ljn
ClickHouse Learnings
From data lakes to ClickHouse: mastering real-time data transformation.
Written by
Armend Avdijaj
-

In today's data-driven landscape, the ability to simply store vast amounts of information is no longer sufficient. The competitive edge belongs to organizations that can derive immediate, actionable insights from their data. This need for real-time analytics powers a new generation of applications, from instantaneous fraud detection and dynamic user personalization to proactive supply chain optimization and live operational dashboards. The core challenge, however, is achieving this at a massive scale, often involving petabytes of data arriving from a diverse array of sources, including structured databases, unstructured logs, IoT device streams, and social media feeds.
To address this challenge, we need a new architectural paradigm. A paradigm that combines scalability, reliability, and performance. This article explores a trio of technologies designed for this purpose:
The Data Lake (e.g., on Amazon S3): A highly scalable and cost-effective foundation for storing all of an organization's raw data in its native format.
Apache Iceberg: An open table format that imposes structure, reliability, and database-like features onto the data lake, effectively evolving it into a modern "lakehouse".
ClickHouse: A blazingly fast, column-oriented analytical database engineered to execute complex queries in sub-second time, making real-time insights a practical reality.
While the technologies promises performance and flexibility, its successful implementation depends on solving a critical challenge in the middle layer: the transformation of raw, often messy, data into clean, structured, and query-ready iceberg tables. This article dissects this data transformation challenge, exploring the trade-offs between batch and streaming approaches and comparing the leading solutions that make this modern architecture possible.
Building a Reliable Data Lake with Apache Iceberg
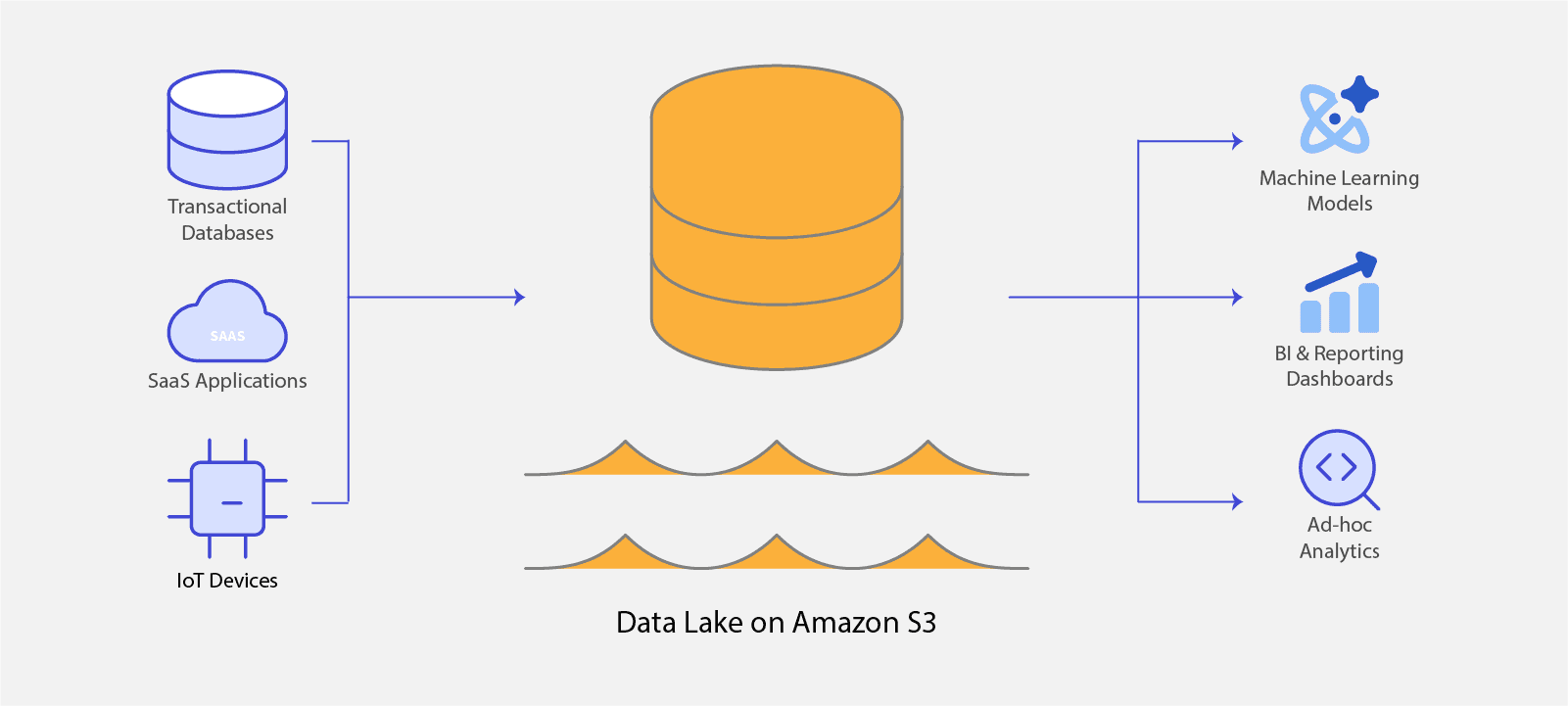
Why Companies Rely on Data Lakes
The data lake has become a central component of modern data strategy, offering distinct advantages over traditional data warehousing for initial data storage.
