ljn
ClickHouse Learnings
Speed up ClickHouse queries using keys, indexes, dedup & JOIN optimization
Written by
Armend Avdijaj
-

“ClickHouse is one of the fastest analytical databases available, and much of that speed comes from avoiding unnecessary work. The less data it scans and processes, the faster queries run.”
The line, taken from this blog aptly states why ClickHouse is this popular in just one line! Let’s try to puts these words into a very simple visualization:
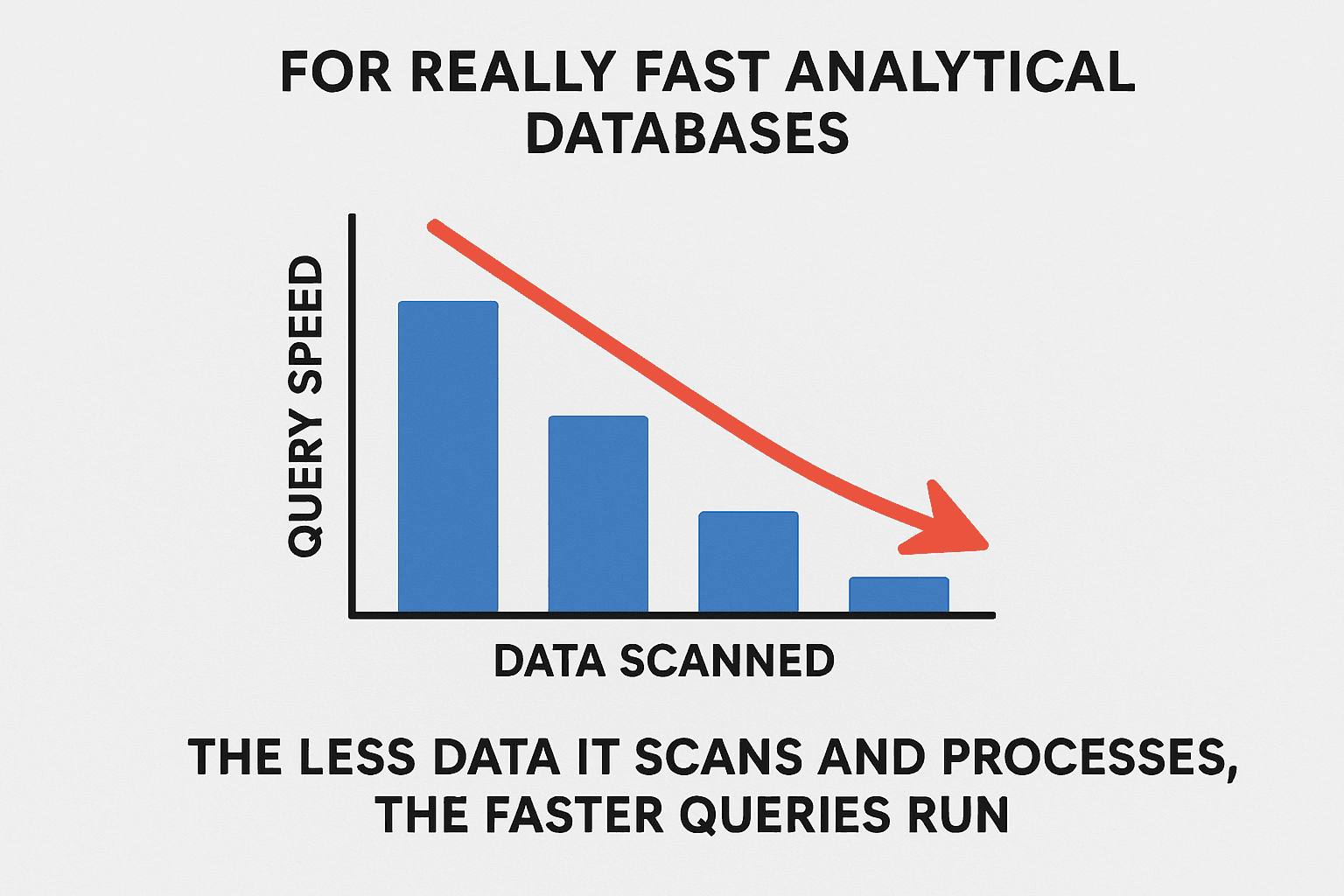
Figure 1. Blog Idea visualized!
