Docs
Managed
Contact
About
Blog
Open Source
Cleaned
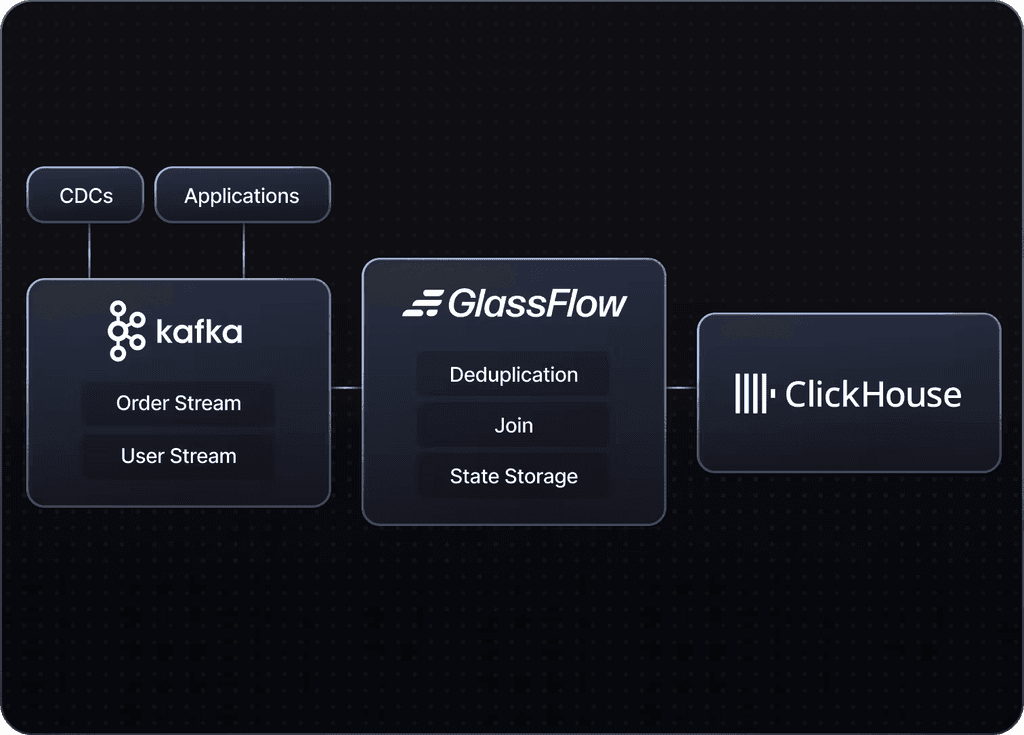
Kafka Streams for ClickHouse
Clean Data. No maintenance. Less load for ClickHouse.

What Sets It Apart
A serverless and production-ready setup that empowers everyone in your data team to build and transform event-driven data pipelines.
Python for everyone
End-to-end native Python for your pipelines. Forget the Python wrappers and use any Py library you want.
Build in mins
Only focus on your needed transformations and functions. With our connectors, templates and code snippets you don't need to start from scratch.
Zero Infrastructure
We do the heavy lifting for you. We take care of maintenance, scalability, and making sure it is robust. Completely managed by us.
A serverless and production-ready setup that empowers everyone in your data team to build and transform event-driven data pipelines.

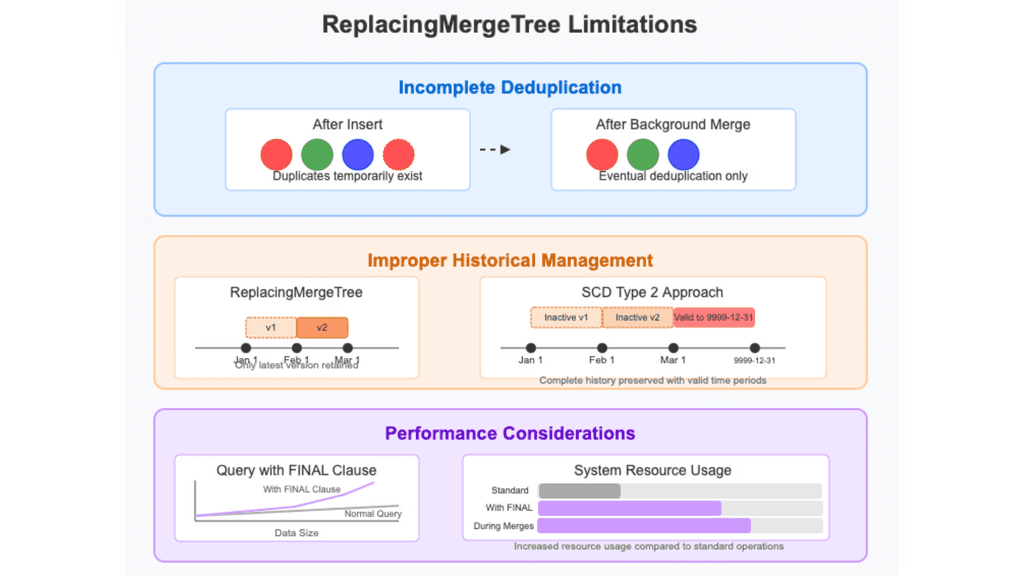
Deduplication with one click.
Select the columns as primary keys and enjoy a fully managed processing without the need to tune memory or state management.

7 days deduplication checks.
Auto detection of duplicates within 7 days after setup to ensure your data is always clean and storage is not exhausted.
Batch Ingestions built for ClickHouse.
Select from ingestion logics like auto, size based or time window based.
Joins, simplified.
Define the fields of the streams that you would like to join and GlassFlow handles execution and state management automatically.