Cost-Effective and Scalable Storage: Data lakes are typically built on commodity object storage services like Amazon S3, Azure Data Lake Storage (ADLS), or Google Cloud Storage (GCS). This infrastructure is significantly less expensive and scales more seamlessly than the specialized storage required by traditional data warehouses. This economic model encourages organizations to adopt a "store everything" philosophy, capturing valuable data from logs, IoT devices, and line-of-business applications without being constrained by the high costs of structured storage.
Flexibility with Schema-on-Read: A defining characteristic of the data lake is its "schema-on-read" approach. This contrasts sharply with the "schema-on-write" model of a data warehouse, where data must be cleaned, structured, and forced into a predefined schema before it can be loaded. In a data lake, data is ingested and stored in its raw, native format. Structure is applied only at the moment the data is queried. This provides enormous flexibility, allowing data scientists and analysts to explore the full, unaltered dataset for novel or unforeseen use cases without being limited by a pre-existing schema.
Centralization and Collaboration: By serving as a single, centralized repository for all of an organization's data, a data lake breaks down the data silos that often form between different departments or applications. This unified source of truth fosters collaboration, enabling diverse teams—from data science and machine learning to business intelligence and research and development—to work with the same consistent data.
Data Lake
How Apache Iceberg Brings Order and Reliability
The flexibility of a data lake can also be its liability. Without robust management and governance, a data lake can devolve into a “data swamp,” a disorganized and untrustworthy repository where finding reliable data is nearly impossible. Simply querying a vast collection of individual files is inefficient, slow, and prone to error.
Apache Iceberg addresses this problem directly. It is not a database or a query engine but an open-source table format with an intelligent metadata layer that sits on top of data files in object storage. It provides a formal definition of a "table" within the data lake, bringing database-like reliability and performance to a low-cost storage environment.
ACID Transactions: Iceberg introduces full ACID (Atomicity, Consistency, Isolation, Durability) compliance to data lake operations. Every change to an Iceberg table, whether inserting new data or updating existing records, is an atomic transaction. The operation either completes successfully in its entirety or fails completely, leaving the data in its previous consistent state. This prevents the data corruption and inconsistency that can arise from partially failed write jobs, a common problem in traditional data lakes.
Schema Evolution: In agile environments, data requirements change constantly. Iceberg is designed with this reality in mind, supporting full schema evolution. Users can add, drop, rename, or reorder columns without needing to rewrite the entire dataset. Iceberg tracks these changes via unique column IDs in its metadata, ensuring that even old data remains queryable with the correct schema, thus avoiding the "zombie data" problem where old data reappears after a schema change.
Time Travel and Rollbacks: Every operation that modifies an Iceberg table creates a new, immutable "snapshot" of the table's metadata. Iceberg retains a history of these snapshots, enabling a powerful feature called "time travel". This allows users to query the table exactly as it existed at a specific point in time or as of a particular snapshot ID. This capability is invaluable for auditing data changes, debugging pipeline errors, and ensuring the reproducibility of machine learning models. Furthermore, it allows for instantaneous rollbacks, enabling operators to immediately revert the table to a previous known-good state to correct errors.