Now, the question is, how to achieve this?
Well! Query Optimization is key when working with huge datasets with hundreds or even thousands of columns. The query processing time increases extensively as the data that the system needs to go through increases. So, that is where ClickHouse shines. It has state of the art optimization techniques implemented which makes it one of the fastest analytical databases in the market.
So, let’s deep dive into the various optimizations which ClickHouse employs and also add a little surprise to it at the very end (believe me, it’s worth it!).
How ClickHouse Optimizes Queries?
You will find some really interesting articles by ClickHouse which will help you understand how it optimizes large scale data queries. Here are some of the blogs I really liked:
A simple guide to ClickHouse query optimization: part 1
Performance and Optimizations | ClickHouse Docs
Understanding Query Processing
Before we dive into the various optimization techniques, it is really important to first understand what queries actually need optimizing. It is no use to implement complex optimization techniques when they are not needed. Here, ClickHouse helps by providing enriched logs for each query execution, which can be found in tables like query_duration_ms and query_log table.
Moreover, if you are on ClickHouse Cloud, you even get an intuitive user interface for this.
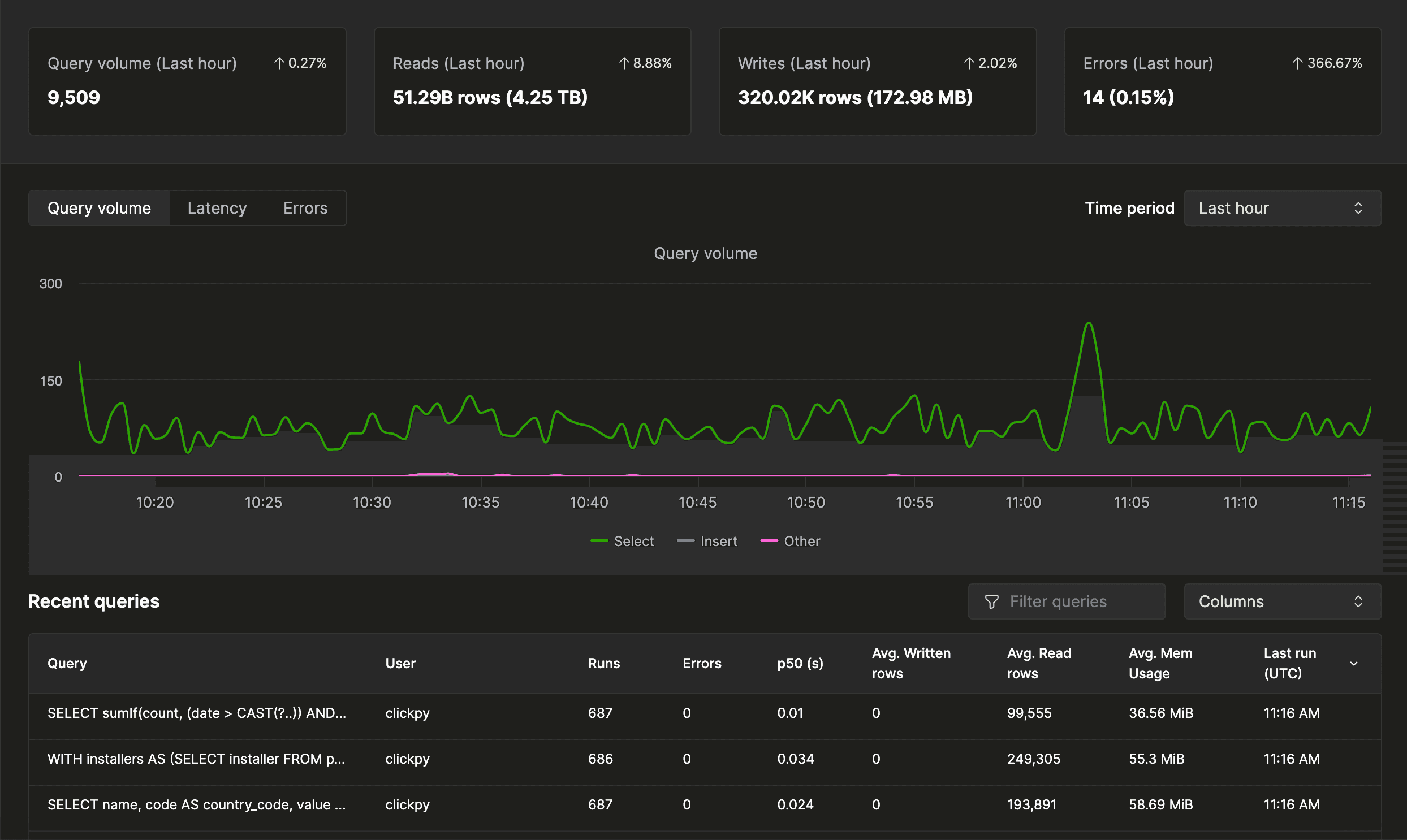
Figure 2. Query Insight on ClickHouse Cloud (Reference)
Apart from this, you can even use the EXPLAIN statement to further understand the query processing plan and the actual steps that will be followed to get the results. Something like this:
Perfect! We now know how to detect challenging queries. Next, let’s see how ClickHouse improves them.
ClickHouse Query Optimization Techniques
1. Fundamental Optimization Techniques
Like any database, there are very simple yet intuitive measures that can significantly help with query performance. Here are some approaches you can use in ClickHouse:
Avoid Nullable: ClickHouse recommends to avoid nullable columns as it increases the overhead on it’s end (they need to track an additional column). Good news is: you can easily handle NULL values in GlassFlow’s Python pipeline pre-ingestion to avoid this hassle.
Choosing the Right Data Type: Always choose the best datatype. Check your column values and select wisely: using uint64 instead of uint8 can make a huge difference! Moreover, you can use ClickHouse specific data types like Low Cardinality (it employs dictionary coding) for even faster performance.