Stateful Processing.
Built-in lightweight state store enables low-latency, in-memory deduplication and joins with context retention within the selected time window.

Managed Kafka and ClickHouse Connector.
Built and updated by GlassFlow team. Data inserts with a declared schema and schemaless.
Auto Scaling of Workers.
Our Kafka connector will trigger based on partitions new workers and make sure that execution runs efficient.
Why You Will Love It
A serverless, production-ready setup for building and transforming event-driven data pipelines, with support for APIs and Webhooks.
Simple Pipeline
With GlassFlow, you remove workarounds or hacks that would have meant countless hours of setup, unpredictable maintenance, and debugging nightmares. With managed connectors and a serverless engine, it offers a clean, low-maintenance architecture that is easy to deploy and scales effortlessly.

Accurate Data Without Effort
You will go from 0 to a full setup in no time! You get connectors that retry data blocks automatically, stateful storage, and take care of late-arriving events built in. This ensures that your data ingested into ClickHouse is clean and immediately correct.
Less load for ClickHouse
Because of removing duplicates and executing joins before ingesting to ClickHouse, it reduces the need for expensive operations like FINAL or JOINs within ClickHouse. This lowers storage costs, improves query performance, and ensures ClickHouse only handles clean, optimized data instead of redundant or unprocessed streams.

Learn More About ClickHouse Optimization
Clickhouse
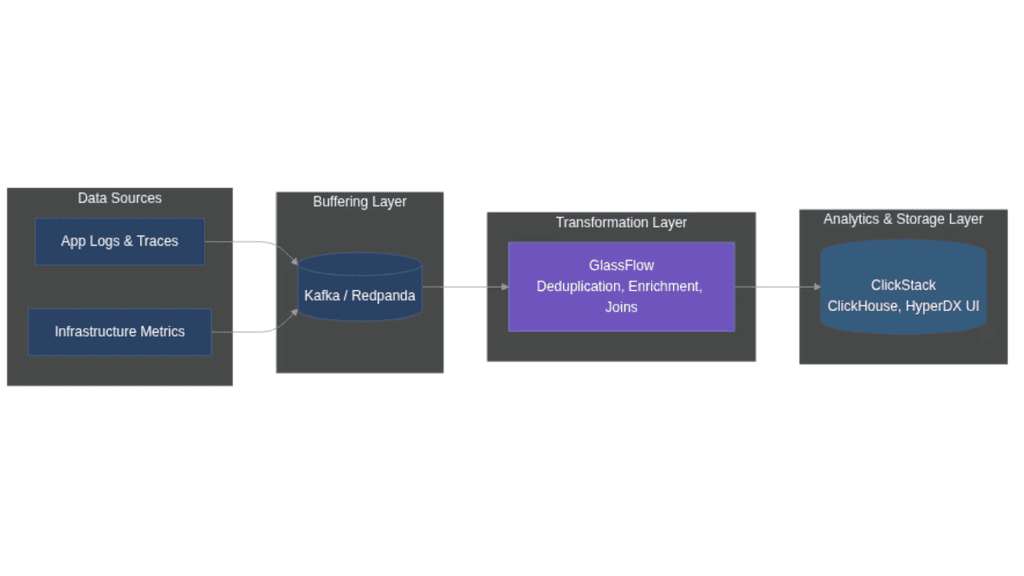
Building a Next-Gen Observability Stack with ClickStack and GlassFlow
Open source observability with ClickStack and GlassFlow.
Written by
Armend Avdijaj
Clickhouse
Building a Next-Gen Observability Stack with ClickStack and GlassFlow
Open source observability with ClickStack and GlassFlow.
Written by
Armend Avdijaj
Clickhouse
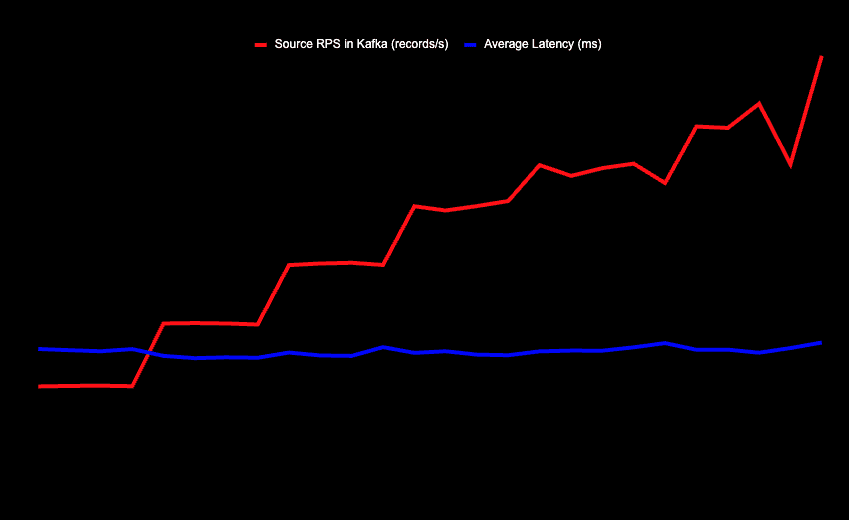
Load Test GlassFlow for ClickHouse: Real-Time Deduplication at Scale
Benchmarking GlassFlow: Fast, reliable deduplication at 20M events
Written by
Ashish Bagri
Frequently asked questions
Feel free to contact us if you have any questions after reviewing our FAQs.



Cleaned Kafka Streams for ClickHouse
Clean Data. No maintenance. Less load for ClickHouse.