Hidden Partitioning and Performance: Traditional data lake table formats like Apache Hive expose their partitioning scheme to the user. To write an efficient query, the user must know how the table is partitioned (e.g., by date) and include explicit filters on the partition columns. Iceberg introduces "hidden partitioning," where the physical layout of the data is abstracted from the user. Iceberg's rich metadata contains detailed statistics about the data files, including value ranges for columns. Query engines can use this metadata to automatically and efficiently prune partitions and even individual files that do not contain relevant data for a given query, drastically reducing the amount of data scanned and accelerating performance without requiring user expertise.
Traditional data warehouses often lock data into proprietary storage formats, making it difficult and expensive to switch vendors or use alternative tools. Iceberg, as an open and vendor-agnostic format, breaks this lock-in. It decouples the data storage layer (the Iceberg tables on S3) from the compute layer (the query engines). This allows an organization to use the best engine for each specific task—for instance, using Apache Spark for large-scale batch transformations, Apache Flink for real-time streaming ingestion, and ClickHouse for interactive user-facing analytics—all operating on the exact same, single copy of the data. This architectural freedom prevents vendor dependency, reduces data duplication, and future-proofs the entire data platform.
ClickHouse as a Real-Time Analytical Powerhouse
While Iceberg provides a reliable and performant foundation for data storage, delivering real-time insights requires a query engine built for speed at scale. ClickHouse is an open-source Online Analytical Processing (OLAP) database management system designed specifically for this purpose. Its architecture is meticulously optimized for low-latency analytical queries on massive datasets.
Architectural Advantages of ClickHouse
Columnar Storage: Unlike traditional row-oriented databases that store all values for a given row together, ClickHouse is a true columnar database. It stores all the values for a single column together on disk. Analytical queries typically only need to access a few columns from a table with potentially hundreds of columns (e.g.,
SUM(revenue) FROM sales WHERE region = 'West'). With columnar storage, the query engine only reads the data for therevenueandregioncolumns, dramatically reducing disk I/O and memory usage compared to reading entire rows. This is a primary source of its performance advantage.Vectorized Query Execution: ClickHouse processes data not one value at a time, but in "vectors" or batches of column values. This approach minimizes the overhead of function calls and makes highly efficient use of modern CPU caches and SIMD (Single Instruction, Multiple Data) instructions, allowing it to process billions of rows per second on a single server.
MergeTree Engine Family: The core of ClickHouse's storage and retrieval performance is its MergeTree family of table engines. The MergeTree engine is optimized for high-throughput writes, which are performed in batches. Data is sorted by a primary key, and a sparse primary index allows ClickHouse to quickly identify and skip large blocks of data that are not relevant to a query, avoiding a full table scan.
Data Compression: Because similar data values are stored together in columns, they can be compressed far more effectively than row-oriented data. ClickHouse leverages advanced compression algorithms like LZ4 and ZSTD to significantly reduce storage footprint, which in turn reduces the amount of data that needs to be read from disk, further boosting query speed.
Performance Benchmark
ClickHouse's design translates into world-class performance. Publicly available benchmarks, such as the independently run ClickBench, consistently demonstrate that ClickHouse can execute analytical queries significantly faster than many other leading data warehouses and analytical databases, often by an order of magnitude or more on large datasets.
The architectural design choices that give ClickHouse its incredible speed also define its ideal role within a broader data platform. ClickHouse has limited support for full ACID transactions and is not optimized for the frequent, low-latency, single-row updates or deletes common in transactional (OLTP) systems. Its performance shines when querying large, relatively flat (denormalized) tables with high-throughput batch inserts.
This makes ClickHouse and Iceberg highly complementary. Iceberg provides the robust, reliable, and transactional storage layer capable of handling updates, deletes, and complex data evolution. ClickHouse, with its specialized architecture, serves as the perfect high-performance query and serving layer on top of this prepared data. This synergy allows architects to leverage the strengths of each technology: Iceberg for data management and reliability, and ClickHouse for unparalleled query speed.
Combining Iceberg and ClickHouse
Integrating Apache Iceberg as the storage foundation and ClickHouse as the query engine creates a powerful and flexible lake house architecture. The most common and effective implementation follows a layered approach, treating Iceberg as the system of record and ClickHouse as a high-performance access layer.