Choose Primary and Sort Keys Wisely: This is a very simple yet one of the most important techniques for query optimization. Your Primary/Partition Key will be the one on which your data will be divided into sets. So, choosing a really good partitioning key is paramount. Moreover, your sort keys will be used to sort the data in a particular order. So, if your system requires the latest data, it makes sense to sort it descending on the main timestamp columns so that when you query the latest information, there is less table scanning.
Running Queries Parallely!: Yes, you read it correctly; ClickHouse offers this feature using something called processing lanes. It basically uses the primary key and aggregation queries to process the data in parallel. Here is a intuitive visualization from the main article to showcase how this works:
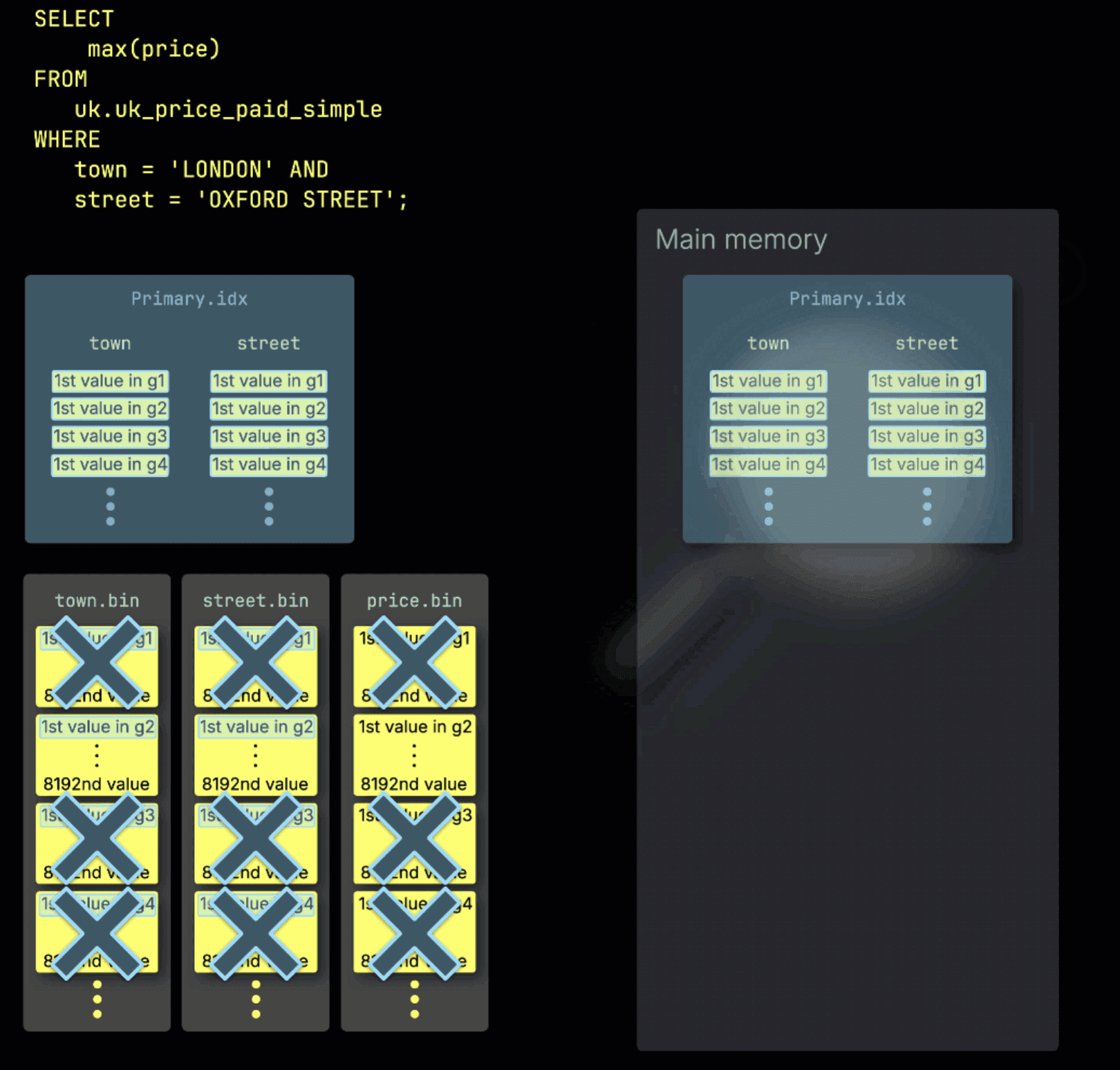
Figure 3. How can you run Queries in Parallel? (https://clickhouse.com/docs/optimize/query-parallelism)
Skip Indexes (Block-Level Shortcuts): ClickHouse doesn't use traditional row-based secondary indexes like B-trees. Instead, it employs skip indexes, which store lightweight metadata about data blocks (granules), such as min/max values, value sets, or Bloom filters, to skip scanning irrelevant chunks entirely. This significantly reduces the amount of data read during queries—especially when filters don’t align well with the primary key. For full details, check out the official docs: Understanding ClickHouse Data Skipping Indexes.
