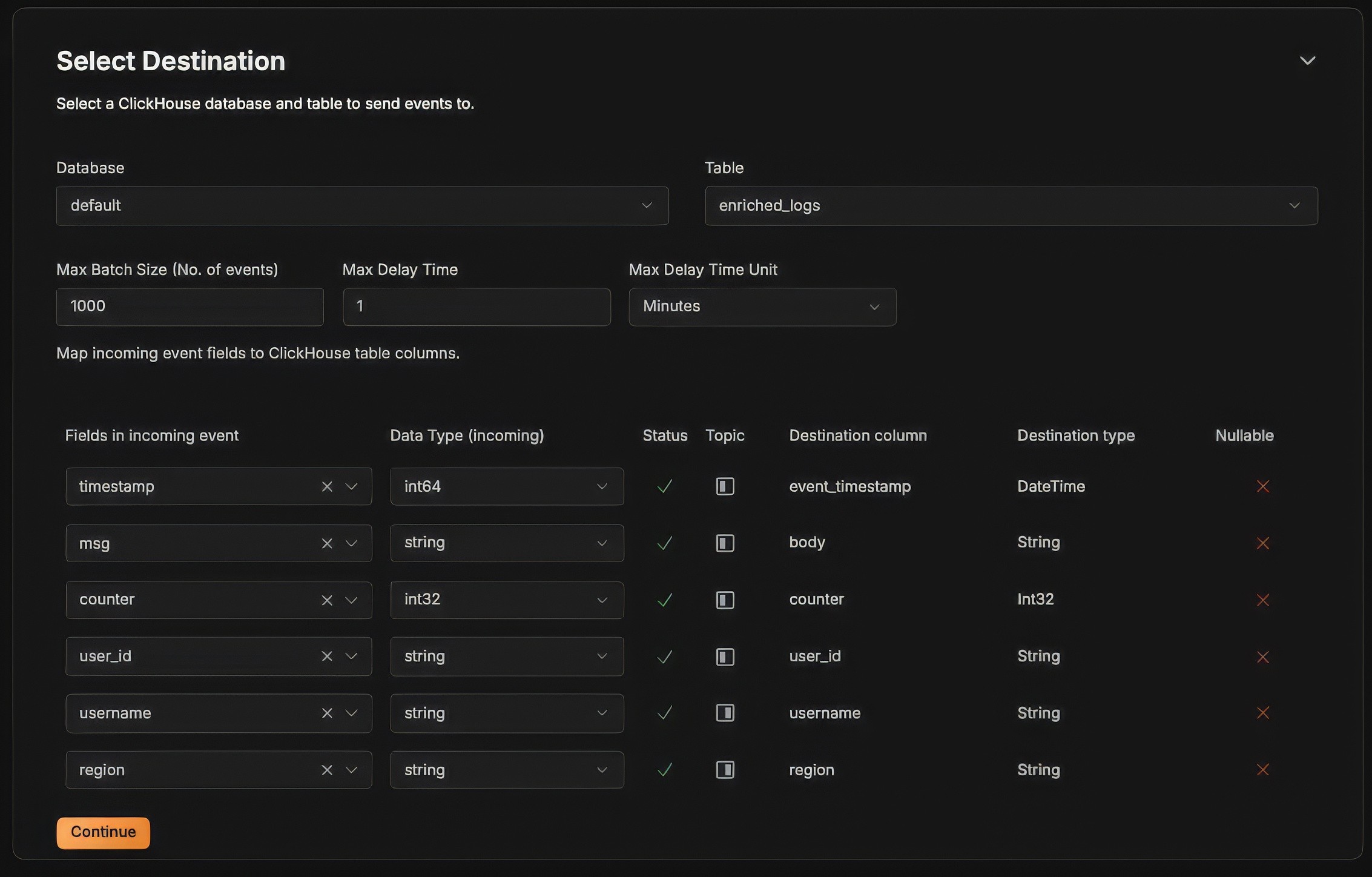
Finally, your pipeline is active and wait for at least 1 minute or 100 events to be batched as per our configuration to insert into ClickHouse.

After few inserts, now you can query from Clickhouse and view the enriched logs as follows:
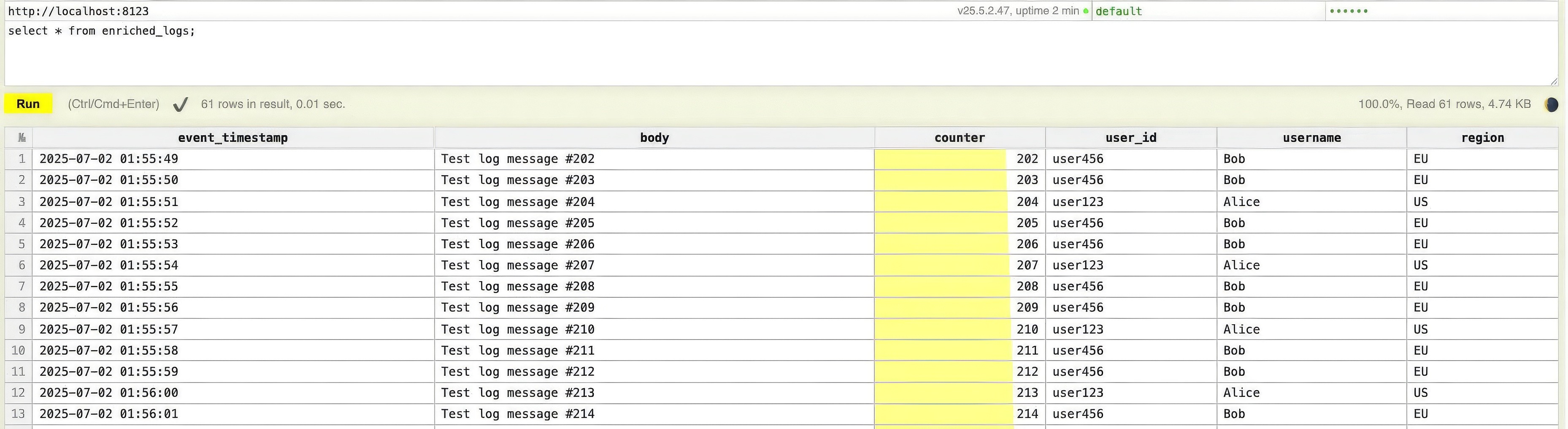
🔍 Under the Hood
Glassflow maintains buffered state of lookup topics for the join window. On receiving a log, it checks for matching lookup events in the buffer. If found, it enriches the log record before batching to ClickHouse. Late-arriving lookups within the window still get applied.
🎯 When to Use Stream Joins
Real-time user or device enrichment in logs.
Dynamic log categorization based on external service metadata.
Real-time correlation of service logs with business/user context.
Benefits include:
Reduced ClickHouse JOINs and improved query performance.
Unified enrichment logic at ingestion time.
📌 Final Thoughts
Glassflow's streaming JOIN feature bridges the gap between raw logs and enriched analytics. By joining streams upstream, you reduce complexity, improve performance, and enable real-time observability with minimal overhead.
Adding Glassflow to your data pipeline stack is definitely a breeze and saves lots of time on reinventing consumer and helps to focus on Clickhouse's user query performance.
How are you managing your Observability pipeline today? Share your experience with me on the comments section and let me know your thoughts / feedback about my articles.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