Hot/Cold Layered Architecture
his pattern designates the data lake as the comprehensive, long-term storage layer and ClickHouse as a specialized, performance-oriented layer for active querying.
Iceberg as the "Cold" Layer / Source of Truth: In this model, the Iceberg tables residing on Amazon S3 serve as the single, durable source of truth for all analytical data. This layer is cost-effective and designed for massive scale, holding the complete history of the data. All data transformation and enrichment processes write their final output to these Iceberg tables.
ClickHouse as the "Hot" Layer: ClickHouse provides the interactive query capabilities. This interaction can take two primary forms, depending on the performance requirements:
Federated Queries (Querying in Place): ClickHouse can query data directly from the Iceberg tables on S3 without ingesting it. This is ideal for ad-hoc exploratory analysis or for dashboards that can tolerate query latencies of a few seconds to minutes. The primary advantage is that it avoids data duplication and the complexity of an ingestion pipeline, allowing analysts to query the entire dataset on demand.
Data Ingestion (for Maximum Performance): For use cases that demand sub-second query latency and high concurrency, such as user-facing dashboards or real-time applications, a subset of the data is ingested from the Iceberg tables into ClickHouse's native MergeTree tables. This approach leverages ClickHouse's internal storage and processing optimizations to deliver the absolute best performance. The trade-off is the introduction of data duplication and the need for a pipeline to keep the data in ClickHouse synchronized with the source of truth in Iceberg.
Alternative Pattern: The ClickStack Model and its Data Lake Limitations
While the hot/cold architecture is ideal for a flexible lakehouse, another common pattern, particularly in the observability space, is direct ingestion into ClickHouse. This approach is exemplified by ClickStack, an open-source observability platform that unifies logs, metrics, and traces in a single ClickHouse database. ClickStack uses an OpenTelemetry (OTel) collector to ingest all telemetry data as "wide, rich events" directly into ClickHouse, leveraging its performance for high-cardinality data analysis.
However, this direct-to-ClickHouse model presents significant challenges for a general-purpose data lake strategy:
It Bypasses the Data Lake: The core principle of ClickStack is to treat ClickHouse as the primary, all-in-one data store. This architecture intentionally circumvents a data lake and open table formats like Iceberg, creating a data silo optimized for a single purpose (observability).
Proprietary Storage Format: Data is stored in ClickHouse's native MergeTree format, not an open standard. This limits the ability to use other query engines or tools directly on the data, which contradicts the fundamental benefit of a data lakehouse: a single, open source of truth accessible by multiple, best-in-class engines.
Ingestion of Raw, Unclean Data: Direct ingestion pipelines, whether through ClickStack's collector, the native Kafka engine, or ClickPipes, send raw data streams directly into ClickHouse. This forces ClickHouse to handle complex and resource-intensive streaming challenges like data deduplication. ClickHouse's internal tools for this, such as the
ReplacingMergeTreeengine, perform deduplication during an uncontrollable background merge process. This means queries can return incorrect results until the merge completes, making it unsuitable for real-time accuracy.
To ensure a clean, reliable stream of data for real-time analytics, a dedicated transformation layer is needed. Tools like GlassFlow are designed to solve this problem by processing the data stream before it reaches ClickHouse. GlassFlow provides real-time, stateful deduplication and joins, ensuring that only clean, validated, and ready-to-query data is ingested. This upstream processing significantly reduces the load on ClickHouse and guarantees the accuracy of real-time queries.
Technical Integration and Current Limitations
The integration between ClickHouse and Iceberg is rapidly evolving, but it is important to understand its current state.
Mature Read Support: The primary and most stable form of integration is read-only access. ClickHouse provides dedicated table functions (
icebergS3,icebergHDFS, etc.) and a correspondingIcebergtable engine that allow it to query data from existing Iceberg tables. Crucially, ClickHouse can leverage Iceberg's metadata to perform partition pruning, which is essential for achieving good query performance by skipping irrelevant data files. It also supports some schema evolution and time travel queries.Emerging Write Support: The ability for ClickHouse to write data directly to Iceberg tables is a recent and still experimental feature. While this development is significant for future architectural simplification, as of early 2025, it primarily supports
INSERToperations and lacks robust support for updates or deletes. It is not yet considered production-ready for all use cases.