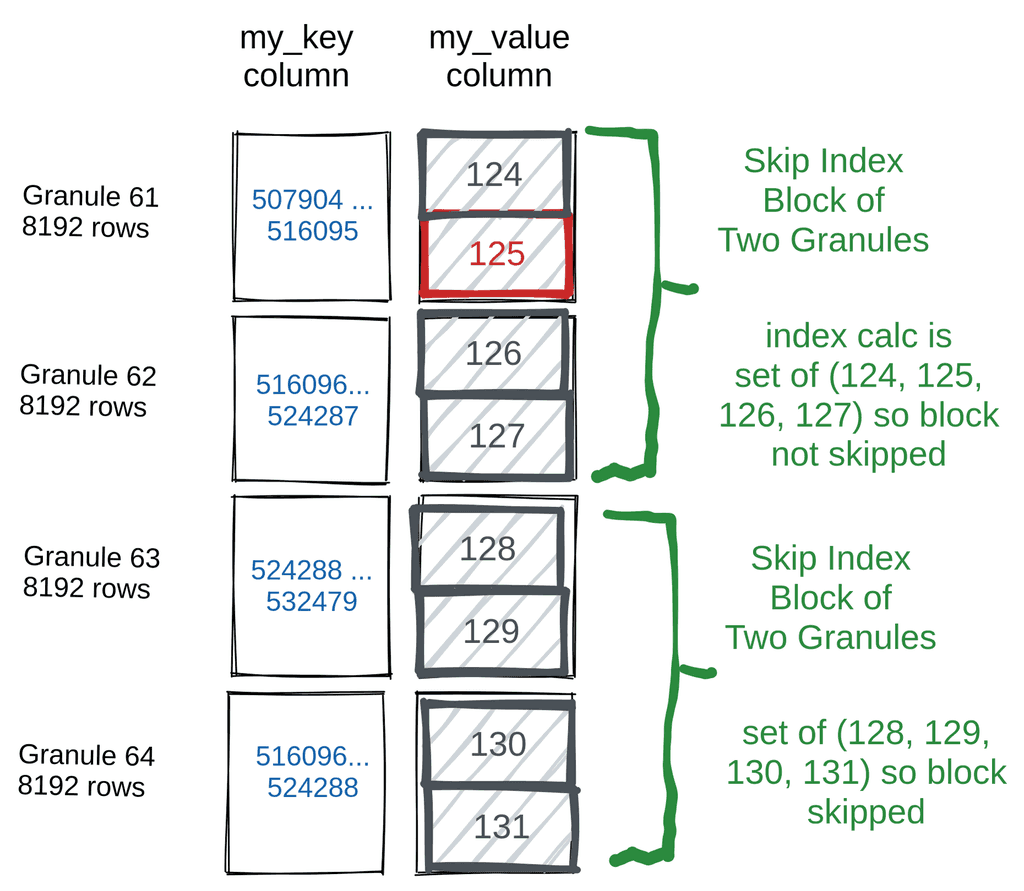
Figure 4. The Logic behind Skip Indexes
Avoid Duplicate Data at all Costs: When dealing with large scale streaming data, getting consistent deduplicated data from Kafka streams is quite difficult (exactly once behaviour is not feasible at this scale). So, there has to be a way to deduplicate the data to avoid excessive scans and wrong/inaccurate query results.
Good news is that ClickHouse already has the feature of Asynchronous inserts to handle this. In fact, they have a dedicated table engine for this. However, this is not the best way as it provides eventually deduplicated data, which needs to be taken into consideration when creating queries for such data sources.
The measures can include things like using FINAL for immediate dedup (which is not ideal, more on this later) or taking the fact into consideration while designing the pipelines. However, there is another and much easier alternative: use GlassFlow for this! It allows you to deduplicate data at scale before it hits ClickHouse, guaranteeing exactly one entry for each primary key combination. Know more about this here.