This key limitation—the immaturity of native write support—is what defines the central challenge of this architecture today. Because ClickHouse cannot reliably perform the complex transformations needed to create curated Iceberg tables, this critical task must be delegated to a more mature external processing engine. ClickHouse currently serves as the consumer of well-structured Iceberg data, not the producer. This necessitates a deep dive into the tools and methods for performing that transformation.
The Core Challenge: Transforming Raw Data in the LakeHouse
The ultimate goal of the transformation layer is to convert the raw, heterogeneous files residing in the data lake into clean, structured, partitioned, and optimized Iceberg tables. This prepared data is then ready for high-speed analytical queries from ClickHouse or other engines. This transformation process can be approached in two primary ways: batch processing or stream processing.
Batch Transformation: The Reliable Workhorse
In a batch transformation, data is processed in large, discrete chunks on a recurring schedule, such as hourly or daily. A scheduled job spins up, reads a large volume of raw data collected over the preceding period, applies a series of transformations (such as cleaning, joining, filtering, and aggregation), and writes the fina, structured output to a target Iceberg table.
There are some challenges
Challenges of Batch Transformation:
High Latency: The most significant drawback of batch processing is the inherent delay. Business insights are only as fresh as the last completed batch run. For a daily job, the data can be up to 24 hours old, which is unacceptable for real-time use cases like fraud detection or operational monitoring.
Resource Spikes: Batch jobs are often resource-intensive, requiring large compute clusters to process massive data volumes in a short time. These expensive resources may sit idle for long periods between job runs, leading to inefficient resource utilization.
Inefficient Reprocessing: When business logic changes or errors are discovered in the source data, entire large batches may need to be reprocessed from scratch. This is a slow, computationally expensive, and operationally burdensome process.
Streaming Transformation: The Real-Time Imperative
In a streaming transformation model, data is processed continuously as it arrives, either event-by-event or in very small "micro-batches" spanning a few seconds. Transformations are applied on the fly, and the results are written to the target Iceberg tables in near real-time, providing data freshness measured in seconds or minutes.
Challenges of Streaming Transformation:
Architectural Complexity: Streaming systems are fundamentally more complex to design, deploy, and maintain than their batch counterparts. They require specialized tools and expertise in distributed systems to ensure reliability and fault tolerance.
State Management: This is arguably the most difficult technical challenge in stream processing. Many useful transformations are stateful—that is, the processing of a current event depends on information from past events. Examples include calculating a running total, aggregating events within a user session, or detecting patterns across a sequence of events. The processing engine must maintain this "state" reliably. For instance, if a node calculating a running count of user clicks fails, the system must be able to recover that count precisely without data loss. Managing this state consistently and performantly across a distributed cluster is a complex engineering problem.
Late-Arriving and Out-of-Order Data: In distributed data pipelines, events are not guaranteed to arrive at the processing engine in the order they were generated. Network latency or source system delays can cause data to be out of order or to arrive "late." A streaming job that aggregates data into five-minute windows must have a robust strategy for handling an event from the 10:00-10:05 window that arrives at 10:07, after the result for that window has already been calculated and written. This requires sophisticated mechanisms like "watermarking" to track the progress of event time and define when a window can be considered complete.
The choice between batch and streaming has profound implications that extend beyond the processing layer and directly impact the physical structure of the data lake. Streaming ingestion, particularly with low-latency requirements, often involves writing data frequently in small increments. This can lead to the "small file problem," where a data lake table becomes composed of thousands or even millions of small files. Query engines, including those working with Iceberg, perform poorly in such scenarios due to the high overhead of opening many files and processing extensive metadata.
Consequently, adopting a streaming transformation strategy necessitates a parallel commitment to a data compaction strategy. Compaction is a maintenance process that periodically runs in the background to merge many small data files into fewer, larger ones, which are optimal for query performance. While Iceberg provides the mechanisms to perform compaction safely, it represents an additional operational burden—a "compaction tax"—that must be managed and paid. This ripple effect on storage management is a critical, and often underestimated, consequence of choosing a real-time streaming architecture.
A Comparative Analysis of Data Transformation Solutions
Selecting the right tool to perform data transformation and write to Iceberg tables is critical. The choice is typically a trade-off between the desired processing model, latency requirements, and developer experience. The three most common solutions in this ecosystem are Apache Spark, GlassFlow, and dbt.
Apache Spark: The Versatile Generalist
Processing Model: Apache Spark is fundamentally a batch processing engine renowned for its performance and scalability. However, its Structured Streaming API provides a powerful micro-batch streaming capability. Instead of processing event-by-event, it processes data in continuous, small batches, offering near-real-time latency that is sufficient for many use cases.
Iceberg Integration: The integration between Spark and Iceberg is exceptionally mature and robust. Spark is often considered the reference implementation for new Iceberg features. It provides comprehensive support for creating, reading, updating, deleting, and managing Iceberg tables through both its DataFrame API and Spark SQL extensions.
Use Cases: Spark is the de facto standard for large-scale batch ETL workloads. It is the ideal choice for transforming raw data into daily or hourly aggregated Iceberg tables. Its Structured Streaming API is well-suited for near-real-time pipelines where latencies of a few seconds to several minutes are acceptable.
GlassFlow: The Python-Native Streaming ETL Service
Processing Model: GlassFlow is a serverless, event-driven platform designed for real-time stream processing. It allows developers to define transformation logic using standard Python functions, which GlassFlow then executes on its managed, auto-scaling infrastructure for every event. It is a true streaming engine that handles stateful operations like deduplication and temporal joins over configurable time windows, and it is designed to correctly process late-arriving events.
Iceberg Integration: GlassFlow's primary and most optimized integration path is with Apache Kafka as a source and ClickHouse as a sink. It does not currently offer a native, managed sink connector for writing directly to Apache Iceberg tables. However, its serverless Python environment is flexible; developers can use its Python SDK to integrate with any data destination, which would include using a library like PyIceberg to programmatically write transformed data to Iceberg tables. This approach positions GlassFlow as a transformation layer rather than a direct-to-Iceberg ingestion tool.
Key Differentiator: GlassFlow's main advantage is its developer-centric, Python-native approach that abstracts away the operational complexity of managing Flink or Spark clusters. It is purpose-built to simplify real-time ETL, especially for Kafka-to-ClickHouse pipelines, by offering built-in, one-click deduplication and temporal joins. This significantly reduces the processing load on the destination database.
Use Cases: GlassFlow is best suited for teams that want to build and deploy real-time transformation pipelines quickly using Python, without the overhead of managing distributed systems. It excels in use cases like real-time analytics, IoT, and behavioral tracking, particularly when the data pipeline involves Kafka and ClickHouse.
dbt (Data Build Tool): The Analytics Engineering Orchestrator
Processing Model: It is crucial to understand that dbt does not process data itself. It is a transformation workflow tool. dbt allows data teams to define transformations as SQL
SELECTstatements (called "models"). It then compiles this SQL and runs it against a target data processing engine. In the context of a data lake, dbt would be used in conjunction with an engine like Spark (via thedbt-sparkadapter).Iceberg Integration: When used with a compatible engine, dbt can be configured to materialize its models as Iceberg tables. This is typically done by setting the
file_formattoicebergin the model's configuration block, and dbt handles the underlyingCREATE TABLE ASorINSERT OVERWRITEstatements.Key Differentiator: dbt's value is not in data processing but in bringing software engineering best practices to the transformation workflow. It enables version control (Git), modularity, automated testing, documentation, and dependency management for complex SQL-based transformation pipelines.
Use Cases: dbt is not a replacement for Spark or Flink but a powerful orchestration and development layer that sits on top of them. It is the ideal tool for building, managing, and maintaining reliable, testable, and version-controlled batch transformation pipelines that are executed by Spark to populate a series of curated Iceberg tables.
Comparison of Data Transformation Tools for Iceberg
The following table provides a concise summary to help guide the selection of the appropriate tool for a given transformation task.