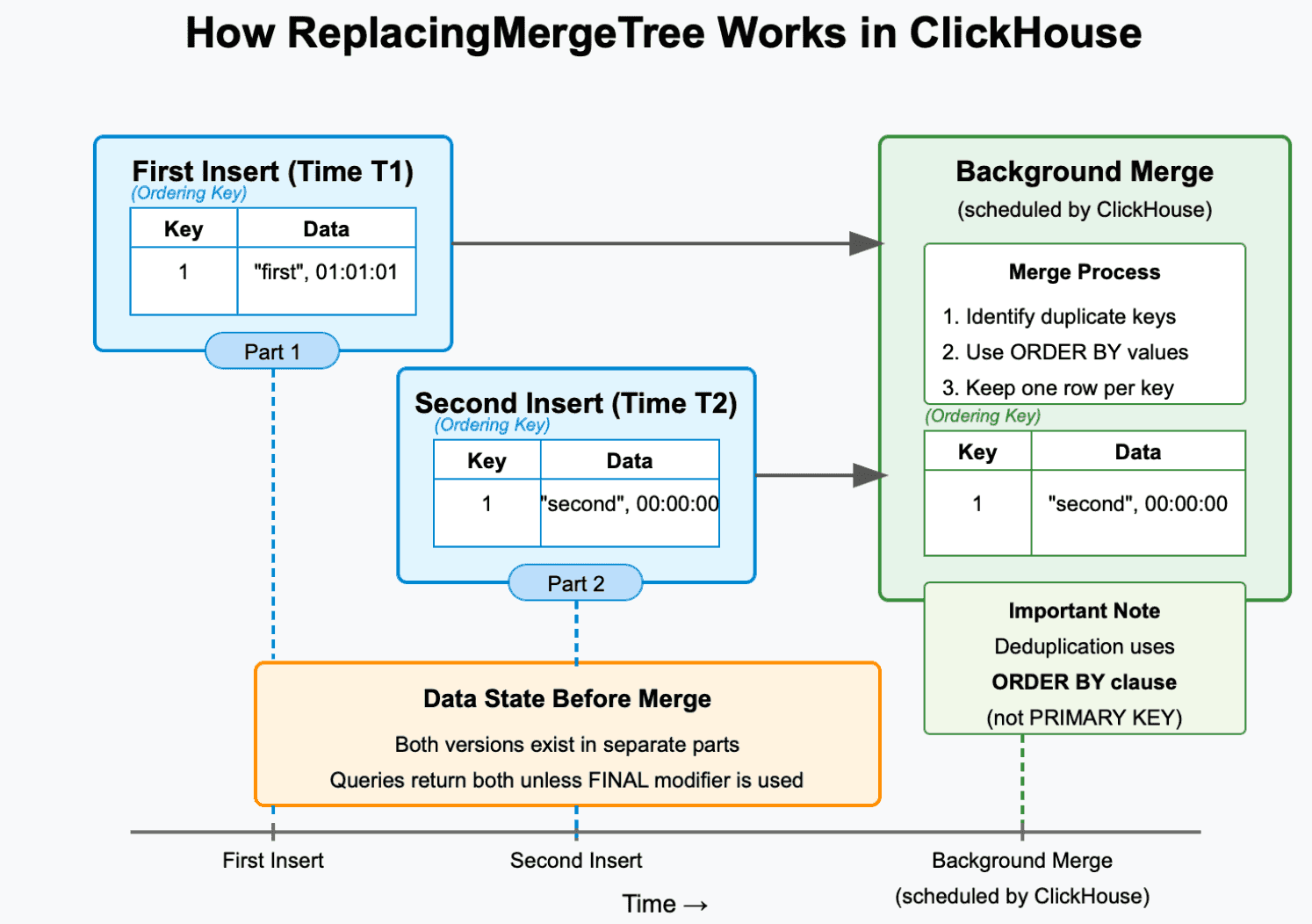
Figure 5. How ReplaceMergeTree Engine works?
Avoid Optimize Final : It’s that simple: just avoid using it in ClickHouse. It is a very expensive operation, specially when run on a huge dataset. It involves the following flow: Decompress Data → Merge → Compress → Storage. Imagine you have this for almost all the queries in your pipeline; that is so much overhead for ClickHouse. Good news is that you can easily avoid this by using GlassFlow as deduplicating data with it will ensure you don’t need this.
JOINs are very Expensive: ClickHouse is primarily for analytical databases. So, it always recommends using denormalized tables for maximum performance instead of normalized tables which need JOINs (more on this here) and is built with that in mind. So, if you have JOINs in your queries, that can be a very expensive operation. That being said, it does support that and has some really intuitive join algorithms that can help. More on this here.