Feature | Apache Spark | GlassFlow | dbt (with Spark) |
|---|---|---|---|
Primary Model | Batch & Micro-Batch Streaming | Python-native, Serverless Streaming ETL | SQL-based Batch Orchestration |
Typical Latency | Seconds to Hours | Milliseconds to Seconds | Minutes to Hours |
State Management | Good; improving with new APIs. | Built-in for deduplication and temporal joins | N/A (Delegated to execution engine) |
Handling Late Data | Supported via watermarking, but can be complex. | Handled automatically within its processing model. | N/A (Batch model assumes data is complete for the period) |
Primary Use Case w/ Iceberg | Large-scale batch ETL; near-real-time pipelines. | Real-time transformation in Python, primarily for Kafka-to-ClickHouse pipelines; custom Iceberg integration possible via SDK. | Building, testing, and managing complex, version-controlled batch transformation pipelines. |
Developer Experience | Code-heavy (Scala, Python, SQL). Requires cluster management. | Python-centric, serverless. Focus on business logic in Python functions. | SQL-centric. Focus on business logic over infrastructure. |
The Future of Real-Time Data Transformation
The architecture combining data lakes, Apache Iceberg, and high-speed query engines like ClickHouse is a leading example of the "data lakehouse"—a unified paradigm that merges the flexibility and low cost of data lakes with the performance and reliability of data warehouses. The future of this ecosystem is focused on making this powerful architecture simpler, more integrated, and more real-time by default.
Trend 1: Unification and Simplification: The current necessity of using a separate engine like Spark or Flink to write to Iceberg before ClickHouse can read it adds a layer of architectural complexity. A major trend is the push for more query engines to gain robust, native write support for open table formats. As ClickHouse's experimental write support for Iceberg matures, it will simplify many architectures by potentially eliminating the need for an intermediate processing engine for less complex transformation tasks.
Trend 2: Real-Time as the Default: As the tools and integrations for stream processing mature, the technical barriers to implementation will continue to lower. This will accelerate the shift from batch-first to streaming-first data architectures, where real-time data availability is the standard expectation, not a premium feature. Open table formats like Iceberg are critical enablers of this shift, as they provide the necessary transactional foundation to make streaming writes to the data lake reliable and safe.
Trend 3: The Rise of Catalogs as the Control Plane: In a multi-engine environment where Spark, Flink, and ClickHouse all interact with the same Iceberg tables, the role of the Iceberg Catalog (e.g., AWS Glue Data Catalog, Project Nessie, or open REST Catalogs) becomes paramount. These catalogs are evolving beyond simple pointers to table metadata. They are becoming the central control plane for the entire lakehouse, responsible for providing not just table discovery but also unified data governance, cross-engine access control, and transactional consistency.
The trajectory for real-time data transformation within the lakehouse paradigm is clear. It points toward a more open, integrated, and simplified architecture. This evolution will empower developers to focus more on building valuable data products and applications and less on the complex plumbing required to connect disparate systems. The combination of an open table format like Iceberg with a portfolio of best-in-class, interoperable engines provides a flexible and powerful foundation for the next generation of data analytics.
Conclusion
The modern demand for real-time analytics at scale has given rise to a powerful architectural pattern that leverages the distinct strengths of data lakes, Apache Iceberg, and ClickHouse. Data lakes, built on cost-effective object storage like Amazon S3, provide a scalable foundation for storing all of an organization's raw data. Apache Iceberg transforms this raw storage into a reliable and performant lakehouse by introducing an open table format with critical features like ACID transactions, schema evolution, and time travel. Finally, ClickHouse delivers the sub-second query performance required to power interactive dashboards and real-time applications on top of this data.
However, the critical link in this powerful chain is the data transformation layer. The journey from raw, unstructured files to clean, query-ready Iceberg tables presents significant technical challenges. The choice of a transformation strategy—whether the reliable but latent batch approach or the complex but immediate streaming approach—is a crucial decision. This choice, in turn, dictates the most appropriate tool for the job. Apache Spark stands out as the versatile workhorse for batch and near-real-time workloads, Apache Flink excels as the specialist for ultra-low-latency streaming, and dbt provides an essential orchestration layer for managing complex batch transformations with software engineering discipline.
While the current architecture requires careful consideration of these components and their trade-offs, the ecosystem is evolving rapidly. The ongoing maturation of the lakehouse paradigm promises a future with more tightly integrated, simpler, and more powerful tools. The combination of open standards and best-in-class specialized engines is paving the way for a new era where building real-time, data-driven applications is more accessible and impactful than ever before.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