However, a better solution would of course be to have already joined data in ClickHouse. But, setting up big-data join pipelines can be a hassle. So, what’s the solution? Easy, it’s GlassFlow, yet again! You can easily define a fully functional, scalable streaming join pipeline in minutes! Want to know more? Take a look at this article for more information.
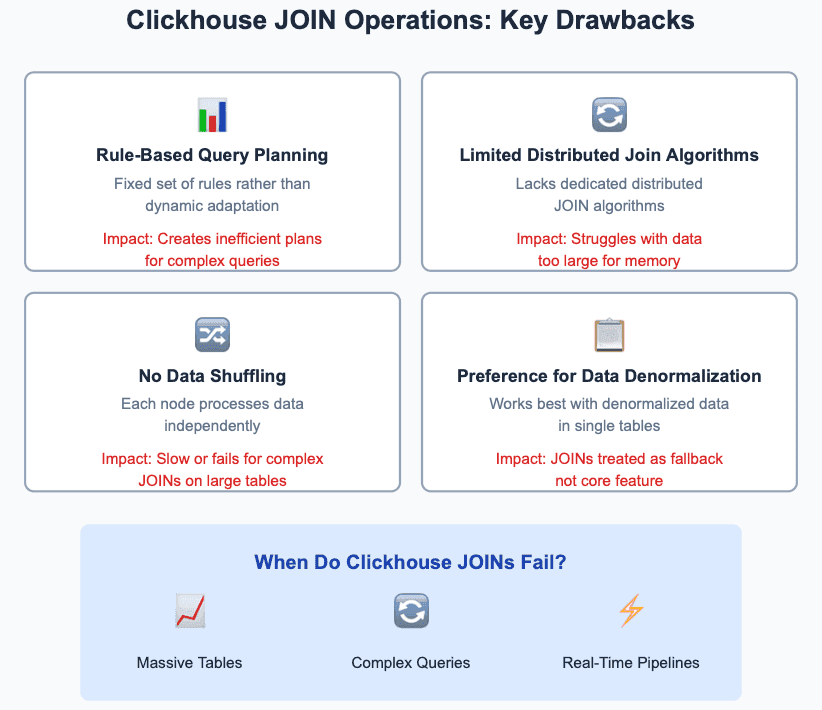
Figure 6. Why ClickHouse Struggles with JOINs?
Query Caching: Last but not the least, there is also a unique solution that ClickHouse offers: Query Caching. This allows ClickHouse to cache the results of frequently executed SELECT queries, which can greatly boost the performance.
But, you have to be wary when using this for frequently changing data. If that is the case, this can lead to usage of stale results and impact the accuracy of your system. It becomes paramount to understand when to use this and how to configure it.
Conclusion
We’ve just walked through a buffet of ways ClickHouse squeezes every ounce of performance from your queries—whether it’s skipping irrelevant data, running queries in parallel, caching smartly, or simply making thoughtful schema choices. The common theme? Less wasted work = faster results.
But here’s the thing: while ClickHouse brings the speed, you still need to feed it clean, well-prepared data and design queries that play to its strengths. That’s where tools like GlassFlow step in. By handling tricky problems like deduplication, JOIN pipelines, and pre-ingestion optimizations, it makes sure ClickHouse is always running at its absolute best.
Think of it this way: ClickHouse is the sports car, engineered for speed. GlassFlow is the pit crew that keeps it tuned, optimized, and race-ready. Together, they let you move at the pace your data (and your business) demands.
If you’re curious about what more you can unlock, definitely check out the GlassFlow blog for fresh ideas, real-world examples, and new tricks to keep pushing the limits of ClickHouse.
Did you like this article? Share it!
You might also like




Data transformations at TB scale for ClickHouse
Get query ready data, lower ClickHouse load, and reliable pipelines at enterprise scale.
